What is an identifier (id) in AWS CDK - Complete Guide
Last updated: Jan 27, 2024
Reading time·11 min

# Table of Contents
- Identifiers in CDK
- The drawbacks of explicitly assigning Names in AWS CDK
- Overriding Logical IDs in CDK
# Identifiers in CDK
The purpose of identifiers in CDK is to create a unique resource ID, such as
the Logical Identifier of resources provisioned using CloudFormation.
Identifiers must be unique in the scope they are created in, however, they don't have to be globally unique in the entire CDK application.
Identifiers in CDK are of 3 types:
- Construct IDs
- Paths
- Unique IDs (Logical IDs)
# Construct IDs
A Construct in CDK is a cloud component. Constructs encapsulate logic for creating a component that could consist of one or more resources.
Constructs allow us to write useful abstractions on top of CloudFormation and reduce some of the duplications in resource definitions.
For example, an S3 bucket construct could look similar to the following.
import * as cdk from 'aws-cdk-lib'; import {Bucket} from 'aws-cdk-lib/aws-s3'; import {Construct} from 'constructs'; export class UploadsBucketConstruct extends Construct { public readonly s3Bucket: Bucket; constructor(scope: Construct, id: string) { super(scope, id); this.s3Bucket = new Bucket(this, id); } }
The first parameter we specify in the constructor function is the scope. In
JavaScript, we use the this keyword to denote the scope in CDK.
The second parameter the constructor method takes is the id, this is the
Construct ID.
We can use this construct in the following way.
export class CdkIdentifiersStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); const {s3Bucket: s3BucketFirst} = new UploadsBucketConstruct( this, 's3-bucket', ); } }
Notice that the Construct ID we are passing to our UploadsBucketConstruct is
s3-bucket.
Before we deploy, we must also instantiate the stack in the scope of our CDK App.
import * as cdk from 'aws-cdk-lib'; import {CdkIdentifiersStack} from '../lib/cdk-starter-stack'; const app = new cdk.App(); new CdkIdentifiersStack(app, 'cdk-identifiers-stack-dev', { stackName: 'cdk-identifiers-stack-dev', });
If I deploy the CDK stack at this point we get the following CloudFormation stack.
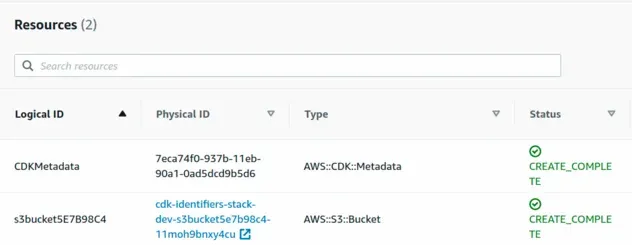
Notice the Cloudformation Logical ID is s3bucket5E7B98C4, whereas our CDK
Construct ID was just s3bucket - an 8-digit hash got appended to our CDK
Construct ID to form the CloudFormation Logical ID, more on that later in the
article.
Let's try to provision two S3 buckets with the same Construct ID at the same
scope (the scope of our CdkIdentifiersStack):
export class CdkIdentifiersStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); const {s3Bucket: s3BucketFirst} = new UploadsBucketConstruct( this, 's3-bucket', ); + const {s3Bucket: s3BucketSecond} = new UploadsBucketConstruct( + this, + 's3-bucket', + ); new cdk.CfnOutput(this, 'region', {value: cdk.Stack.of(this).region}); new cdk.CfnOutput(this, 'bucketName', { value: s3BucketFirst.bucketName, }); } }
After we try to npx aws-cdk deploy, we get an error:

At this point we know that defining two Constructs with the same Construct ID in the same scope results in an error.
However, what would happen if we were to change the Construct ID of our first
bucket?
export class CdkIdentifiersStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); const {s3Bucket: s3BucketFirst} = new UploadsBucketConstruct( this, - 's3-bucket', + 'new-s3-bucket', ); new cdk.CfnOutput(this, 'region', {value: cdk.Stack.of(this).region}); new cdk.CfnOutput(this, 'bucketName', { value: s3BucketFirst.bucketName, }); } }
Let's run the cdk diff command before we deploy the changes:
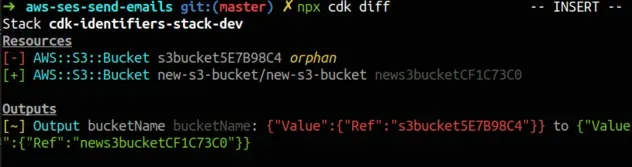
In the screenshot, we see that our old bucket with the logical id of
s3bucket5E7B98C4 would become an orphan, and we would just create a new bucket
with a new logical id of news3bucketCF1C73C0.
The reason our bucket is orphaned and not deleted is the default behavior for the Bucket construct. By default when a bucket is removed from a stack it becomes orphaned but remains in the AWS account - docs.
However, relying on default behavior and not understanding CDK identifiers is not a good approach.
Let's go through with the deployment of the bucket with the changed Construct ID and see the result in our Cloudformation stack.
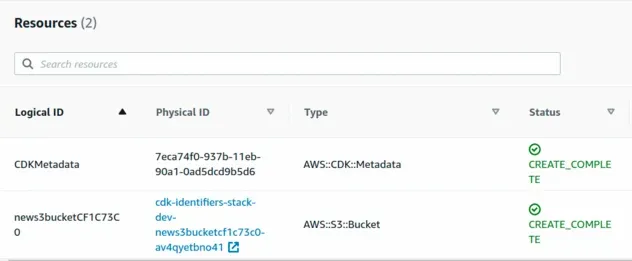
After the deployment of the stack, we can see that the logical ID of the
bucket in our stack is now news3bucketCF1C73C which is a completely different
s3 bucket than the one we had before.
Since no one really changes the Construct identifiers of resources in the way we just did, let's look at a more common way to change identifiers, by simply refactoring code.
# Paths
A Path is a collection of IDs starting with the ID, used to initialize the
root Stack and going down the constructs. The Path joins these IDs with /
characters.
For example, in our application, the path of the s3BucketFirst resource would
be cdk-identifiers-stack-dev/new-s3-bucket/new-s3-bucket.
So the path is stackName/topLevelId/nestedId. The
stack name is cdk-identifiers-stack-dev, which
we define, when we initialize the stack:
const app = new cdk.App(); new CdkIdentifiersStack(app, 'cdk-identifiers-stack-dev', { stackName: 'cdk-identifiers-stack-dev', });
Then we pass the new-s3-bucket id to the UploadsBucketConstruct, which ends
up passing it to the Bucket construct:
// Using the construct const {s3Bucket: s3BucketFirst} = new UploadsBucketConstruct( this, 'new-s3-bucket', ); // The construct implementation reuses // the passed in ID this.s3Bucket = new Bucket(this, id);
That's how our path ended up being
cdk-identifiers-stack-dev/new-s3-bucket/new-s3-bucket.
Since we know that the identifiers must be unique at the same scope, we also know that the path, which is the combination of the identifiers, starting at the root stack will also be unique.
The way to get a path of a construct in CDK is by accessing the path property
on the construct node.
const {s3Bucket: s3BucketFirst} = new UploadsBucketConstruct( this, 'new-s3-bucket', ); const s3BucketPath = s3BucketFirst.node.path; console.log('path is: ', s3BucketPath);
The stack name, in our case cdk-identifiers-stack-dev doesn't add any
uniqueness for resources in the same stack so it isn't used to form the
CloudFormation logical ID.
In fact, if we deploy a second stack named cdk-identifiers-stack-prod the
Cloudformation logical id of the bucket would be the exact same as in our
cdk-identifiers-stack-dev deployment.
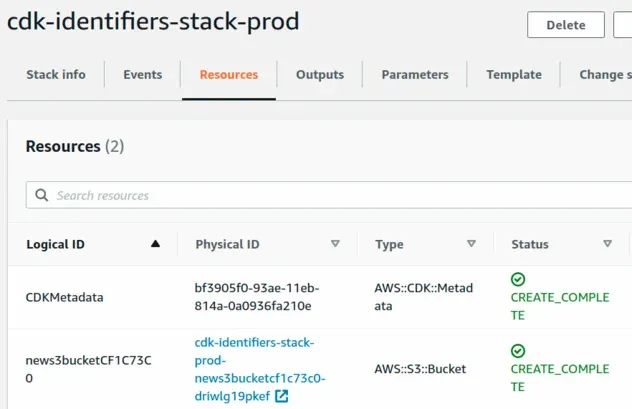
Notice how the path has the construct identifier new-s3-bucket twice. Once for
our own UploadsBucketConstruct and once for the s3.bucket construct.
However, if we look at the logical id in CloudFormation we only have
news3bucket once and then an 8-character hash.
The reason is in the implementation of the allocateLogicalId function in the
cdk code.
Since we passed in the same construct identifier to our own and the AWS Bucket constructs, the last components of the path were the same and they were de-duplicated, resulting in a more human-readable Logical ID in CloudFormation.
Now that we know how the Path is formed - starting at the root stack and going down the construct scopes, it is very important to note that refactoring your code and extracting duplicated logic into a construct might alter your path and end up altering your CloudFormation Logical IDs, which results in deleting resources and replacing them with new ones with the new logical ID.
# Unique IDs
CloudFormation only allows for identifiers that are alphanumeric -
[a-zA-Z0-9], which means the Logical IDs in CloudFormation can't contain /
characters.
However, as we saw our paths contain slash characters, i.e.
cdk-identifiers-stack-dev/new-s3-bucket/new-s3-bucket.
If we were to just join on the slash characters of the path to form the unique IDs, we could have collisions if we named our constructs like:
new-s3-bucket/new-s3-bucketnew-s3-/bucketnew-s3-bucket
Just joining the components on the / character to make our identifiers
conform to CloudFormation's requirement of only alphanumeric characters would
not prove uniqueness.
There's an unlikely scenario that the combination of IDs could still clash.
The solution the CDK team implemented is to append an 8-digit hash to the
components from the path in order to create a unique identifier. So that's
where the 5E7B98C4 part comes from in the appendix of the S3 bucket's Logical
ID:
The unique IDs are used as Cloudformation Logical IDs.
# Identifiers in CDK - Discussion
Since CDK gets compiled into CloudFormation, a good starting point is to look at the result of a CDK deployment:
In the first column of the screenshot, we can see the Logical ID of the
resources.
We can specify a resource's Logical ID in Cloudformation like so:
Resources: MyLogicalId: Type: AWS::DynamoDB::Table Properties: # ... properties of the table
This means that if we were to rename MyLogicalId to NewLogicalId, our
DynamoDB table would get deleted and a new table would get created, only without
all the records we had stored up to that point.
Resources: NewLogicalId: Type: AWS::DynamoDB::Table Properties: # ... properties of the table
If we change the ID of a Lambda function or an IAM Role, we might get some interruption, but it wouldn't be as bad as changing the logical ID of a data store like S3, Dynamodb, RDS, etc and potentially losing data (if we don't have a prevention mechanism in place).
# Conclusion
The most important thing to note about IDs in CDK is that simply refactoring your code and extracting logic into a Construct can end up altering the resource's path and logical ID.
If you change a resource's Logical ID, the resource gets deleted and a new resource with the new Logical ID gets created, which is especially important to consider when dealing with stateful components such as databases.
# Table of Contents
# The drawbacks of explicitly assigning Names in AWS CDK
When we create a CDK resource and explicitly set its name we are unable to update properties on that resource that require replacement.
If we attempt to update an immutable configuration property on a resource with an explicitly set name, our CDK Stack will be in a gridlocked state.
The only ways for us to continue development would be to delete the stack and re-create it or rename the resource.
For example, say we have the following Dynamodb table:
const table = new dynamodb.Table(this, 'todos-table', { // 👇 explicitly setting tableName tableName: 'my-table', partitionKey: {name: 'date', type: dynamodb.AttributeType.STRING}, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, removalPolicy: cdk.RemovalPolicy.DESTROY, });
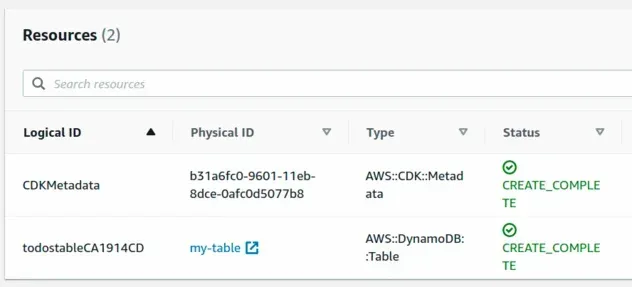
If we look at the CloudFormation stack, we can see that the Physical ID
(resource name) of the table is my-table:
Let's now update the table's partitionKey property:
const table = new dynamodb.Table(this, 'todos-table', { // 👇 explicitly setting tableName tableName: 'my-table', // 👇 updated the partition key partitionKey: {name: 'todoId', type: dynamodb.AttributeType.NUMBER}, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, removalPolicy: cdk.RemovalPolicy.DESTROY, });
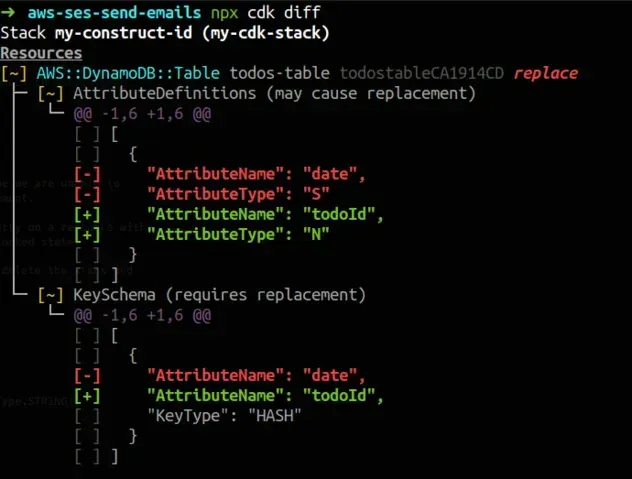
If we run npx aws-cdk diff, we see that the change we've made requires
resource replacement:
Let's now try to go through with the update and update our stack with:
npx aws-cdk deploy
As expected our update failed with the message:
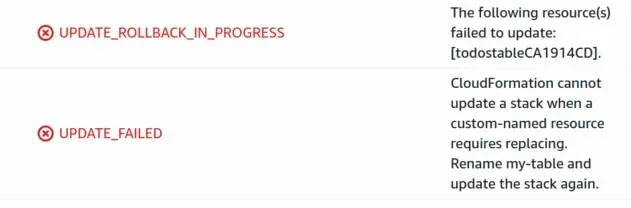
At this point, we have 2 options:
- Change the name we've set for the resource so the stack can get unstuck.
- Delete our stack and re-deploy it.
After updating the tableName property, the stack is in UPDATE_COMPLETE state
again:
const table = new dynamodb.Table(this, 'todos-table', { // 👇 updated the name to fix the stack tableName: 'my-table-2', partitionKey: {name: 'todoId', type: dynamodb.AttributeType.NUMBER}, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, removalPolicy: cdk.RemovalPolicy.DESTROY, });
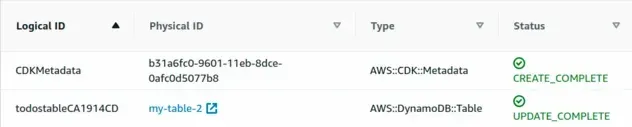
If we have to constantly keep changing our resource names every time we have to change a property that requires resource replacement, it's probably not a good idea to explicitly set resource names.
# Letting CDK generate Names for us
The solution is to let CDK generate a name for us. For example, if we omit the
tableName property:
const table = new dynamodb.Table(this, 'todos-table', { partitionKey: {name: 'todoId', type: dynamodb.AttributeType.NUMBER}, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, removalPolicy: cdk.RemovalPolicy.DESTROY, });
CDK will auto-generate a unique Physical ID (Resource name) for us that won't cause issues on consecutive updates:
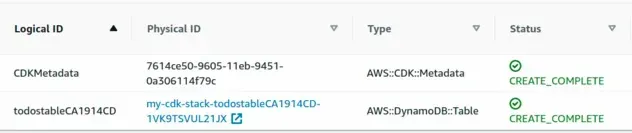
The name consists of the stack name, in this case, my-cdk-stack, the construct
id - todos-table and a hash.
# The Exception
When we need to refer to resources from another CDK stack, we have to explicitly set resource names.
The resource name that we import in one stack has to match the name of the exported resource from the other stack.
# Overriding Logical IDs in CDK
Logical IDs serve as unique resource identifiers.
Logical IDs are alphanumeric (A-Za-z0-9) and must be unique in a template.
We set the resource's logical ID in CloudFormation like so:
Resources: # 👇 logical id MyLogicalId: Type: AWS::DynamoDB::Table Properties: # ... properties of the table
If we look at a deployed stack, we can see the Logical IDs of resources in the first column:
In order to override the Logical ID of a resource in CDK, we have to use the
overrideLogicalId method on the CfnResource.
To be more specific, if we had a CfnBucket resource we would use its overrideLogicalId method.
In order to demo the process, I'll create a CDK stack, which consists of a single S3 bucket.
import * as s3 from 'aws-cdk-lib/aws-s3'; import * as cdk from 'aws-cdk-lib'; export class MyCdkStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props: cdk.StackProps) { super(scope, id, props); const s3Bucket = new s3.Bucket(this, 'avatars-bucket', { removalPolicy: cdk.RemovalPolicy.DESTROY, }); // 👇 Get access to the CfnBucket resource const cfnBucket = s3Bucket.node.defaultChild as s3.CfnBucket; // 👇 Override the bucket's logical ID cfnBucket.overrideLogicalId('myLogicalId'); } }
In the code sample:
We defined an S3 bucket using the Level 2 Bucket construct.
We got access to the Level 1
CfnBucketresource and casted the type of the value toCfnBucket.We overrode the logical ID of the bucket to
myLogicalId
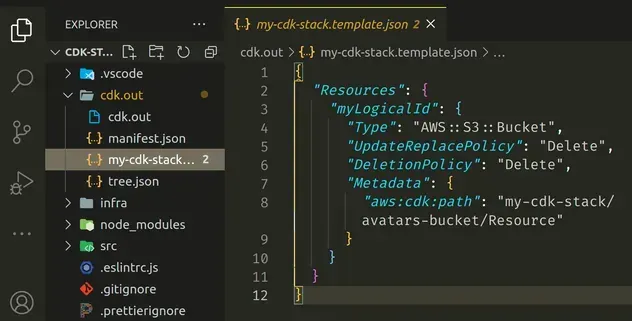
my-logical-id we would get an error: "Resource namemy-logical-id is non alphanumeric."If we take a look at the synthesized CloudFormation template in the cdk.out
directory, we can see that the Logical ID we've provided is reflected in the
CloudFormation template:
Let's look at the Logical ID of the S3 bucket in the CloudFormation console:
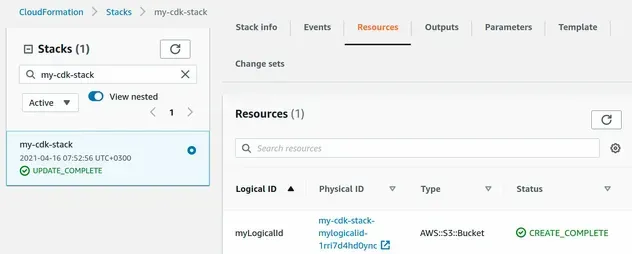
We can see that the Logical ID of the bucket has been updated to the value we
provided - myLogicalId.
If I were to change the logical ID of the bucket:
- cfnBucket.overrideLogicalId('myLogicalId'); + cfnBucket.overrideLogicalId('anotherLogicalId');
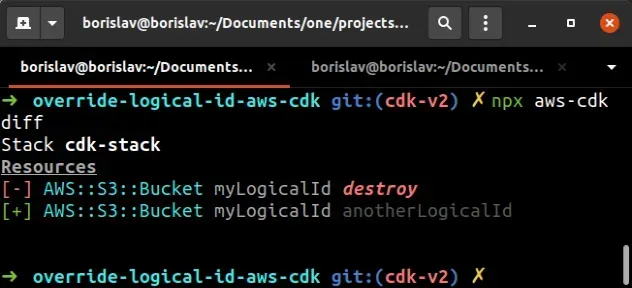
And now run the diff command:
npx aws-cdk diff
The output shows that if I were to run a deployment, my bucket with logical ID
of myLogicalId would get deleted and a new bucket with logical ID of
anotherLogicalId would get created:
We should be mindful of identifiers in CDK, especially when working with stateful resources like S3 buckets and databases.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

