Pandas ValueError: cannot insert X, already exists [Solved]
Last updated: Apr 12, 2024
Reading time·4 min

# Pandas ValueError: cannot insert X, already exists [Solved]
The Pandas "ValueError: cannot insert X, already exists" occurs for 2 main reasons:
- Trying to reset a
DataFramethat has a column name that clashes with the name of the index. - Calling the
DataFrame.insert()method with a column name that already exists without settingallow_duplicatestoTrue.
# Resetting a DataFrame that has a column name that clashes with the name of the index
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) # ⛔️ ValueError: cannot insert ID, already exists df.reset_index()
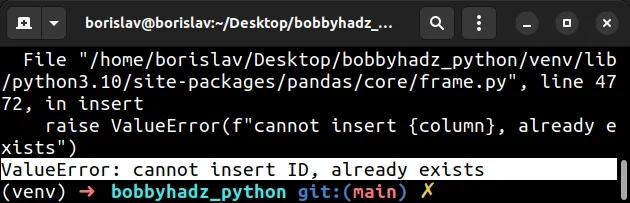
Notice that the DataFrame has an ID column and the name of its index is also
set to ID.
reset_index() method causes the error because the index name clashes with the existing column.One way to solve the error is to set the drop argument to True when calling
reset_index().
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) df = df.reset_index(drop=True) print('-' * 50) print(df)
Running the code sample produces the following output.
ID name ID 0 1 Alice 1 2 Bobby 2 3 Carl -------------------------------------------------- ID name 0 1 Alice 1 2 Bobby 2 3 Carl
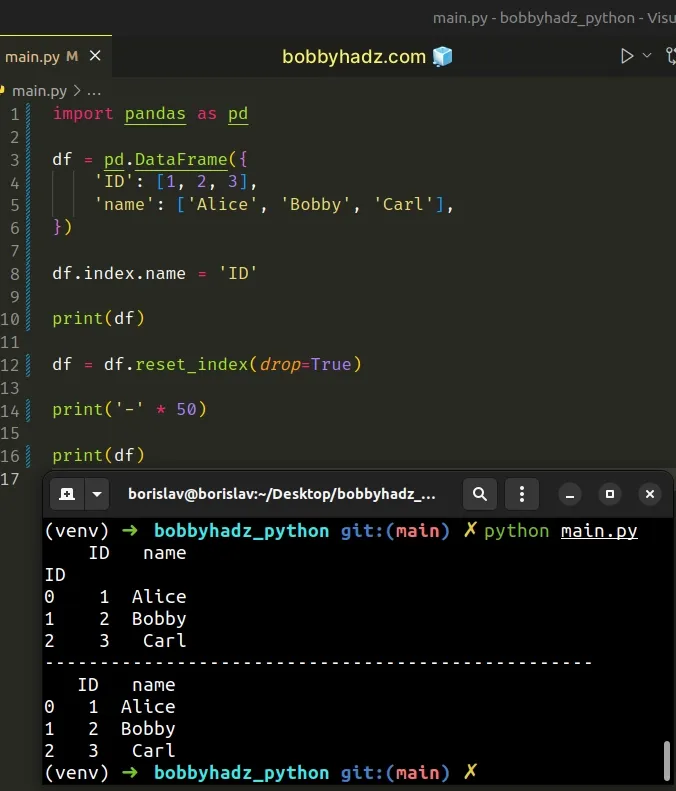
When the drop argument is set to True, the index isn't inserted into
DataFrame columns.
Instead, it is reset to the default integer index.
# Renaming the existing column to solve the error
You can also solve the error by renaming the existing column before calling
reset_index().
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) df = df.rename(columns={'ID': 'EMP_ID'}).reset_index() print('-' * 50) print(df)
Running the code sample produces the following output.
ID name ID 0 1 Alice 1 2 Bobby 2 3 Carl -------------------------------------------------- ID EMP_ID name 0 0 1 Alice 1 1 2 Bobby 2 2 3 Carl
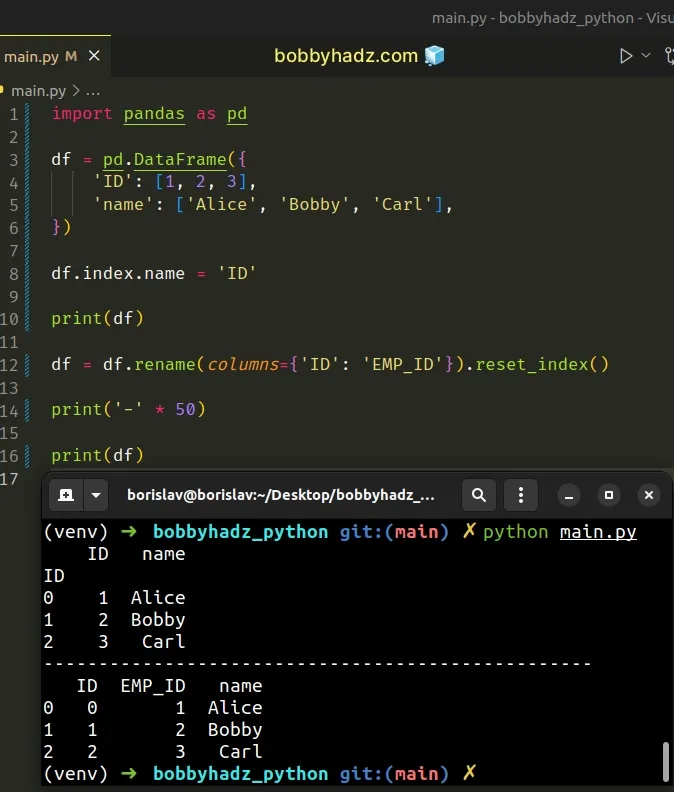
The DataFrame.rename() method is used to rename columns or index labels.
We renamed the ID column to EMP_ID before calling reset_index, so the
column name doesn't clash with the index name anymore.
# Renaming the index to solve the error
You can also rename the index to solve the error.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) df.index.name = 'IDX_ID' df = df.reset_index() print('-' * 50) print(df)
Running the code sample produces the following output.
ID name ID 0 1 Alice 1 2 Bobby 2 3 Carl -------------------------------------------------- IDX_ID ID name 0 0 1 Alice 1 1 2 Bobby 2 2 3 Carl
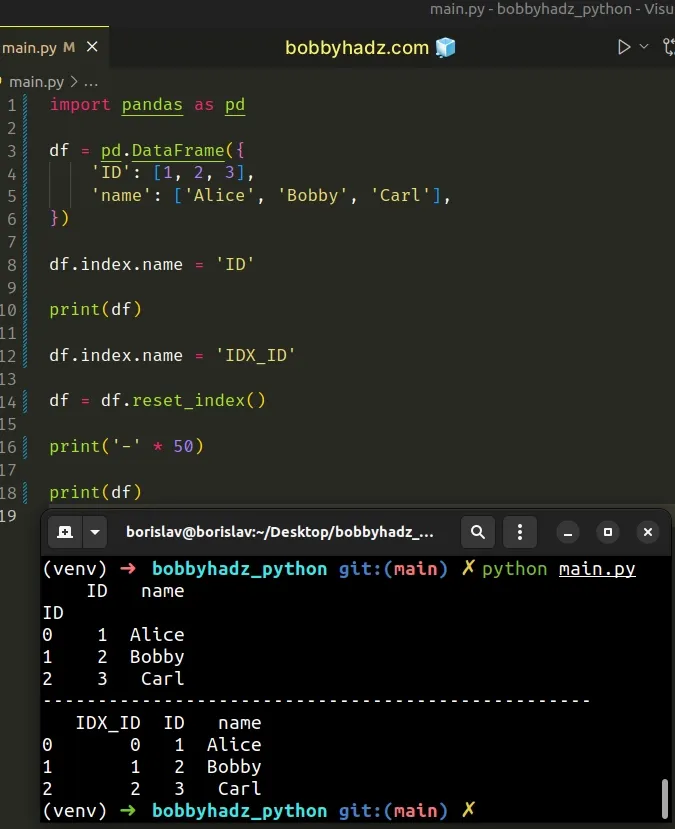
We set the index.name attribute on the DataFrame to a different value before
calling reset_index().
The column name no longer clashes with the index name, so everything works as expected.
# Using the DataFrame.rename_axis method to solve the error
You can also use the DataFrame.rename_axis() method to solve the error.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) df = df.rename_axis(index='IDX_ID').reset_index() print('-' * 50) print(df)
Running the code sample produces the following output.
ID name ID 0 1 Alice 1 2 Bobby 2 3 Carl -------------------------------------------------- IDX_ID ID name 0 0 1 Alice 1 1 2 Bobby 2 2 3 Carl
The rename_axis method sets the name of the axis for the index or columns.
You can also supply the
columns keyword
argument when calling rename_axis().
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.index.name = 'ID' print(df) df = df.rename_axis(index='IDX_ID', columns='FOO').reset_index() print('-' * 50) print(df)
Running the code sample produces the following output.
ID name ID 0 1 Alice 1 2 Bobby 2 3 Carl -------------------------------------------------- FOO IDX_ID ID name 0 0 1 Alice 1 1 2 Bobby 2 2 3 Carl
# ValueError: cannot insert X, already exists when using DataFrame.insert()
The error also occurs when you use the
DataFrame.insert
method and try to insert a column with a name that already exists in the
DataFrame.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) # ⛔ ValueError: cannot insert ID, already exists df.insert(0, 'ID', ['X', 'Y', 'Z']) print(df)
Notice that a column with the name "ID" already exists, so trying to insert a
column with the same name fails with a ValueError.
One way to get around this is to set the allow_duplicates keyword argument to
True.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.insert(0, 'ID', ['X', 'Y', 'Z'], allow_duplicates=True) # ID ID name # 0 X 1 Alice # 1 Y 2 Bobby # 2 Z 3 Carl print(df)
When the allow_duplicates argument is set to True, the insertion of columns
with duplicate names is allowed.
By default, the argument is set to False.
Alternatively, you can specify a different name for the new column.
import pandas as pd df = pd.DataFrame({ 'ID': [1, 2, 3], 'name': ['Alice', 'Bobby', 'Carl'], }) df.insert(0, 'NEW_ID', ['X', 'Y', 'Z'], allow_duplicates=True) # NEW_ID ID name # 0 X 1 Alice # 1 Y 2 Bobby # 2 Z 3 Carl print(df)
The name of the new column no longer clashes with the names of the existing columns, so the error is resolved.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a NumPy array to 0 or 1 based on threshold in Python
- How to get the length of a 2D Array in Python
- TypeError: 'numpy.ndarray' object is not callable in Python
- TypeError: Object of type ndarray is not JSON serializable
- IndexError: too many indices for array in Python [Solved]
- How to filter a JSON array in Python
- How to Multiply two or more Columns in Pandas
- Add columns of a different Length to a DataFrame in Pandas
- Pandas: Make new Column from string Slice of another Column
- Pandas: Calculate mean (average) across multiple DataFrames
- Interpolating NaN values in a NumPy Array in Python
- Numpy: How to extract a Submatrix from an array
- Pandas: Changing the column type to Categorical
- Pandas: Get a List of Categories or Categorical Columns

