How to remove Accents from a String in Python
Last updated: Apr 9, 2024
Reading time·4 min

# Table of Contents
- Remove accents from a String in Python
- Remove the accents from a List of Strings
- Raising an error if an incompatible character is encountered
- Replacing characters that cannot be translated
- Preserving characters that cannot be translated
- Remove accents from a String using
unicodedata
# Remove accents from a String in Python
Use the unidecode package to remove the accents from a string.
The unidecode() function will remove all the accents from the string by
replacing the characters with characters that can safely be encoded to ASCII.
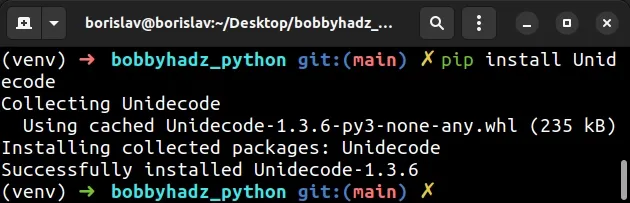
The first thing you should do is install the unidecode package.
pip install Unidecode # 👇️ or with pip3 pip3 install Unidecode
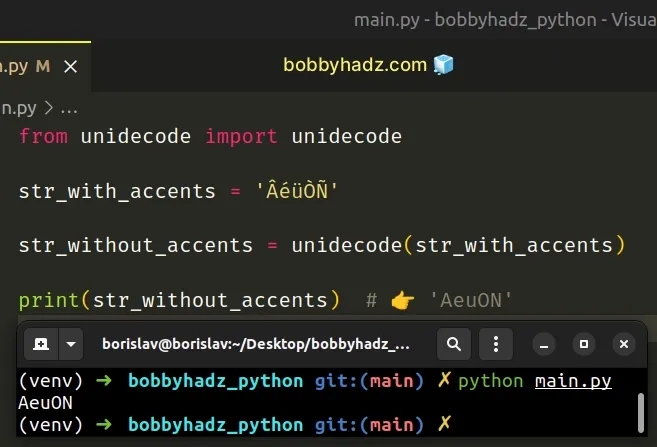
Now you can import and use the unidecode function.
from unidecode import unidecode str_with_accents = 'ÂéüÒÑ' str_without_accents = unidecode(str_with_accents) print(str_without_accents) # 👉️ 'AeuON'
unidecode function takes a string that possibly contains non-ASCII characters and returns a string that can safely be encoded to ASCII.If your string contains characters that unidecode cannot translate to
ASCII-compatible characters, the function replaces them with empty strings.
from unidecode import unidecode str_with_accents = 'ÂéüÒÑ\ue123' str_without_accents = unidecode(str_with_accents) print(str_without_accents) # 👉️ 'AeuON'
Notice that the \ue123 character couldn't get converted to an ASCII-compatible
character and got dropped from the string.
# Remove the accents from a List of Strings
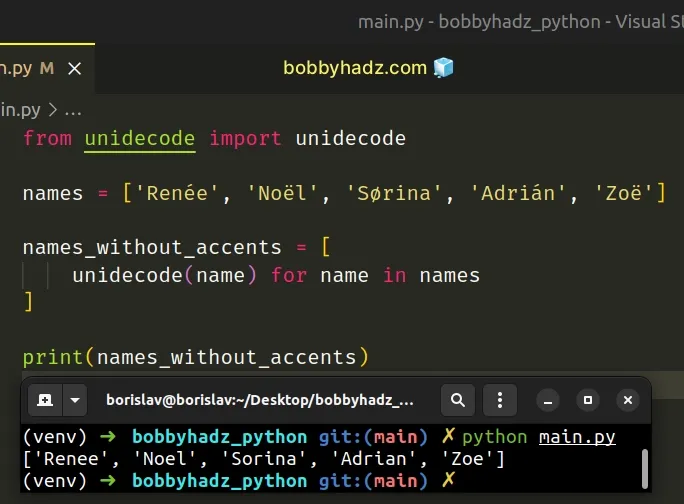
If you need to remove the accents from a list of strings, use a list comprehension.
from unidecode import unidecode names = ['Renée', 'Noël', 'Sørina', 'Adrián', 'Zoë'] names_without_accents = [ unidecode(name) for name in names ] # 👇️ ['Renee', 'Noel', 'Sorina', 'Adrian', 'Zoe'] print(names_without_accents)
List comprehensions are used to perform some operation for every element or select a subset of elements that meet a condition.
On each iteration, we use the unidecode() method to remove the accents from
the current list item and return the result.
The strings in the new list don't contain any accents.
# Raising an error if an incompatible character is encountered
If you want to raise an error if the unidecode function encounters a character
it cannot translate to an ASCII-compatible character, set the
errors keyword argument
to strict.
from unidecode import unidecode str_with_accents = 'ÂéüÒÑ\ue123' # ⛔️ unidecode.UnidecodeError: no replacement found for character '\ue123' in position 5 str_without_accents = unidecode(str_with_accents, errors='strict')
The unidecode function found no replacement for the \ue123 character, so it
raised an error.
The unidecode package exposes a UnidecodeError object that gives us access
to the index of the character that couldn't get translated.
from unidecode import unidecode, UnidecodeError str_with_accents = 'ÂéüÒÑ\ue123' # ⛔️ unidecode.UnidecodeError: no replacement found for character '\ue123' in position 5 try: str_without_accents = unidecode(str_with_accents, errors='strict') except UnidecodeError as e: print(e.index) # 👉️ 5
The character at index 5 raised the error.
# Replacing characters that cannot be translated
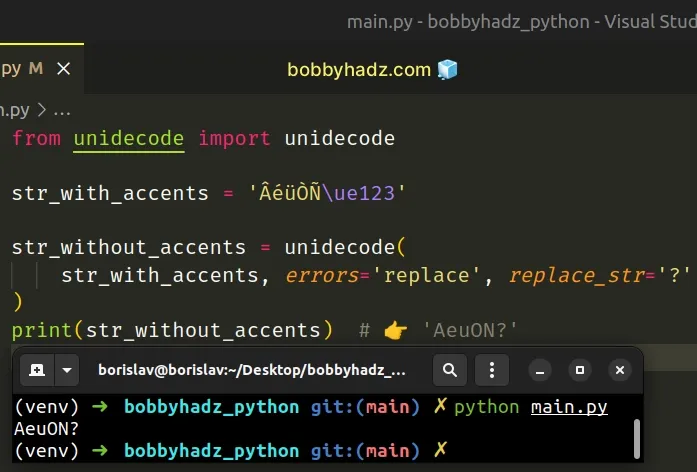
You can also set the errors keyword argument to replace to replace the
character that cannot be translated with another string.
from unidecode import unidecode str_with_accents = 'ÂéüÒÑ\ue123' str_without_accents = unidecode( str_with_accents, errors='replace', replace_str='?' ) print(str_without_accents) # 👉️ 'AeuON?'
replace_str keyword argument is used to specify the replacement string.# Preserving characters that cannot be translated
You can use the preserve keyword argument if you want to preserve the
characters that cannot be translated to ASCII-compatible characters.
from unidecode import unidecode str_with_accents = 'ÂéüÒÑ\ue123' str_without_accents = unidecode( str_with_accents, errors='preserve', ) print(str_without_accents) # 👉️ 'AeuON'
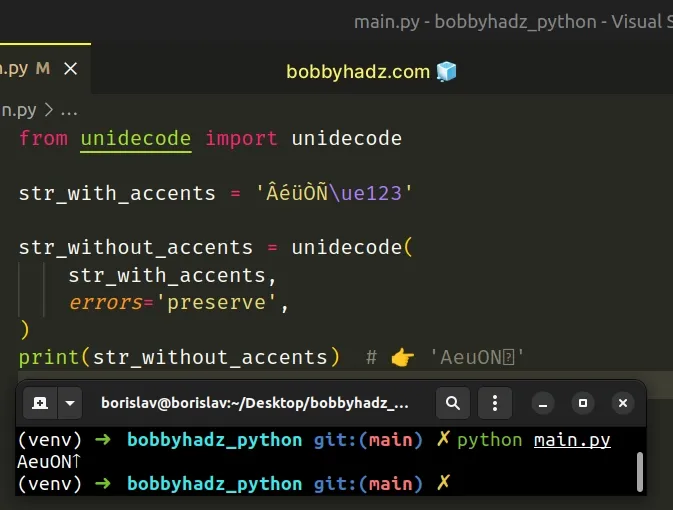
However, if errors is set to preserve, the unidecode function doesn't
produce an ASCII-compatible string.
# Remove accents from a String using unicodedata
You can also use the built-in unicodedata module to remove the accents from a string.
import unicodedata def remove_accents(string): return ''.join(char for char in unicodedata.normalize('NFD', string) if unicodedata.category(char) != 'Mn') str_with_accents = 'ÂéüÒÑ' print(remove_accents(str_with_accents)) # 👉️ AeuON # 👇️ Noel, Adrian, Sørina, Zoe, Renee print(remove_accents('Noël, Adrián, Sørina, Zoë, Renée'))
The unicodatata module is a built-in Python module, so you don't have to
install anything.
The code sample uses a generator expression to iterate over the characters of the string.
The unicodedata.normalize() method returns the normal form for the given string.
The first argument is the form - NFD in our case. The normal form NFD
translates each character into its decomposed form.
import unicodedata str_with_accents = 'ÂéüÒÑ' result = list((char for char in unicodedata.normalize('NFD', str_with_accents) if unicodedata.category(char) != 'Mn')) print(result) # 👉️ ['A', 'e', 'u', 'O', 'N']
The unicodedata.category() method takes a character as a parameter and returns the general category assigned to the character.
import unicodedata str_with_accents = 'aeÂéüÒÑ' print(unicodedata.category(str_with_accents[0])) # Ll print(unicodedata.category(str_with_accents[1])) # Ll print(unicodedata.category(str_with_accents[2])) # Lu print(unicodedata.category(str_with_accents[3])) # Ll
The Mn character category is a non-spacing combining mark.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove all Non-Numeric characters from a String in Python
- How to remove the 'b' prefix from a String in Python
- Remove Backslashes or Forward slashes from String in Python
- Remove the empty lines from a String in Python
- Remove all Empty Strings from a List of Strings in Python
- Remove First and Last Characters from a String in Python

