Pandas: Get a List of Categories or Categorical Columns
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- Pandas: Get a List of Categories or Categorical Columns
- Get a List of the Categories in a Category column in Pandas
- Getting the categorical columns in a DataFrame with _get_numeric_data()
- Checking if a specific DataFrame column is Categorical
# Pandas: Get a List of Categories or Categorical Columns
To get the categorical columns in a DataFrame:
- Call the
select_dtypes()method on theDataFrame. - Set the
include()argument to"category". - The method will return a
DataFramecontaining only the categorical columns.
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) print(df.select_dtypes(include=['category'])) print('-' * 50) print(df['name'].cat.categories)
Running the code sample produces the following output.
id name 0 a Alice 1 b Bobby 2 c Carl 3 d Dan -------------------------------------------------- Index(['Alice', 'Bobby', 'Carl', 'Dan'], dtype='object')
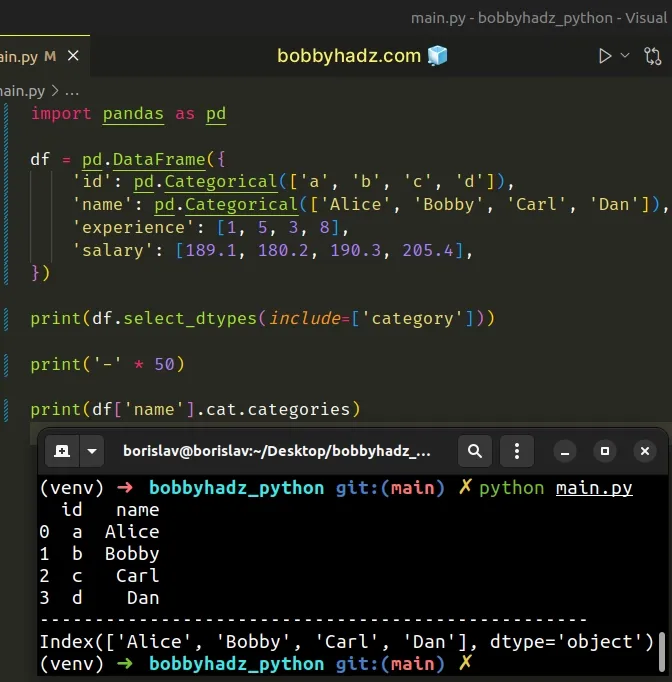
The DataFrame.select_dtypes method returns a subset of a DataFrame's columns based on the column data types.
To only select the categorical
columns, we set the include argument to "category".
# id name # 0 a Alice # 1 b Bobby # 2 c Carl # 3 d Dan print(df.select_dtypes(include=['category']))
The include argument can be set to a selection of dtypes or strings to be
included.
You can also specify multiple columns in the include list.
print(df.select_dtypes(include=['category', 'object']))
If the columns you're looking for don't get listed, try adding the object type
as shown in the code sample.
There is also an exclude argument that does the opposite.
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) # id name # 0 a Alice # 1 b Bobby # 2 c Carl # 3 d Dan print(df.select_dtypes(exclude=['number', 'bool_', 'object_']))
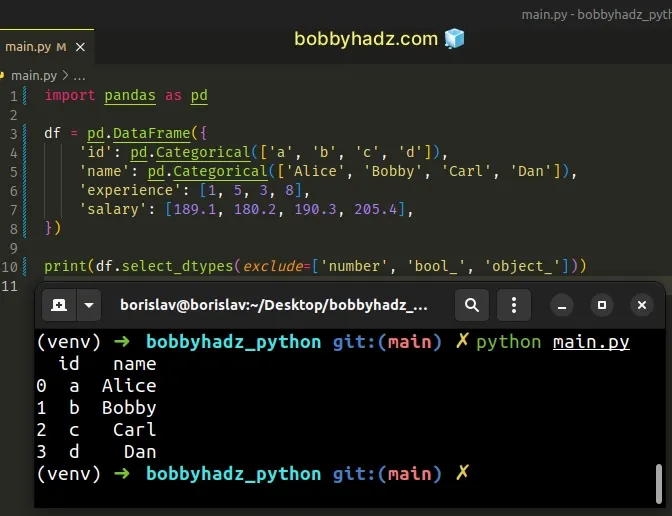
# Get a List of the Categories in a Category column in Pandas
If you need to get a list of the categories in a Category column:
- Select the category column using bracket notation.
- Access the
cat.categoriesattribute on the selected column.
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) # Index(['a', 'b', 'c', 'd'], dtype='object') print(df['id'].cat.categories) print('-' * 50) # Index(['Alice', 'Bobby', 'Carl', 'Dan'], dtype='object') print(df['name'].cat.categories)
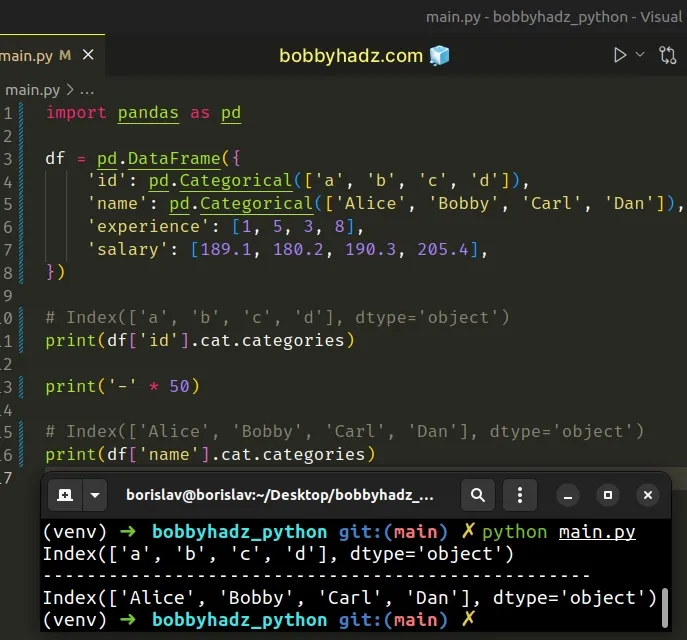
The cat.categories() method returns the categories of the given categorical column.
The method returns an Index object, so if you want to get the result as a
list, use the tolist() method.
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) # ['a', 'b', 'c', 'd'] print(df['id'].cat.categories.tolist()) print('-' * 50) # ['Alice', 'Bobby', 'Carl', 'Dan'] print(df['name'].cat.categories.tolist())
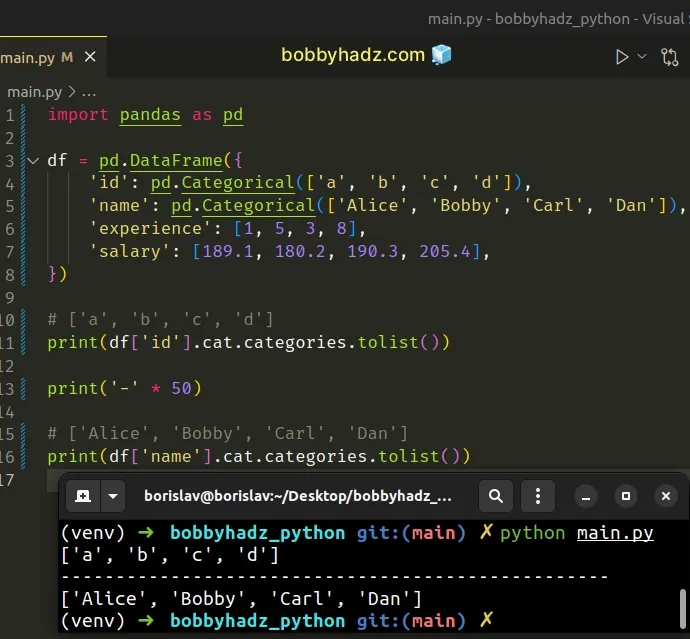
The index.tolist() method returns a list of the values in the index.
# Getting the categorical columns in a DataFrame with _get_numeric_data()
If your DataFrame doesn't have any numerical columns that are categorical, you
can also get the categorical columns using _get_numeric_data().
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) numeric_columns = df._get_numeric_data().columns # 👇️ Index(['experience', 'salary'], dtype='object') print(numeric_columns) categorical_columns = list(set(df.columns) - set(numeric_columns)) print(categorical_columns) # 👉️ ['name', 'id']
We used the _get_numeric_data() method to get all numeric columns in the
DataFrame.
The last step is to subtract the numeric columns from all of the DataFrame's columns and convert the result to a list.
We used the set() constructor to convert the index objects to Set objects to be able to use the subtraction (-) operator.
We could've achieved the same result by using the set.difference() method.
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) numeric_columns = df._get_numeric_data().columns # 👇️ Index(['experience', 'salary'], dtype='object') print(numeric_columns) categorical_columns = list(set(df.columns).difference(numeric_columns)) print(categorical_columns) # 👉️ ['name', 'id']
The
difference()
method returns a new set with elements in the set that are not in the
provided iterable.
In other words, set(list2).difference(list1) returns a new set that contains
the items in list2 that are not in list1.
# Checking if a specific DataFrame column is Categorical
If you need to check if a specific DataFrame column is categorical:
- Get the
dtypename of the column by accessing thedtype.nameattribute. - Check if the returned string is equal to
"category".
import pandas as pd df = pd.DataFrame({ 'id': pd.Categorical(['a', 'b', 'c', 'd']), 'name': pd.Categorical(['Alice', 'Bobby', 'Carl', 'Dan']), 'experience': [1, 5, 3, 8], 'salary': [189.1, 180.2, 190.3, 205.4], }) if df['name'].dtype.name == 'category': # 👇️ this runs print('The column is categorical') else: print('The column is NOT categorical')
The dtype
attribute returns a dtype object, so we can't directly compare it to the
string "category".
Instead, we accessed the name attribute on the object to get the data type
name as a string.
The last step is to compare the returned value with the string "category".
I've also written an article on how to change the type of a column to Categorical.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- TypeError: Field elements must be 2- or 3-tuples, got 1
- ValueError: Expected 2D array, got 1D array instead [Fixed]
- TypeError: ufunc 'isnan' not supported for the input types
- Convert a Row to a Column Header in a Pandas DataFrame
- Arrays used as indices must be of integer (or boolean) type
- Pandas ValueError: ('Lengths must match to compare')
- Pandas: Convert GroupBy results to Dictionary of Lists
- Reduction operation 'argmax' not allowed for this dtype
- Pandas SpecificationError: nested renamer is not supported
- Pandas: Select the Rows where two Columns are Equal
- Pandas: Find first and last non-NaN values in a DataFrame
- How to shuffle two NumPy Arrays together (in Unison)

