TypeError: string argument without an encoding in Python
Last updated: Apr 8, 2024
Reading time·3 min

# TypeError: string argument without an encoding in Python
The Python "TypeError: string argument without an encoding" occurs when we
pass a string to the bytes class without specifying the encoding.
To solve the error, pass the encoding as the second argument to the bytes
class.

Here are 2 examples of how the error occurs when using the bytes and
bytearray classes.
# ⛔️ TypeError: string argument without an encoding print(bytes('hello')) # ⛔️ TypeError: string argument without an encoding print(bytearray('hello'))
We got the error because we passed a string to the bytes() class without
specifying the encoding.
# Specify the encoding in the call to the bytes() class
We can pass the encoding as the second argument to the class.
# 👇️ b'hello' print(bytes('hello', encoding='utf-8')) # 👇️ bytearray(b'hello') print(bytearray('hello', encoding='utf-8'))
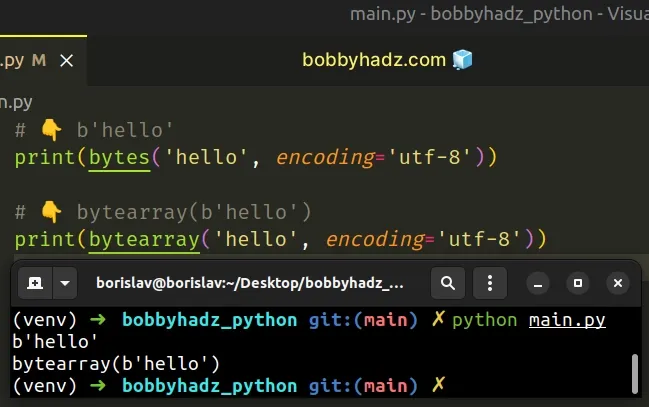
When a string is passed to the bytes or bytearray classes, we must also
specify the encoding.
You can also pass the encoding as a positional argument to the bytes and
bytearray classes.
# 👇️ b'hello' print(bytes('hello', 'utf-8')) # 👇️ bytearray(b'hello') print(bytearray('hello', 'utf-8'))
Even though it is obvious that the second parameter is the encoding, it is still a bit implicit and more difficult to read.
The bytes class
returns a new bytes object which is an immutable sequence of integers in the
range 0 <= x < 256.
The bytearray class returns an array of bytes and is a mutable sequence of integers in the same range.
# Using the str.encode() method to convert a string to bytes
You can also use the str.encode() method to convert a string to a bytes
object.
my_str = 'hello' my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'hello'
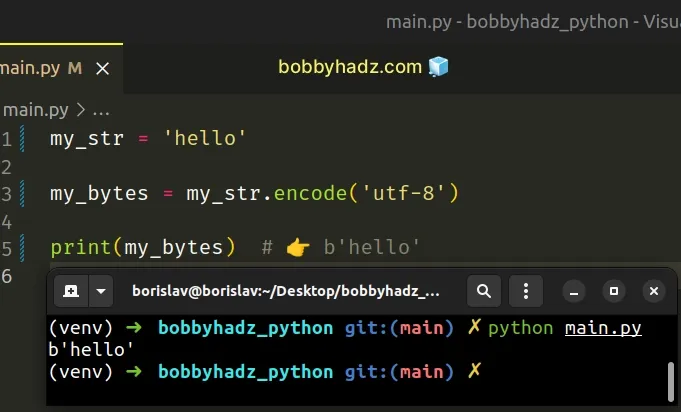
The str.encode() method returns an
encoded version of the string as a bytes object. The default encoding is
utf-8.
# Using the bytes.decode() method to convert a bytes object to a string
Conversely, you can use the decode() method to convert a bytes object to a
string.
my_str = 'hello' my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'hello' my_str_again = my_bytes.decode('utf-8') print(my_str_again) # 👉️ 'hello'
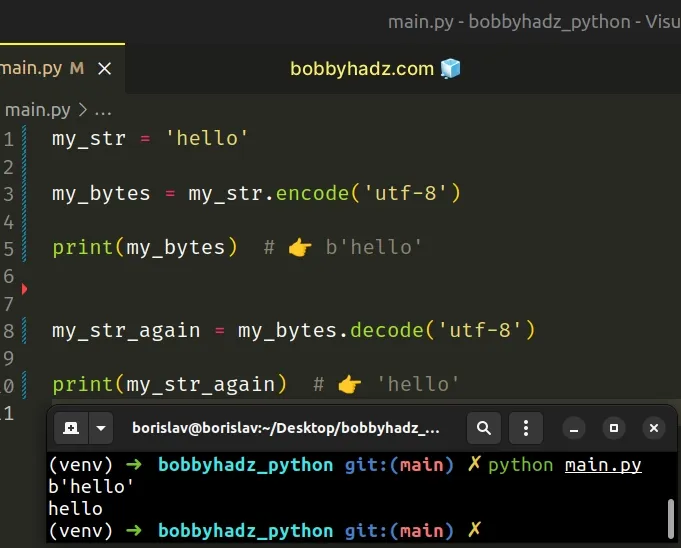
The bytes.decode() method returns a
string decoded from the given bytes. The default encoding is utf-8.
string to a bytes object and decoding is the process of converting a bytes object to a string.In other words, you can use the str.encode() method to go from str to
bytes and bytes.decode() to go from bytes to str.
# Using the bytes() and str() classes instead
You can also use bytes(s, encoding=...) and str(b, encoding=...).
my_text = 'hello' my_binary_data = bytes(my_text, encoding='utf-8') print(my_binary_data) # 👉️ b'hello' my_text_again = str(my_binary_data, encoding='utf-8') print(my_text_again) # 👉️ 'hello'
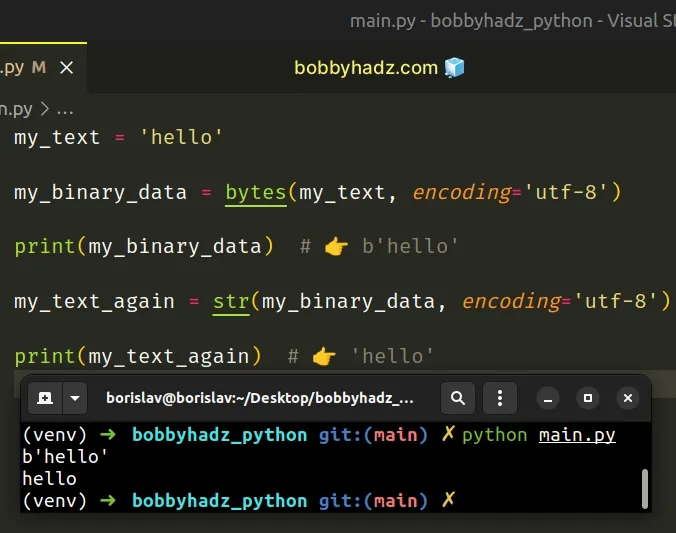
The str class returns a string version of the given object. If an object is not provided, the class returns an empty string.
All text in Python is Unicode, however, encoded Unicode is represented as binary data.
You can use the str type to store text and the bytes type to store binary
data.
u'...' literals for Unicode text because all strings are now Unicode.However, you must use b'...' literals for binary data.
When the first argument we pass to the bytes() or bytearray() classes is a
string, you must also specify the encoding.
You only have to specify the encoding when the first argument you pass to the methods is a string.
If you call the bytearray() method with an integer or an iterable of integers,
you don't have to specify the encoding.
print(bytearray(5)) # 👉️ bytearray(b'\x00\x00\x00\x00\x00') print(bytearray([1, 2, 3])) # 👉️ bytearray(b'\x01\x02\x03')
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

