Split a String into Text and Number in Python
Last updated: Apr 8, 2024
Reading time·5 min

# Table of Contents
- Split a string into text and number in Python
- Splitting each string in a list into text and number
- Split a string into text and number using a
forloop - Split a string into text and number using re.match()
- Split a string into text and number using str.rstrip()
- Split a string into text and number using re.findall()
# Split a string into text and number in Python
Use the re.split() method to split a string into text and number.
The re.split() method will split the string on the digits and will still
include them in the list.
import re my_str = 'hello123' my_list = re.split(r'(\d+)', my_str) # 👇️ ['hello', '123', ''] print(my_list)
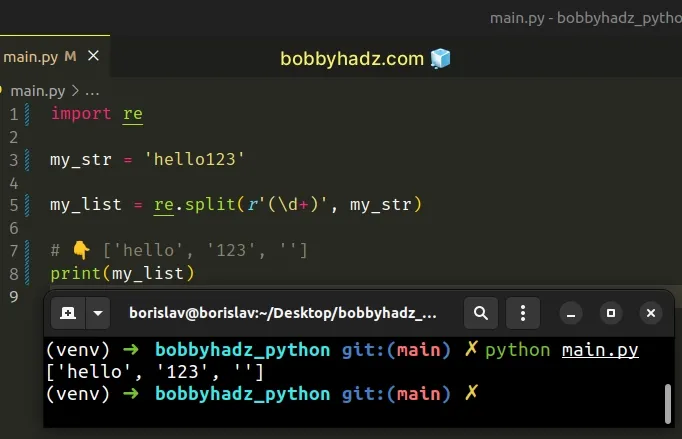
Notice that we got an empty string at the end because the last character in the string is a digit.
You can use the filter() method to
remove any empty strings from the list
if there are any.
import re my_str = 'hello123' my_list = list(filter(None, re.split(r'(\d+)', my_str))) # 👇️ ['hello', '123'] print(my_list)
The filter function takes a function and an iterable as arguments and constructs an iterator from the elements of the iterable for which the function returns a truthy value.
If you pass None for the function argument, all falsy elements of the iterable
are removed.
The re.split method takes a pattern and a string and splits the string on each occurrence of the pattern.
import re my_str = 'hello123' my_list = list(filter(None, re.split(r'(\d+)', my_str))) # 👇️ ['hello', '123'] print(my_list)
The group's contents can still be retrieved after the match.
Even though we split the string by one or more digits, we still include the digits in the result.
The \d character matches the digits in the range from 0 to 9 (and many
other digit characters).
The plus + causes the regular expression to match 1 or more repetitions of the
preceding character (the range of digits).
This approach also works if your string starts with digits and ends in characters.
import re my_str = '123hello' my_list = list(filter(None, re.split(r'(\d+)', my_str))) # 👇️ ['123', 'hello'] print(my_list)
If we didn't use the filter() function, we'd have an empty string element at
the start of the list.
Note that the filter function returns a filter object (not a list). If you
need to convert the filter object to a list, pass it to the
list() class.
# Splitting each string in a list into text and number
If you have a list of strings that you need to split into text and number, use a list comprehension.
import re my_list = ['123ab', '456cd', '789ef'] result = [ list(filter(None, re.split(r'(\d+)', item))) for item in my_list ] # 👇️ [['123', 'ab'], ['456', 'cd'], ['789', 'ef']] print(result)
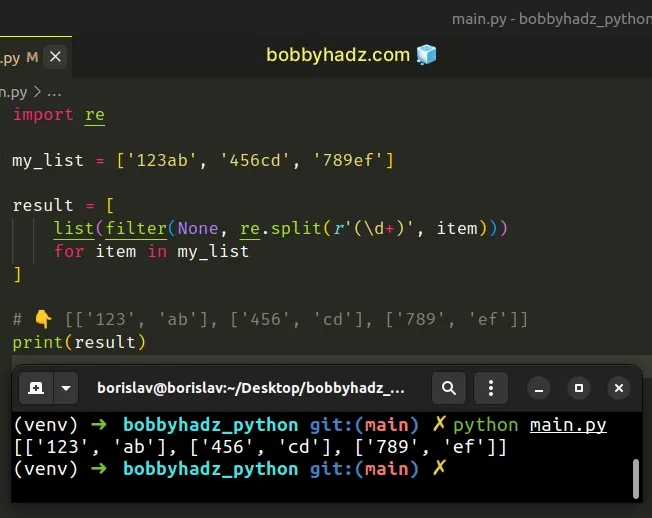
We used a
list comprehension to
iterate over the list and used the re.split() method to split each string into
text and numbers.
List comprehensions are used to perform some operation for every element or select a subset of elements that meet a condition.
# Split a string into text and number using a for loop
You can also use a for loop to split a string into text and a number.
def split_text_number(string): letters = '' numbers = '' for char in string: if char.isalpha(): letters += char elif char.isdigit(): numbers += char return [letters, numbers] print(split_text_number('abc123')) # ['abc', '123'] print(split_text_number('123abc')) # ['abc', '123']
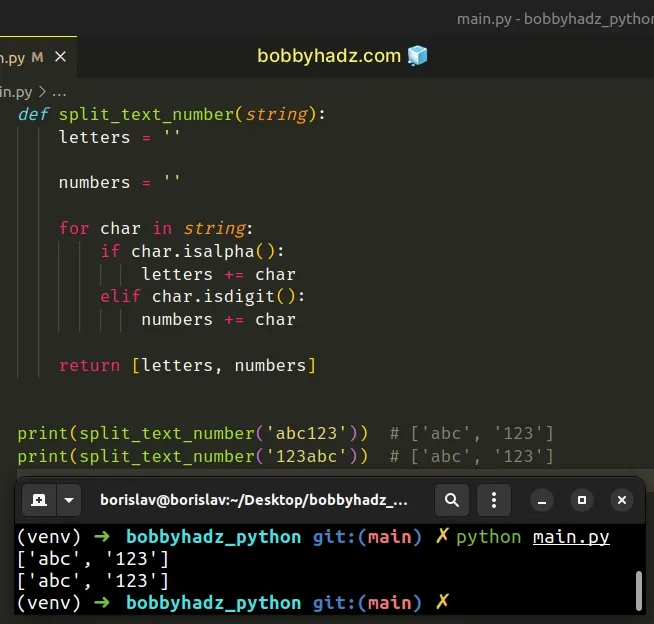
We used a for loop to iterate over the string.
The str.isalpha() method returns True if all characters in the string are
alphabetic and there is at least one character, otherwise False is returned.
print('BOBBY'.isalpha()) # 👉️ True
The str.isalpha method considers alphabetic characters as the ones that are
defined in the Unicode character database as "Letter".
The str.isdigit method returns
True if all characters in the string are digits and there is at least 1
character, otherwise False is returned.
The last step is to wrap the letters and digits into a list and return the result.
The code sample only adds the letters and numbers to the results.
Alternatively, you can just extract the numbers and return a string containing the rest.
def split_text_number(string): letters = '' numbers = '' for char in string: if char.isdigit(): numbers += char else: letters += char return [letters, numbers] print(split_text_number('abc123')) # ['abc', '123'] print(split_text_number('123abc')) # ['abc', '123'] print(split_text_number('abc123.<#')) # ['abc.<#', '123']
When using this approach, the punctuation is also added to the letters string.
# Split a string into text and number using re.match()
You can also use the re.match() method to split a string into a text and a
number.
import re my_str = 'hello123' match = re.match(r'([a-zA-Z]+)([0-9]+)', my_str) my_list = [] if match is not None: my_list = list(match.groups()) print(my_list) # 👉️ ['hello', '123']
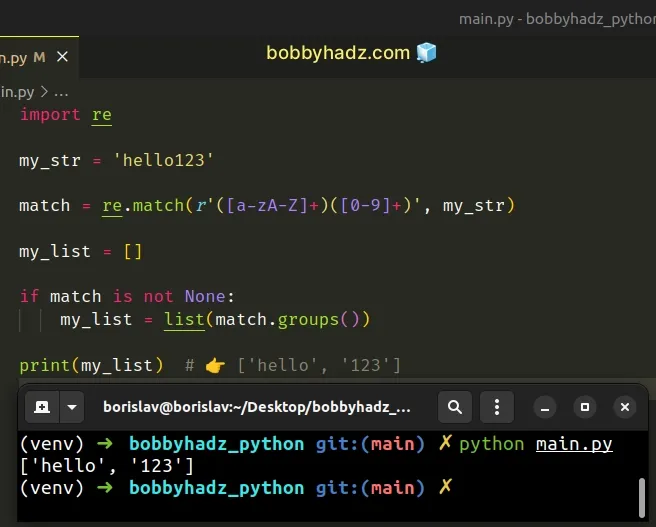
The re.match() method
returns a match object if the provided regular expression is matched in the
string.
The match() method returns None if the string
doesn't match the regex pattern.
The regular expression we passed to the match() method matches one or more
lowercase or uppercase letters followed by one or more digits.
The match.groups() method returns a tuple, so we used the list() class to
convert the result to a list.
# Split a string into text and number using str.rstrip()
You can also use the string.rstrip() method to split a string into text and a
number.
def split_into_str_num(string): letters = string.rstrip('0123456789') numbers = string[len(letters):] return [letters, numbers] my_str = 'hello123' # 👇️ ['hello', '123'] print(split_into_str_num(my_str))
The str.rstrip() method takes a string containing characters as an argument and returns a copy of the string with the specified trailing characters removed.
my_str = 'bobbyhadz.com' result = my_str.rstrip('ocm.') print(result) # 👉️ 'bobbyhadz'
We used the method to remove the digits from the end of the string and got a string containing only the letters.
The next step is to use string slicing to get the remainder of the string (the digits).
numbers = string[len(letters):]
The length of the string of letters is used to determine the start index in the slice.
# Split a string into text and number using re.findall()
You can also use the re.findall() method to split a string into text and
number.
import re def split_text_number(string): return list(re.findall(r'(\w+?)(\d+)', string)[0]) print(split_text_number('abc123')) # ['abc', '123']
The re.findall() method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
import re # 👇️ [('abc', '123')] print( re.findall(r'(\w+?)(\d+)', 'abc123') )
The \w character matches:
- characters that can be part of a word in any language
- numbers
- the underscore character
The \d character matches the digits [0-9] (and many other digit characters).
The method returns a list containing a tuple with the matches, so we accessed
the list at index 0 and converted the tuple to a list.
import re def split_text_number(string): return list(re.findall(r'(\w+?)(\d+)', string)[0]) print(split_text_number('abc123')) # ['abc', '123']
Note that this approach should not be used if your string starts with digits
because the \w character would match the digit at the start.
import re def split_text_number(string): return list(re.findall(r'(\w+?)(\d+)', string)[0]) print(split_text_number('123abc')) # ['1', '23']
I've also written an article on how to split a float into integer and decimal parts.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Split a String and remove the Whitespace in Python
- Split a String and get First or Last element in Python
- Split a string with multiple delimiters in Python
- How to Split a string by Whitespace in Python
- Split a String, Reverse it and Join it back in Python
- Split a string without removing the delimiter in Python

