Remove the HTML tags from a String in Python
Last updated: Apr 9, 2024
Reading time·4 min

# Table of Contents
- Remove the HTML tags from a String in Python
- Remove the HTML tags from a String using xml.etree.ElementTree
- Remove the HTML tags from a String using lxml
- Remove the HTML tags from a String using BeautifulSoup
- Remove the HTML tags from a String using HTMLParser in Python
# Remove the HTML tags from a String in Python
Use the re.sub() method to remove the HTML tags from a string.
The re.sub() method will remove all of the HTML tags in the string by
replacing them with empty strings.
import re html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ pattern = re.compile('<.*?>') result = re.sub(pattern, '', html_string) # Bobby # Hadz # Com print(result)
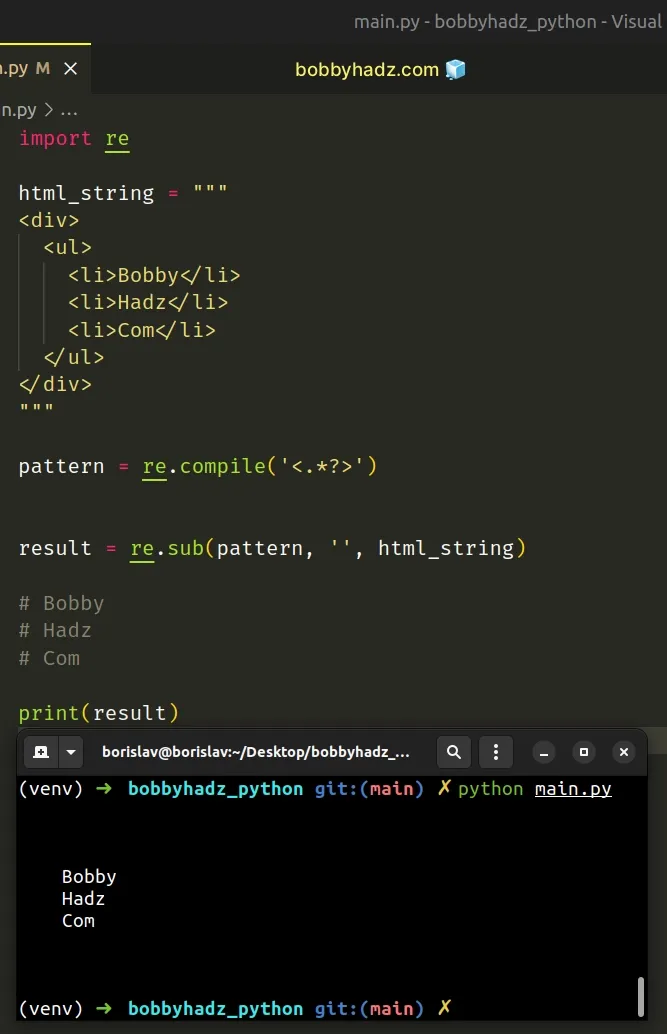
The code sample uses a regular expression to strip the HTML tags from a string.
The re.sub() method returns a new string that is obtained by replacing the occurrences of the pattern with the provided replacement.
If the pattern isn't found, the string is returned as is.
re.sub() method is a regular expression.The brackets < and > match the opening and closing characters of an HTML
tag.
The dot . matches any character except a newline character.
* matches 0 or more repetitions of the preceding character (any character).Adding a question mark ? after the qualifier makes it perform a non-greedy or
minimal match.
For example, using the regular expression <.*?> will match only <a>.
In its entirety, the regular expression matches all opening and closing HTML tags.
# Remove the HTML tags from a String using xml.etree.ElementTree
You can also use the xml.etree.ElementTree module to strip the HTML tags from a string.
import xml.etree.ElementTree as ET html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ result = ''.join(ET.fromstring(html_string).itertext()) # Bobby # Hadz # Com print(result)
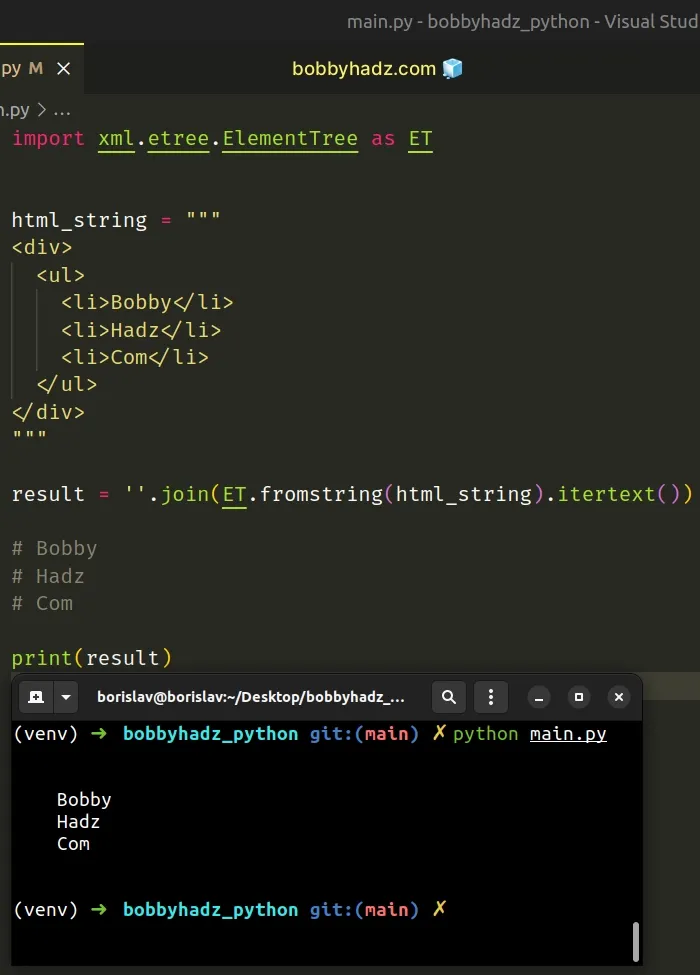
The
fromstring()
method parses an XML section from a string constant and returns an Element
instance.
The
itertext()
method creates a text iterator that we can join with the str.join() method.
# Remove the HTML tags from a String using lxml
You can also use the lxml module to strip the HTML tags from a string.
Make sure you have the module installed by running the following command.
pip install lxml # 👇️ or pip3 pip3 install lxml
Now you can import and use the lxml module to strip the HTML tags from the
string.
from lxml.html import fromstring html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ result = fromstring(html_string).text_content() # Bobby # Hadz # Com print(result)
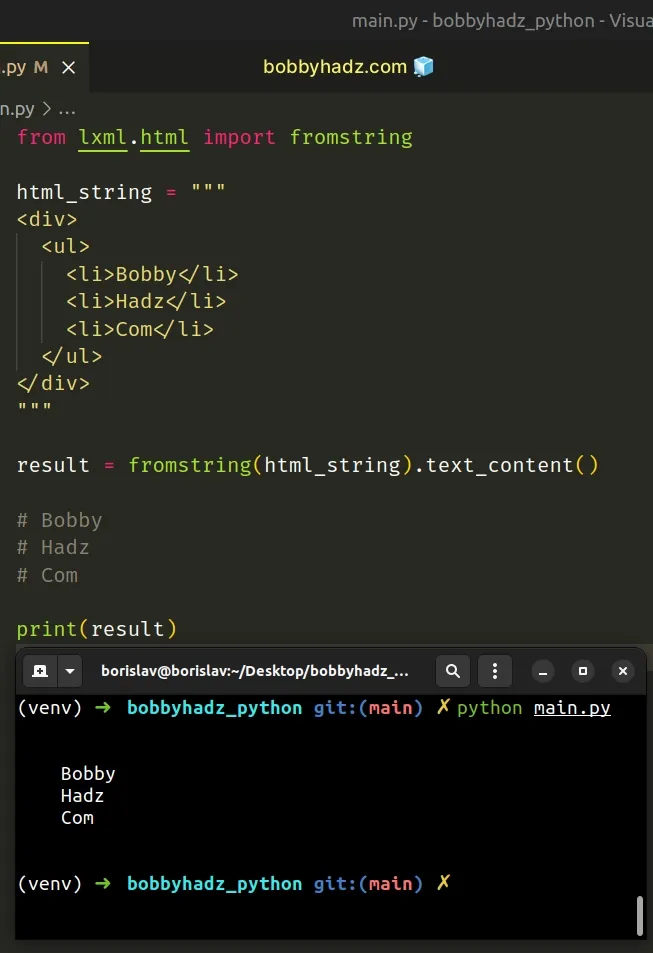
The text_content method removes all markup from a string.
# Remove the HTML tags from a String using BeautifulSoup
You can also use the BeautifulSoup4 module to remove the HTML tags from a string.
Make sure you have the module installed to be able to run the code sample.
pip install lxml pip install beautifulsoup4 # 👇️ or pip3 pip3 install lxml pip3 install beautifulsoup4
Now you can import and use the BeautifulSoup module to strip the HTML tags
from the string.
from bs4 import BeautifulSoup html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ result = BeautifulSoup(html_string, 'lxml').text # Bobby # Hadz # Com print(result)
The text attribute on the BeautifulSoup object returns the text content of
the string, excluding the HTML tags.
# Remove the HTML tags from a String using HTMLParser in Python
This is a four-step process:
- Extend from the
HTMLParserclass from thehtml.parsermodule. - Implement the
handle_datamethod to get the data between the HTML tags. - Store the data in a list on the class instance.
- Call the
get_data()method on an instance of the class.
from html.parser import HTMLParser class HTMLTagsRemover(HTMLParser): def __init__(self): super().__init__(convert_charrefs=False) self.reset() self.convert_charrefs = True self.fed = [] def handle_data(self, data): self.fed.append(data) def handle_entityref(self, name): self.fed.append(f'&{name};') def handle_charref(self, name): self.fed.append(f'&#{name};') def get_data(self): return ''.join(self.fed) def remove_html_tags(value): remover = HTMLTagsRemover() remover.feed(value) remover.close() return remover.get_data() html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ # Bobby # Hadz # Com print(remove_html_tags(html_string))
The remove_html_tags function takes a string and strips the HTML tags from the
supplied string.
We extended from the HTMLParser class. The code snippet is very similar
to the one used internally
by the django module.
The HTMLParser class is used to find tags and other markup and call handler
functions.
self.handle_data().When convert_charrefs is set to True, character references automatically get
converted to the corresponding Unicode character.
If convert_charrefs is set to False, character references are passed by
calling the self.handle_entityref() or self.handle_charref() methods.
get_data() method uses the str.join() method to join the list of strings without a separator.The str.join method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The remove_html_tags() function takes a string that contains HTML tags and
returns a new string where all opening and closing HTML tags have been removed.
def remove_html_tags(value): remover = HTMLTagsRemover() remover.feed(value) remover.close() return remover.get_data() html_string = """ <div> <ul> <li>Bobby</li> <li>Hadz</li> <li>Com</li> </ul> </div> """ # Bobby # Hadz # Com print(remove_html_tags(html_string))
The function instantiates the class and feeds the string containing the HTML tags to the parser.
close() method on the instance to handle any buffered data.Lastly, we call the get_data() method on the instance to join the list of
strings into a single string that doesn't contain any HTML tags.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove first occurrence of character from String in Python
- Remove the First N characters from String in Python
- Remove First and Last Characters from a String in Python
- Remove the empty lines from a String in Python
- Remove all Empty Strings from a List of Strings in Python
- How to remove Accents from a String in Python
- Remove all Non-Numeric characters from a String in Python
- How to remove the 'b' prefix from a String in Python
- Remove Backslashes or Forward slashes from String in Python

