How to Split a string by Whitespace in Python
Last updated: Apr 8, 2024
Reading time·9 min

# Table of Contents
- Split a string by one or more spaces in Python
- Split a string by whitespace using re.split()
- Split a string only on the first Space in Python
- Split a string into a list of words using re.findall()
- Split a string into a list of words using str.replace()
- Split a string on punctuation marks in Python
- Split a string into words and punctuation in Python
# Split a string by one or more spaces in Python
Use the str.split() method without an argument to split a string by one or
more spaces, e.g. my_str.split().
When the str.split() method is called without an argument, it considers
consecutive whitespace characters as a single separator.
my_str = 'a b \nc d \r\ne' my_list = my_str.split() print(my_list) # 👉️ ['a', 'b', 'c', 'd', 'e']
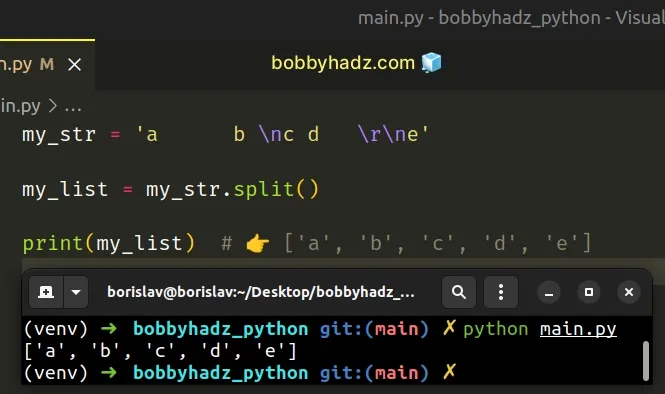
We used the str.split() method to split a string by an unknown number of
spaces (one or more).
The str.split() method splits the string into a list of substrings using a delimiter.
The method takes the following 2 parameters:
| Name | Description |
|---|---|
| separator | Split the string into substrings on each occurrence of the separator (optional) |
| maxsplit | At most maxsplit splits are done (optional) |
str.split() method is called without a separator, it considers consecutive whitespace characters as a single separator.If the string starts or ends with a trailing whitespace, the list won't contain empty string elements.
my_str = ' alice bob carl diana ' my_list = my_str.split() print(my_list) # 👉️ ['alice', 'bob', 'carl', 'diana']
This is different than passing a string containing a space for the separator to
the split() method.
my_str = ' a b \nc d \r\ne ' my_list = my_str.split(' ') print(my_list) # 👉️ ['', '', 'a', '', 'b', '\nc', 'd', '', '\r\ne', '', '']
When we pass a separator to the split() method, a different algorithm is used.
The list in the example has both leading and trailing empty string items because the string starts and ends with a space.
This approach also doesn't split on all whitespace characters, e.g. \t, \n
and \r\n, it only splits by spaces.
split() method and split an empty string or one that only contains whitespace characters, we'd get an empty list.my_str = ' ' my_list = my_str.split() print(my_list) # 👉️ []
You can also use a regular expression to split a string by one or more spaces.
# Split a string by whitespace using re.split()
You can also use the re.split() method to split a string by whitespace.
import re my_str = 'a b \nc d \r\ne' my_list = re.split(r'\s+', my_str) print(my_list) # 👉️ ['a', 'b', 'c', 'd', 'e']
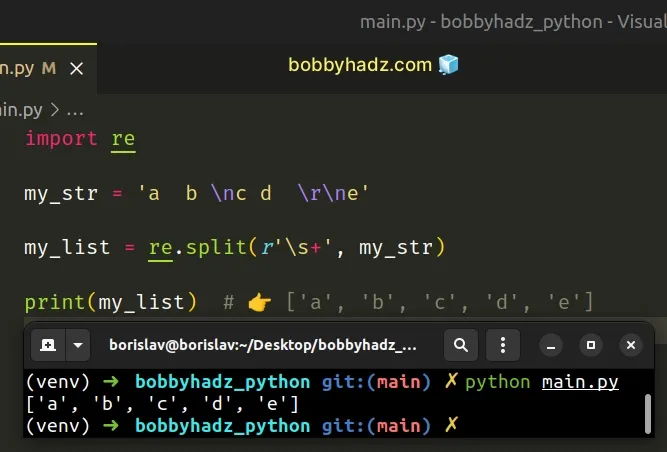
The re.split() method takes a pattern and a string and splits the string on each occurrence of the pattern.
The \s character matches Unicode whitespace characters like [ \t\n\r\f\v].
The plus + is used to match the preceding character (whitespace) 1 or more
times.
In its entirety, the regular expression matches one or more whitespace characters.
When using this approach, you would get empty string elements if your string starts with or ends with whitespace.
import re my_str = ' a b \nc d \r\ne ' my_list = re.split(r'\s+', my_str) print(my_list) # 👉️ ['', 'a', 'b', 'c', 'd', 'e', '']
You can use the filter() function to
remove any empty strings from the list.
import re my_str = ' a b \nc d \r\ne ' my_list = list(filter(None, re.split(r'\s+', my_str))) print(my_list) # 👉️ ['a', 'b', 'c', 'd', 'e']
The filter function takes a function and an iterable as arguments and constructs an iterator from the elements of the iterable for which the function returns a truthy value.
None for the function argument, all falsy elements of the iterable are removed.Note that the filter() function returns a filter object, so we have to use
the list() class to convert the filter
object to a list.
# Split a string only on the first Space in Python
You can also use the split() method to split a string only on the first space.
my_str = 'one two three four' # 👇️ split string only on first space my_list = my_str.split(' ', 1) print(my_list) # 👉️ ['one', 'two three four'] # 👇️ split string only on first whitespace char my_list_2 = my_str.split(maxsplit=1) print(my_list_2) # 👉️ ['one', 'two three four']
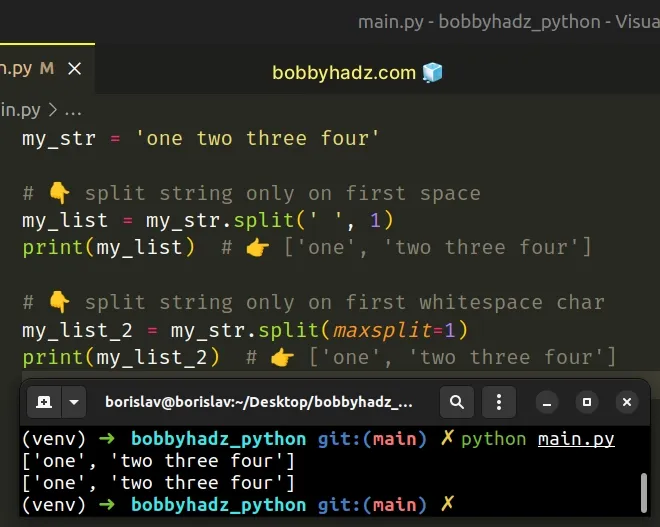
The str.split() method splits the string into a list of substrings using a delimiter.
The method takes the following 2 parameters:
| Name | Description |
|---|---|
separator | Split the string into substrings on each occurrence of the separator |
maxsplit | At most maxsplit splits are done (optional) |
maxsplit argument is set to 1, at most 1 split is done.If the separator is not found in the string, a list containing only 1 element is returned.
my_str = 'one' my_list = my_str.split(' ', 1) print(my_list) # 👉️ ['one']
If your string starts with a space, you might get a confusing result.
my_str = ' one two three four ' # 👇️ split string only on first space my_list = my_str.split(' ', 1) print(my_list) # 👉️ ['', 'one two three four ']
You can use the str.strip() method to remove the leading or trailing
separator.
my_str = ' one two three four ' # 👇️ split string only on first space my_list = my_str.strip(' ').split(' ', 1) print(my_list) # 👉️ ['one', 'two three four']
We used the str.strip() method to remove any leading or trailing spaces from
the string before calling the split() method.
If you need to split a string only on the first whitespace character, don't
provide a value for the separator argument when calling the str.split()
method.
my_str = 'one\r\ntwo three four' # 👇️ Split string only on first whitespace char my_list = my_str.split(maxsplit=1) print(my_list) # 👉️ ['one', 'two three four']
str.split() method is called without a separator, it considers consecutive whitespace characters as a single separator.If the string starts or ends with a trailing whitespace, the list won't contain empty string elements.
my_str = ' one\r\ntwo three four ' # 👇️ split string only on first whitespace char my_list = my_str.split(maxsplit=1) print(my_list) # 👉️ ['one', 'two three four ']
This approach is useful when you want to split on the first whitespace character (including tabs, newline chars, etc), not just the first space.
# Split a string into a list of words using re.findall()
You can also use the re.findall() method to split a string into a list of
words.
import re my_str = 'one two, three four. five' my_list = re.findall(r'[\w]+', my_str) print(my_list) # 👉️ ['one', 'two', 'three', 'four', 'five']
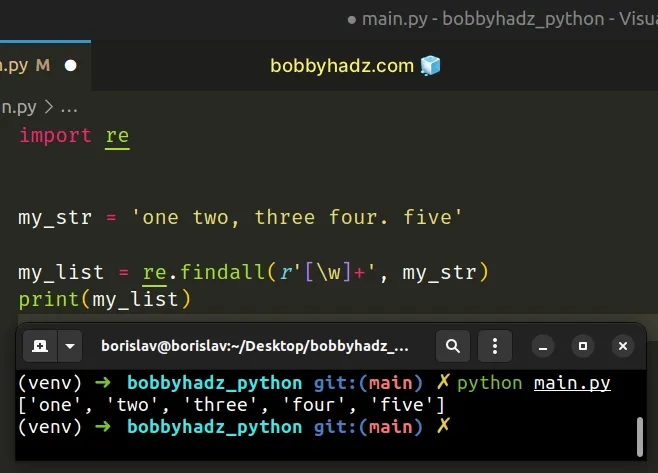
The re.findall() method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
The first argument we passed to the re.findall() method is a regular
expression.
The square [] brackets are used to indicate a set of characters.
\w character matches Unicode word characters and includes most characters that can be part of a word in any language.The plus + causes the regular expression to match 1 or more repetitions of the
preceding character (the Unicode characters).
The re.findall() method returns a list containing the words in the string.
If you ever need help reading or writing a regular expression, consult the regular expression syntax subheading in the official docs.
The page contains a list of all of the special characters with many useful examples.
If you need a more flexible approach, you can use the str.replace() method to
remove specific characters from the string before splitting.
# Split a string into a list of words using str.replace()
This is a three-step process:
- Use the
str.replace()method to remove any punctuation from the string. - Use the
str.split()method to split the string on one or more whitespace characters. - The
str.split()method will return a list containing the words.
my_str = 'one two, three four. five' my_list = my_str.replace(',', '').replace('.', '').split() print(my_list) # 👉️ ['one', 'two', 'three', 'four', 'five']
We used the str.replace() method to remove the punctuation before splitting
the string on whitespace characters.
The str.replace() method returns a copy of the string with all occurrences of a substring replaced by the provided replacement.
The method takes the following parameters:
| Name | Description |
|---|---|
| old | The substring we want to replace in the string |
| new | The replacement for each occurrence of old |
| count | Only the first count occurrences are replaced (optional) |
The str.replace() method doesn't change the original string. Strings are
immutable in Python.
You can chain as many calls to the str.replace() method as necessary.
The last step is to use the str.split() method to split the string into a list
of words.
If you need to remove all punctuation when splitting the string into words, use
the str.strip() method on each word.
import string # 👇️ !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ print(string.punctuation) my_str = 'one two, three four. five' my_list = [word.strip(string.punctuation) for word in my_str.split()] print(my_list) # 👉️ ['one', 'two', 'three', 'four', 'five']
We used the str.strip() method to strip the leading and trailing punctuation
characters from each word.
string.punctuation attribute returns a string that contains commonly used punctuation characters.We used a
list comprehension to
iterate over the list of words and called the str.strip() method on each word.
List comprehensions are used to perform some operation for every element or select a subset of elements that meet a condition.
The str.strip method returns a copy of the string with the specified leading and trailing characters removed.
# Split a string on punctuation marks in Python
Use the re.split() method to split a string on punctuation marks.
import re my_str = """One, Two Three. Four! Five? I'm!""" my_list = re.split('[,.!?]', my_str) # 👇️ ['One', ' Two Three', ' Four', ' Five', " I'm", ''] print(my_list)
The re.split method takes a pattern and a string and splits the string on each
occurrence of the pattern.
Notice that some of the items in the list contain spaces. If you need to remove the spaces, add a space between the square brackets of the regular expression.
import re my_str = """One, Two Three. Four! Five? I'm!""" my_list = re.split('[ ,.!?]', my_str) # 👇️ ['One', '', 'Two', 'Three', '', 'Four', '', 'Five', '', "I'm", ''] print(my_list)
Now our regex matches spaces as well. If you need to remove the empty strings
from the list, use the filter() function.
import re my_str = """One, Two Three. Four! Five? I'm!""" my_list = list(filter(None, re.split('[ ,.!?]', my_str))) # 👇️ ['One', 'Two', 'Three', 'Four', 'Five', "I'm"] print(my_list)
The filter function takes a function and an iterable as arguments and constructs an iterator from the elements of the iterable for which the function returns a truthy value.
None for the function argument, all falsy elements of the iterable are removed.The square brackets [] are used to indicate a set of characters.
The set of characters in the example includes a comma ,, a dot ., an
exclamation mark ! and a question mark ?.
You can add any other punctuation marks between the square brackets, e.g. a
colon :, a semicolon ;, brackets or parentheses.
import re my_str = """One, Two: Three;. Four! Five? I'm!""" my_list = list(filter(None, re.split('[ :;,.!?]', my_str))) # 👇️ ['One', 'Two', 'Three', 'Four', 'Five', "I'm"] print(my_list)
Note that the filter() function returns a filter object (not a list). If you
need to convert the filter object to a list, pass it to the list() class.
# Split a string into words and punctuation in Python
You can also use the re.findall() method to split a string into words and
punctuation.
import re my_str = """One, "Two" Three. Four! Five? I'm """ result = re.findall(r"[\w'\"]+|[,.!?]", my_str) # 👇️ ['One', ',', '"Two"', 'Three', '.', 'Four', '!', 'Five', '?', "I'm"] print(result)
The re.findall() method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
The square brackets [] are used to indicate a set of characters.
\w character matches most characters that can be part of a word in any language, as well as numbers and underscores.If the ASCII flag is set, the \w character matches [a-zA-Z0-9_].
Our set of characters also includes a single and double quote.
import re my_str = """One, "Two" Three. Four! Five? I'm """ result = re.findall(r"[\w'\"]+|[,.!?]", my_str) # 👇️ ['One', ',', '"Two"', 'Three', '.', 'Four', '!', 'Five', '?', "I'm"] print(result)
If you want to exclude single or double quotes from the results, remove the '
and \" characters from between the square brackets.
The + matches the preceding character 1 or more times.
The pipe | character is an OR. Either match A or B.
The second set of square brackets matches punctuation - a comma, a dot, an exclamation mark and a question mark.
You can add any other punctuation marks between the square brackets, e.g. a
colon :, a semicolon ;, brackets or parentheses.
You can tweak the regular expression according to your use case. This section of the docs has information regarding what each special character does.
Here is the complete code snippet.
import re my_str = """One, "Two" Three. Four! Five? I'm """ # result = re.findall(r"[\w'\"]+|[,.!?]", my_str) result = re.findall(r"[\w]+|[,.!?]", my_str) # 👇️ ['One', ',', '"Two"', 'Three', '.', 'Four', '!', 'Five', '?', "I'm"] print(result)
I've also written an article on how to split a string and remove the whitespace.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Split a String and get First or Last element in Python
- Split a String into a List of Integers in Python
- Split a String into multiple Variables in Python
- Split a String into Text and Number in Python
- Split a string with multiple delimiters in Python
- Split a String, Reverse it and Join it back in Python
- Split a string without removing the delimiter in Python

