How to remove the 'b' prefix from a String in Python
Last updated: Apr 10, 2024
Reading time·3 min

# Table of Contents
- Remove the 'b' prefix from a string in Python
- Remove the 'b' prefix from a string using str()
- Remove the 'b' prefix from a string using repr()
# Remove the 'b' prefix from a string in Python
Use the bytes.decode() method to remove the b prefix from a bytes object
by converting it to a string.
The decode() method will return a string decoded from the given bytes object
and will remove the b prefix.
my_bytes = 'bobbyhadz.com'.encode('utf-8') print(my_bytes) # 👉️ b'bobbyhadz.com' print(type(my_bytes)) # 👉️ <class 'bytes'> string = my_bytes.decode('utf-8') print(string) # 👉️ bobbyhadz.com print(type(string)) # 👉️ <class 'str'>
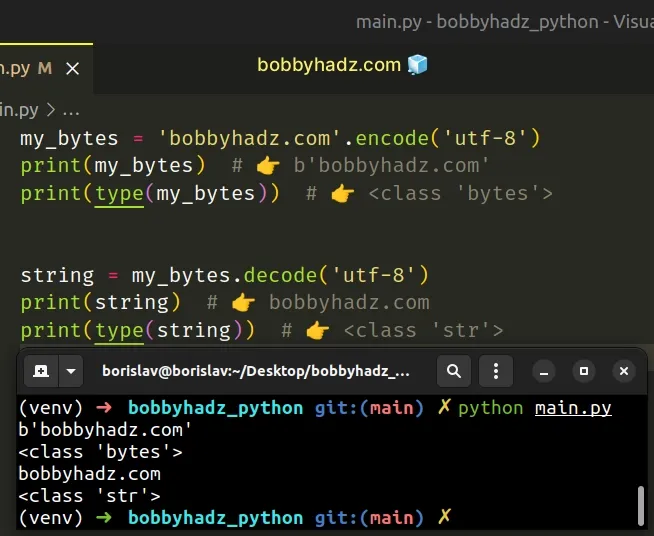
Bytes objects are always prefixed with b'', so to remove the prefix, we have
to convert the bytes to a string.
The
bytes.decode()
method returns a string decoded from the given bytes. The default encoding is
utf-8.
Conversely, the
str.encode()
method returns an encoded version of the string as a bytes object. The default
encoding is utf-8.
my_bytes = 'bobbyhadz.com'.encode('utf-8') print(my_bytes) # 👉️ b'bobbyhadz.com' string = my_bytes.decode('utf-8') print(string) # 👉️ bobbyhadz.com
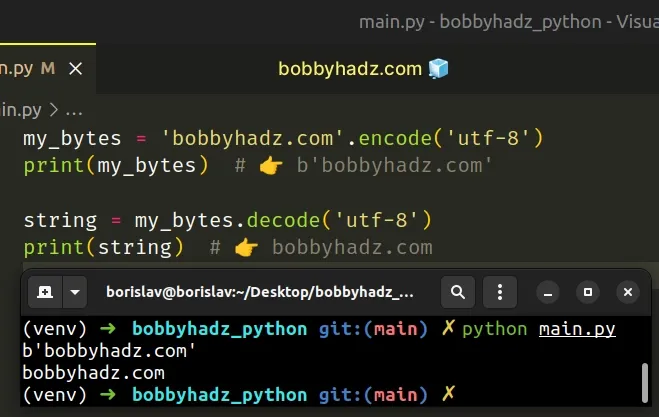
string to a bytes object and decoding is the process of converting a bytes object to a string.In other words, you can use the str.encode() method to go from str to
bytes and bytes.decode() to go from bytes to str.
# Remove the 'b' prefix from a string using str()
Alternatively, you can use the str() class.
my_bytes = bytes('bobbyhadz.com', encoding='utf-8') print(my_bytes) # 👉️ b'bobbyhadz.com' print(type(my_bytes)) # 👉️ <class 'bytes'> string = str(my_bytes, encoding='utf-8') print(string) # 👉️ bobbyhadz.com print(type(string)) # 👉️ <class 'str'>
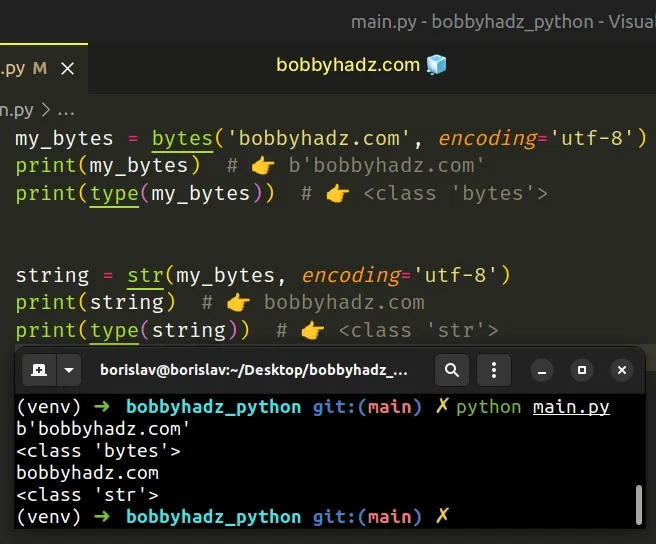
The str() class returns a string version of the given object. If an object is not provided, the class returns an empty string.
The syntax for using the
bytes() class is
the same. The class returns a bytes object, so the b prefix is added.
utf-8 encoding in the examples. The utf-8 encoding is capable of encoding over a million valid character code points in Unicode.You can view all of the standard encodings in this table of the official docs.
Some of the common encodings are ascii, latin-1 and utf-32.
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
# Remove the 'b' prefix from a string using repr()
If for some reason, you need to remove the b prefix in a hacky way, try using
the repr() function with
string slicing.
my_bytes = bytes('bobbyhadz.com', encoding='utf-8') print(my_bytes) # 👉️ b'bobbyhadz.com' string = repr(my_bytes)[2:-1] print(string) # 👉️ bobbyhadz.com
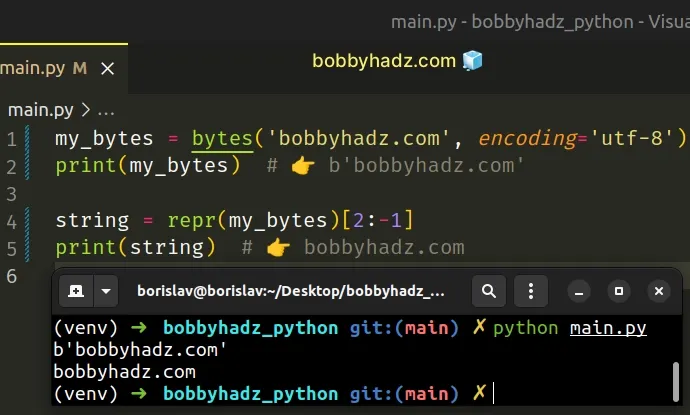
The repr() function returns the canonical string representation of the object.
my_bytes = bytes('bobbyhadz.com', encoding='utf-8') print(my_bytes) # 👉️ b'bobbyhadz.com' print(repr(my_bytes)) # 👉️ b'bobbyhadz.com'
Once we have the bytes object converted to a string, we can use string-slicing
to remove the b prefix.
The syntax for string slicing is my_str[start:stop:step].
start index is inclusive, whereas the stop index is exclusive (up to, but not including).Python indexes are zero-based, so the first character in a string has an index
of 0, and the last character has an index of -1 or len(my_str) - 1.
The slice my_str[2:-1] starts at index 2 and goes up to, but not including
the last character in the string.
We basically exclude the b character and the quotes.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- How to remove Accents from a String in Python
- Remove all Non-Numeric characters from a String in Python
- Remove Backslashes or Forward slashes from String in Python
- Remove the empty lines from a String in Python
- Remove all Empty Strings from a List of Strings in Python
- Remove First and Last Characters from a String in Python
- Remove first occurrence of character from String in Python
- Remove the First N characters from String in Python
- Remove the HTML tags from a String in Python
- Convert an Image to a Base64-encoded String in Python

