Pandas: Convert entire DataFrame to numeric (int or float)
Last updated: Apr 12, 2024
Reading time·4 min

# Table of Contents
- Pandas: Convert entire DataFrame to numeric (int or float)
- Setting the errors argument if not all columns are convertible to numeric
- Setting the errors argument to coerce
# Pandas: Convert entire DataFrame to numeric (int or float)
Use the DataFrame.apply() and the pandas.to_numeric() methods to convert
an entire DataFrame to numeric.
The to_numeric() method will convert the values in the DataFrame to int or
float, depending on the supplied values.
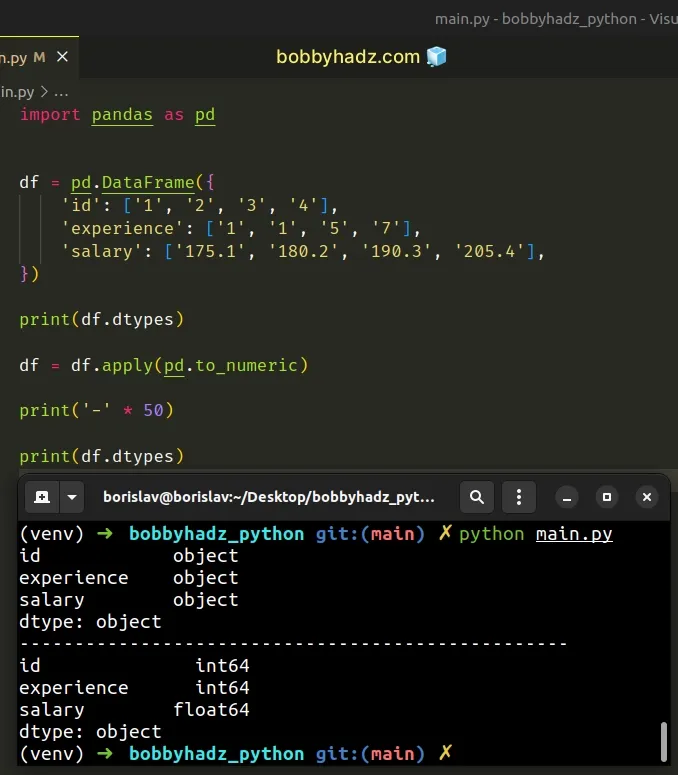
import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) print(df.dtypes) df = df.apply(pd.to_numeric) print('-' * 50) print(df.dtypes)
Running the code sample produces the following output.
id object experience object salary object dtype: object -------------------------------------------------- id int64 experience int64 salary float64 dtype: object
The
DataFrame.apply()
method applies a function along an axis of the DataFrame.
We passed the
pandas.to_numeric()
method to the apply() function.
df = df.apply(pd.to_numeric) # id int64 # experience int64 # salary float64 # dtype: object print(df.dtypes)
The to_numeric() method converts the supplied argument to a numeric type.
The default return
dtype is
float64 or int64 depending on the supplied data.
Notice that the values in the integer columns got converted to int64 and the
values in the float columns got converted to float64.
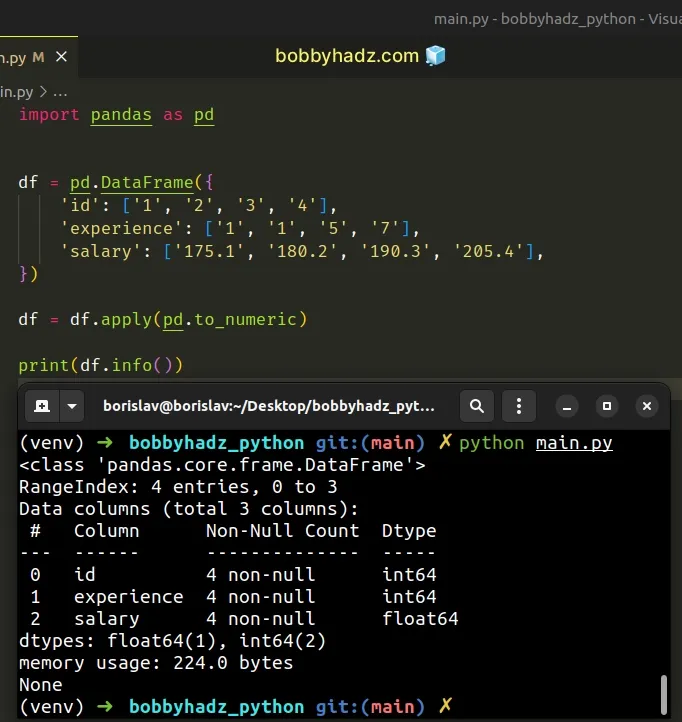
You can also use the DataFrame.info() method to verify that the values have been converted to integers.
import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) df = df.apply(pd.to_numeric) # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 4 entries, 0 to 3 # Data columns (total 3 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 id 4 non-null int64 # 1 experience 4 non-null int64 # 2 salary 4 non-null float64 # dtypes: float64(1), int64(2) # memory usage: 224.0 bytes print(df.info())
# Setting the errors argument if not all columns are convertible to numeric
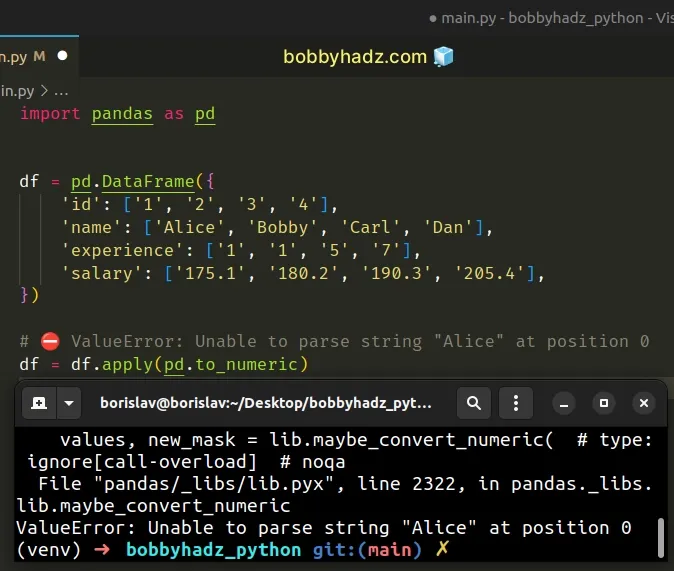
If not all arguments in the DataFrame are convertible to numeric, you will get
an error when calling DataFrame.apply():
- ValueError: Unable to parse string "X" at position 0
import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) # ⛔️ ValueError: Unable to parse string "Alice" at position 0 df = df.apply(pd.to_numeric)
The pandas.to_numeric method takes an errors argument.
By default, the argument is set to "raise", which means that invalid parsing
raises an exception.
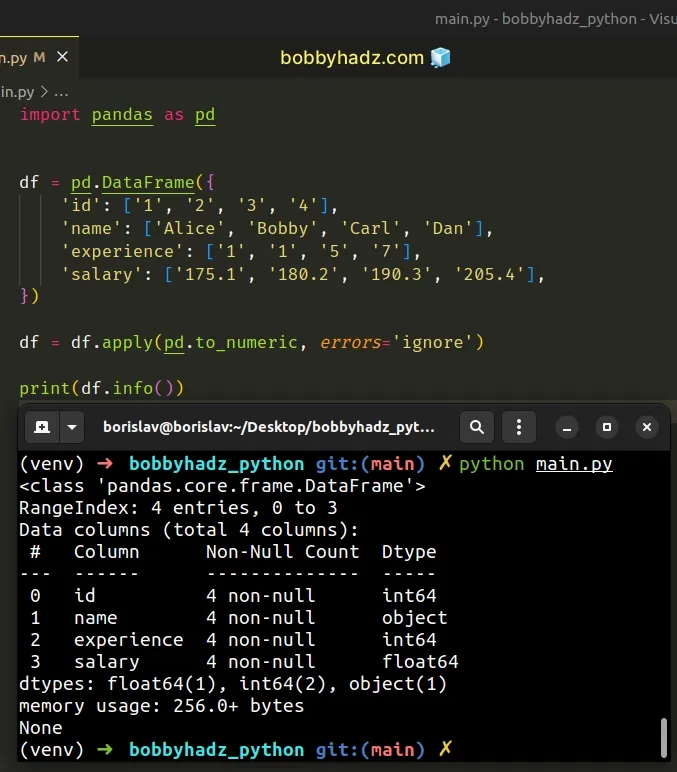
You can set the errors argument to "ignore" to return the values as is if
an error is raised when parsing.
import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) df = df.apply(pd.to_numeric, errors='ignore') # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 4 entries, 0 to 3 # Data columns (total 4 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 id 4 non-null int64 # 1 name 4 non-null object # 2 experience 4 non-null int64 # 3 salary 4 non-null float64 # dtypes: float64(1), int64(2), object(1) # memory usage: 256.0+ bytes print(df.info())
When the errors argument is set to "ignore", invalid parsing returns the
input.
The code sample passes the errors argument to the DataFrame.apply() method,
however, you can also use the partial class from the built-in functools
module when calling apply().
from functools import partial import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) df = df.apply(partial(pd.to_numeric, errors='ignore')) # <class 'pandas.core.frame.DataFrame'> # RangeIndex: 4 entries, 0 to 3 # Data columns (total 4 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 id 4 non-null int64 # 1 name 4 non-null object # 2 experience 4 non-null int64 # 3 salary 4 non-null float64 # dtypes: float64(1), int64(2), object(1) # memory usage: 256.0+ bytes print(df.info())

# Setting the errors argument to coerce
If you'd rather set values that cannot be converted to numeric to NaN, set the
errors argument to "coerce" when calling DataFrame.apply().
import pandas as pd df = pd.DataFrame({ 'id': ['1', '2', '3', '4'], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'experience': ['1', '1', '5', '7'], 'salary': ['175.1', '180.2', '190.3', '205.4'], }) df = df.apply(pd.to_numeric, errors='coerce') # id name experience salary # 0 1 NaN 1 175.1 # 1 2 NaN 1 180.2 # 2 3 NaN 5 190.3 # 3 4 NaN 7 205.4 print(df) print('-' * 50) # id int64 # name float64 # experience int64 # salary float64 # dtype: object print(df.dtypes)
When the errors argument is set to "coerce", values that cannot be parsed
are set to NaN.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- How to convert a Pandas DataFrame to a Markdown Table
- How to convert a Pandas DataFrame to a Markdown Table
- Reduction operation 'argmax' not allowed for this dtype
- Pandas: Select first N or last N columns of DataFrame
- Pandas: Describe not showing all columns in DataFrame [Fix]
- Pandas: Find common Rows (intersection) between 2 DataFrames
- Pandas: Select Rows between two values in DataFrame
- Pandas: How to Filter a DataFrame by value counts
- Pandas: Get the Rows that are NOT in another DataFrame
- How to Transpose a Pandas DataFrame without index

