How to use Parameters in AWS CDK - Complete Guide
Last updated: Jan 27, 2024
Reading time·7 min

# Table of Contents
- Defining CDK Parameters
- Deploying with CDK Parameters
- Parameters are unresolved Tokens in our CDK code
- How to use CDK Parameter Values
- Caveats when using CDK Parameters
- CDK and CloudFormation Parameters
# Defining CDK Parameters
Parameters are key-value pairs that we pass into a CDK stack at deployment time.
Since we pass these key-value pairs at deployment time, we aren't able to access the resolved values in our CDK code at synthesis time - i.e. in conditional statements.
It's recommended to define CDK parameters at the stack level.
The reason is that parameters derive their name from their logical ID, so if we refactor our code the logical ID could change, which means that the parameter would get deleted and re-created with a new name.
The name would be set to the new logical ID. This would be quite confusing.
To define a parameter in CDK, we can use the CfnParameter construct.
// 👇 parameter of type Number const databasePort = new cdk.CfnParameter(this, 'databasePort', { type: 'Number', description: 'The database port to open for ingress connections', minValue: 1, maxValue: 10000, default: 5432, allowedValues: ['1000', '3000', '5000', '5432'], }); console.log('database port 👉', databasePort.valueAsString); // 👇 parameter of type String const tableName = new cdk.CfnParameter(this, 'tableName', { type: 'String', description: 'The name of the Dynamodb table', }); console.log('tableName 👉 ', tableName.valueAsString); // 👇 parameter of type CommaDelimitedList const favoriteRegions = new cdk.CfnParameter(this, 'favoriteRegions', { type: 'CommaDelimitedList', description: 'An array of regions', }); console.log('favoriteRegions 👉 ', favoriteRegions.valueAsList);
Note that we aren't explicitly passing a parameterName property because one
doesn't exist. Instead, the parameter name is inferred from the logical ID of
the resource.
We have defined 3 parameters:
- databasePort - of type
Number. - tableName - of type
String. - favoriteRegions - of type
CommaDelimitedList.
For reference, the supported Parameter types are:
String- i.e. "production"Number- i.e. 42. CloudFormation validates the input as a number, but the parameter in our code is really a string.List<Number>- an array of integer or float numbers - i.e. user input of 42,4.2 would result in ["42","4.2"]CommaDelimitedList- an array of string literals - i.e. user input of "t3.nano,t3.micro,t3.small" would result in ["t3.nano","t3.micro","t3.small"]AWS Specific Parameter types- values corresponding to resources that already exist in your account, i.e. user input of "AWS::EC2::VPC::Id" means the user must pass an existing VPC ID as a parameter- SSM parameter types - values corresponding to existing parameters from the Parameter Store service. The user must input an existing parameter key and it will be resolved to the corresponding value.
After defining the parameters in our CDK stack, if we try to deploy without providing any parameters, we would get an error of type:

Things to notice:
- The parameter names correspond to the logical ID of the resources.
- Because we've passed a
defaultvalue to ourdatabasePortparameter, it's not required.
# Deploying with CDK Parameters
In order to deploy a CDK stack with parameters, we have to pass the
--parameters flag when issuing the npx aws-cdk deploy command.
npx aws-cdk deploy my-stack-name \ --parameters myFirstParameter=value1 \ --parameters mySecondParameter=value2
Note that we have to use the --parameters flag for every parameter we pass
into the template.
When deploying multiple stacks with different parameter values, we have to prefix the parameter name with the stack name.
npx aws-cdk deploy my-stack-dev my-stack-prod \ --parameters my-stack-dev:tableName=devTable \ --parameters my-stack-prod:tableName=prodTable
For our project, the deployment command looks as follows.
npx aws-cdk deploy my-cdk-stack \ --parameters databasePort=1000 \ --parameters tableName=cool-table \ --parameters favoriteRegions="us-east-1,us-east-2,us-east-3"
Now that we've successfully deployed our CDK application, we can inspect the parameters section in the CloudFormation console.
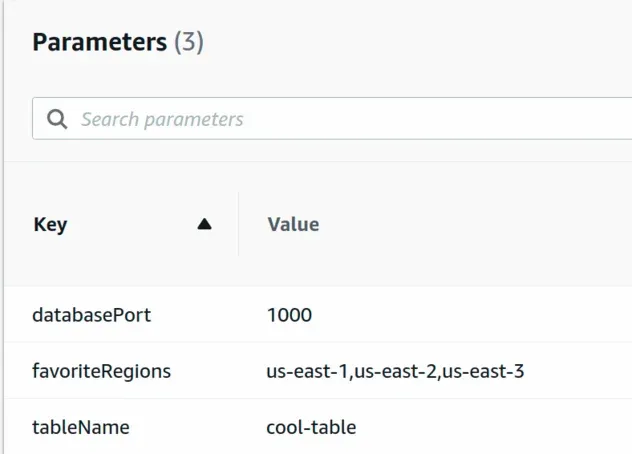
The parameter values will be persisted by CloudFormation.
This doesn't matter most of the time because we should have consistent deployment commands put in place that specify all the necessary stack parameters. Relying on some state that might or might not be what we expect is probably not a good idea.
# Parameters are unresolved Tokens in our CDK code
When we defined our parameters we put a couple of console.log statements in
place.
console.log('database port 👉', databasePort.valueAsString); console.log('tableName 👉 ', tableName.valueAsString); console.log('favoriteRegions 👉 ', favoriteRegions.valueAsList);
Let's look at what the output was when we deployed our CDK stack.
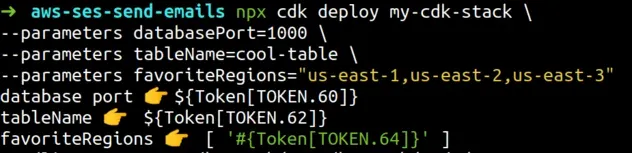
We can see that the output is Token values. That was the expected behavior, because only after our CDK code has finished running will our CloudFormation stack get deployed and resolve the values.
If you're interested to learn more about Tokens, I've written an article What is a Token in AWS CDK.
In short, a Token is an encoded value that will be resolved at deployment time
by CloudFormation. In other words, not what we want if we intend to use the
value in an if statement.
# How to use CDK Parameter Values
Let's define a Dynamodb table and set its
tableName property to the tableName Parameter.
// 👇 parameter of type String const tableName = new cdk.CfnParameter(this, 'tableName', { type: 'String', description: 'The name of the Dynamodb table', }); console.log('tableName 👉 ', tableName.valueAsString); const myTable = new dynamodb.Table(this, 'my-table', { // 👇 set the tableName property to the parameter value tableName: tableName.valueAsString, partitionKey: {name: 'todoId', type: dynamodb.AttributeType.NUMBER}, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, removalPolicy: cdk.RemovalPolicy.DESTROY, });
Let's run the deployment command.
npx aws-cdk deploy my-cdk-stack \ --parameters databasePort=1000 \ --parameters tableName=cool-table \ --parameters favoriteRegions="us-east-1,us-east-2,us-east-3"
If we now check our CloudFormation console, we can see that our table has been
named cool-table, which corresponds to the parameter value we passed:
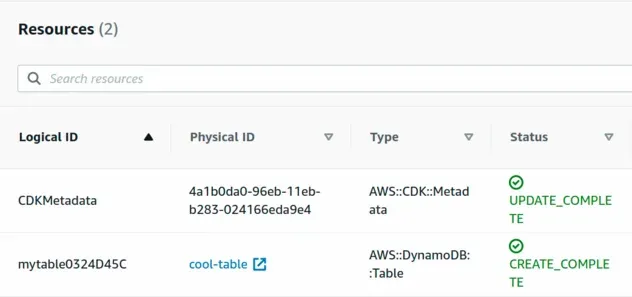
We were able to set the table name to be equal to the Parameter value we passed. This is the expected behavior.
If we generate a CloudFormation template based on our current CDK app, we would see the plain CloudFormation Parameters section.
Parameters: databasePort: Type: Number Default: 5432 AllowedValues: - "1000" - "3000" - "5000" - "5432" Description: The database port to open for ingress connections MaxValue: 10000 MinValue: 1 tableName: Type: String Description: The name of the Dynamodb table favoriteRegions: Type: CommaDelimitedList Description: An array of regions
We could also create a lambda function and pass it the parameters as environment variables:
const myFunction = new NodejsFunction(this, id, { // setting environment variables from params 👇 environment: { databasePort: databasePort.valueAsString, tableName: tableName.valueAsString, }, runtime: lambda.Runtime.NODEJS_18_X, handler: 'main', entry: path.join(__dirname, `/../src/my-function/index.js`), });
The function's code could be as simple as:
async function main(event) { console.log('databasePort 👉', process.env.databasePort); console.log('tableName 👉', process.env.tableName); return {body: JSON.stringify({message: 'SUCCESS'}), statusCode: 200}; } module.exports = {main};
If we invoke the function we are able to access the parameter values:

As a side note, I wasn't able to pass the CommaDelimitedList to the function,
couldn't figure it out. Reading through the
support forum comments,
I don't think it's possible to pass commas in lambda environment variables, who
knew.
# Caveats when using CDK Parameters
If you deploy the CDK stack with an updated parameter value, but don't change your CDK code, the parameter value does not get updated, which is very confusing.
The output just states: ✅️ my-stack (no changes) and the parameter value is not updated in CloudFormation, which we can check using the console.
It's important to note that using Parameters in our CDK applications is not recommended by the AWS team because Parameter values are not resolved during synthesis time in our CDK code. Instead, they are resolved at deployment time. This means that we aren't able to use parameter values in conditionals in our CDK code.
Instead, the CDK team recommends using environment variables and context, which are resolved at synthesis time and can be used in our CDK code to conditionally provision or update resources.
This makes a lot of sense because we don't have to think about which values resolve when and which values we can use in our CDK code.
# CDK and CloudFormation Parameters
Since CDK gets compiled down to CloudFormation, we are able to use CloudFormation Parameters in CDK.
You can think of Parameters as key-value pairs that we pass into the CDK stack at deployment time.
Since we pass these key-value pairs at deployment time, we aren't able to access the resolved values in our CDK code at synthesis time - i.e. in conditional statements.
An example of parameters in a CloudFormation stack looks as follows.
Parameters: # 👇 defining the DatabasePort parameter DatabasePort: Default: 5432 Description: The database port to open for the ingress connections Type: Number # 👇 defining the DatabaseName parameter DatabaseName: Default: tododb Description: Database name Type: String
In the snippet above, we defined the DatabasePort and DatabaseName
parameters, which we can then pass to our CloudFormation stack at deployment
time.
aws cloudformation deploy \ --template-file template.yaml \ --parameter-overrides DatabaseName=myDatabase \ DatabasePort=1234
To complete the flow we can access the Parameters by using the Ref function in
our template's Resources and Outputs sections.
For example, let's pass the DatabaseName as an environment variable to a
Lambda.
ListTodosFunction: Type: AWS::Lambda::Function Properties: Environment: Variables: databaseName: !Ref DatabaseName
If we can, it's best to avoid Parameters. We should use environment variables or context instead, which we can access in our CDK code at synthesis time.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- AWS CDK Tutorial for Beginners - Step-by-Step Guide
- What is a Token in AWS CDK
- CDK Constructs - Complete Guide
- What is an identifier (id) in AWS CDK
- How to use Context in AWS CDK
- Lambda Function Example in AWS CDK - Complete Guide
- Write TypeScript Lambda functions in AWS CDK - Complete Guide
- How to use Outputs in AWS CDK

