lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
Last updated: Apr 11, 2024
Reading time·3 min

# lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT
The scikit-learn warning "ConvergenceWarning: lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT." is shown when the lbfgs algorithm fails to converge.
To resolve the issue, increase the maximum number of iterations that are taken for the solvers to converge.
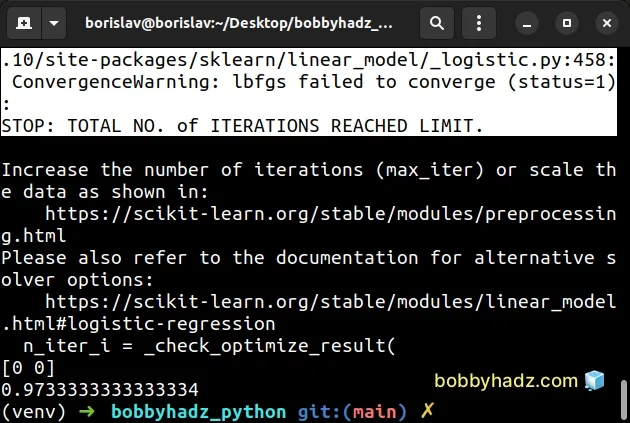
Here is an example of when the warning is shown.
from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression X, y = load_iris(return_X_y=True) clf = LogisticRegression(random_state=0).fit(X, y) print(clf.predict(X[:2, :])) clf.predict_proba(X[:2, :]) print(clf.score(X, y))
Running the code sample produces the following output.
/home/borislav/Desktop/bobbyhadz_python/venv/lib/python3.10/site-packages/sklearn/linear_model/_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT. Increase the number of iterations (max_iter) or scale the data as shown in: https://scikit-learn.org/stable/modules/preprocessing.html Please also refer to the documentation for alternative solver options: https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression n_iter_i = _check_optimize_result( [0 0] 0.9733333333333334
The warning is shown because the lbfgs algorithm fails to converge.
lbfgs stands for
Limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm.
The algorithm is one of the solvers that are used in scikit-learn.
The algorithm has better convergence on smaller datasets, however, you can often resolve the warning by increasing the maximum number of iterations that it takes for the solvers to converge.
from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression X, y = load_iris(return_X_y=True) clf = LogisticRegression(random_state=0, max_iter=1000).fit(X, y) print(clf.predict(X[:2, :])) # [0 0] clf.predict_proba(X[:2, :]) print(clf.score(X, y)) # 👉️ 0.9733333333333334
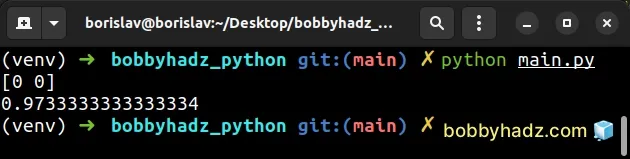
As you can see in the screenshot, the warning is no longer shown.
I simply replaced the following line:
# ⛔️ Before clf = LogisticRegression(random_state=0).fit(X, y)
With the following line:
clf = LogisticRegression(random_state=0, max_iter=1000).fit(X, y)
The max_iter keyword argument of the
LogisticRegression
class is used to set the maximum number of iterations taken for the solvers to
converge.
By default, the argument is set to 100 max iterations.
After increasing the maximum number of iterations to 1000, the warning is no longer shown.
You can play around with different values for the max_iter argument.
If a value of 1000 doesn't get the job done, try increasing the number of
maximum iterations.
clf = LogisticRegression(random_state=0, max_iter=10000).fit(X, y)
Whether this resolves the warning depends on your data.
If you got the warning when using the
LinearSVC
class, try to set the dual parameter to False.
from sklearn.svm import LinearSVC from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_classification X, y = make_classification(n_features=4, random_state=0) clf = make_pipeline( StandardScaler(), LinearSVC(random_state=0, tol=1e-5, dual=False) ) print(clf.fit(X, y))
The following line:
# ⛔️ Before clf = make_pipeline( StandardScaler(), LinearSVC(random_state=0, tol=1e-5) )
Becomes the following line:
# ✅ After clf = make_pipeline( StandardScaler(), LinearSVC(random_state=0, tol=1e-5, dual=False) )
The dual argument selects the algorithm to either solve the dual or primal
optimization problem.
It defaults to True, but you should prefer a value of False when
n_samples > n_features.
Notice that we didn't update the value of max_iter in the example.
max_iter (the maximum number of iterations to be run) defaults to 1000 when it
comes to the LinearSVC class.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a NumPy array to 0 or 1 based on threshold in Python
- How to get the length of a 2D Array in Python
- TypeError: 'numpy.ndarray' object is not callable in Python
- TypeError: Object of type ndarray is not JSON serializable
- IndexError: too many indices for array in Python [Solved]
- How to filter a JSON array in Python
- AttributeError module 'numpy' has no attribute array or int
- NumPy RuntimeWarning: divide by zero encountered in log10
- ValueError: x and y must have same first dimension, but have shapes
- SystemError: initialization of _internal failed without raising an exception
- ModuleNotFoundError: No module named 'sklearn' in Python
- Sklearn ValueError: Unknown label type: 'continuous' [Fixed]

