Filter a List of Strings using a Wildcard in Python
Last updated: Apr 10, 2024
Reading time·5 min

# Table of Contents
- Filter a list of strings using a Wildcard in Python
- Check if a string matches a pattern using a wildcard
- Filter a list of strings using a Wildcard with a regex
- Check if a string matches a pattern using a regex
# Filter a list of strings using a Wildcard in Python
To filter a list of strings using a wildcard:
- Pass the list and the pattern with the wildcard to the
fnmatch.filter()method. - The
fnmatch.filter()method will return a new list containing only the elements that match the pattern.
import fnmatch a_list = ['abc_bobby.csv', 'hadz', '!@#', 'abc_employees.csv'] pattern = 'abc_*.csv' filtered_list = fnmatch.filter(a_list, pattern) print(filtered_list) # 👉️ ['abc_bobby.csv', 'abc_employees.csv']
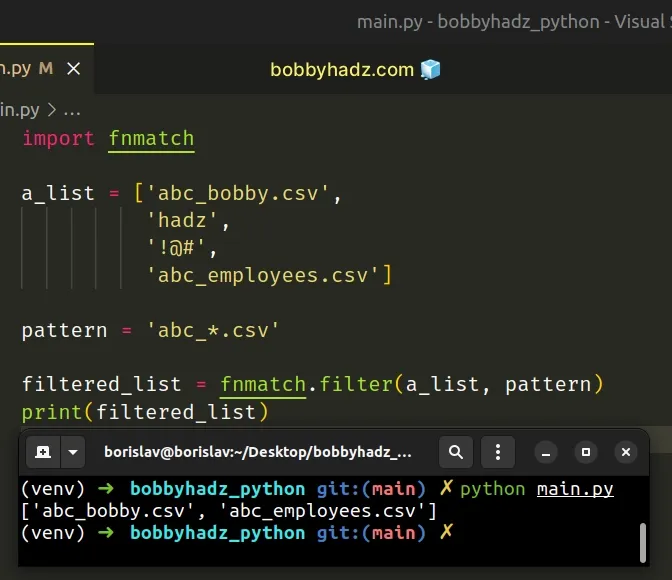
The fnmatch.filter() method takes an iterable and a pattern and returns a new list containing only the elements of the iterable that match the provided pattern.
The pattern in the example matches strings that start with abc_ and end with
.csv.
Note that the asterisk * matches everything (one or more characters).
If you want to match any single character, replace the asterisk * with a
question mark ?.
| Pattern | Meaning |
|---|---|
* | Matches everything (one or more characters) |
? | Matches any single character |
| [sequence] | Matches any character in sequence |
| [!sequence] | Matches any character not in sequence |
Here is an example of using the question mark to match any single character.
import fnmatch a_list = ['abc', 'abz', 'abxyz'] pattern = 'ab?' filtered_list = fnmatch.filter(a_list, pattern) print(filtered_list) # 👉️ ['abc', 'abz']
The pattern matches a string that starts with ab followed by any single
character.
Here is an example of a pattern that uses two wildcard characters.
import fnmatch a_list = ['abc_bobby.csv', 'hadz', '!@#', 'abc_employees.txt'] pattern = 'abc_*.*' filtered_list = fnmatch.filter(a_list, pattern) print(filtered_list) # 👉️ ['abc_bobby.csv', 'abc_employees.txt']
The pattern starts with abc_, has a dot . and then ends with any character.
You can also use the fnmatch.fnmatch() method instead of the
fnmatch.filter() method.
import fnmatch import re a_list = ['abc_bobby.csv', 'hadz', '!@#', 'abc_employees.csv'] pattern = 'abc_*.csv' filtered_list = [ item for item in a_list if fnmatch.fnmatch(item, pattern) ] print(filtered_list) # 👉️ ['abc_bobby.csv', 'abc_employees.csv']
The fnmatch.fnmatch() method takes a string and a pattern as arguments.
The method returns True if the string matches the pattern and False
otherwise.
We used a
list comprehension to
iterate over the list of strings and called the fnmatch.fnmatch() method on
each string in the list.
The new list only contains the strings that match the pattern.
# Check if a string matches a pattern using a wildcard
If you want to check if a string matches a pattern using a wildcard, use the
fnmatch.fnmatch() method.
import fnmatch a_string = '2023_bobby.txt' pattern = '2023*.txt' matches_pattern = fnmatch.fnmatch(a_string, pattern) print(matches_pattern) # 👉️ True if matches_pattern: # 👇️ this runs print('The string matches the pattern') else: print('The string does NOT match the pattern')
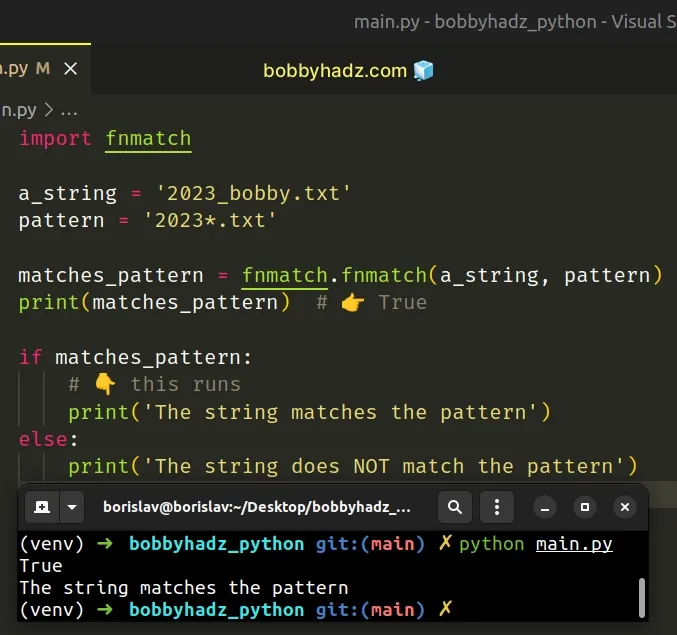
The pattern starts with 2023 followed by any one or more characters and ends
with .txt.
* with a question mark ? if you want to match any single character instead of any one or more characters.Alternatively, you can use a regular expression.
# Filter a list of strings using a Wildcard with a regex
This is a three-step process:
- Use a list comprehension to iterate over the list.
- Use the
re.match()method to check if each string matches the pattern. - The new list will only contain the strings that match the pattern.
import re a_list = ['abc_bobby.csv', 'hadz', '!@#', 'abc_employees.csv'] regex = re.compile(r'abc_.*\.csv') filtered_list = [ item for item in a_list if re.match(regex, item) ] print(filtered_list) # 👉️ ['abc_bobby.csv', 'abc_employees.csv']
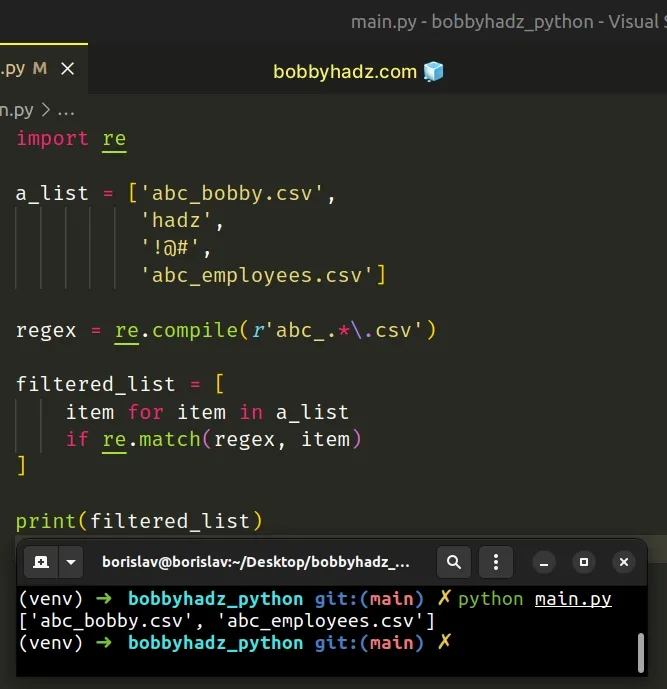
The re.compile() method
compiles a regular expression pattern into an object, which can be used for
matching using its match() or search() methods.
This is more efficient than using re.match or re.search directly because it
saves and reuses the regular expression object.
The regular expression in the example starts with abc_.
regex = re.compile(r'abc_.*\.csv')
The dot . matches any character except a newline character.
The asterisk * matches the preceding regular expression (the dot .) zero or
more times.
.*.If you only want to match a single character, you would use a dot . without
the asterisk *.
We used a backslash \ character to escape the dot . in the extension because
as we previously saw, the dot . has a special meaning when used in regular
expressions.
In other words, we used a backslash to treat the dot . as the literal
character.
We used a list comprehension to iterate over the list of strings.
On each iteration, we use the re.match() method to check if the current string
matches the pattern.
import re a_list = ['abc_bobby.csv', 'hadz', '!@#', 'abc_employees.csv'] regex = re.compile(r'abc_.*\.csv') filtered_list = [ item for item in a_list if re.match(regex, item) ] print(filtered_list) # 👉️ ['abc_bobby.csv', 'abc_employees.csv']
The re.match() method
returns a match object if the provided regular expression is matched in the
string.
The match() method returns None if the string
doesn't match the regex pattern.
The new list only contains the strings from the original list that match the pattern.
# Only matching a single character
If you only want to match any single character, remove the asterisk * after
the dot . in the regular expression.
import re a_list = ['2023_a.txt', '2023_bcde.txt', '2023_z.txt'] regex = re.compile(r'2023_.\.txt') list_of_matches = [ item for item in a_list if re.match(regex, item) ] print(list_of_matches) # 👉️ ['2023_a.txt', '2023_z.txt']
The dot . matches any character except a newline character.
. without escaping it, the regular expression matches any string that starts with 2023_ and is followed by any single character and ends with .txt.# Check if a string matches a pattern using a regex
If you want to check if a string matches a pattern using a regex, you would use
the re.match() method directly.
import re a_string = '2023_bobby.txt' matches_pattern = bool(re.match(r'2023_.*\.txt', a_string)) print(matches_pattern) # 👉️ True if matches_pattern: # 👇️ this runs print('The string matches the pattern') else: print('The string does NOT match the pattern')
The re.match() method will either return a match object if the string
matches the pattern or None if it doesn't.
We used the bool() class to convert the result to a boolean value.
If you want to use a wildcard for a single character, remove the asterisk *.
import re a_string = '2023_ABC.txt' matches_pattern = bool(re.match(r'2023_.\.txt', a_string)) print(matches_pattern) # 👉️ False if matches_pattern: print('The string matches the pattern') else: # 👇️ this runs print('The string does NOT match the pattern')
Note that the dot . that we didn't prefix with a backslash is used to match
any single character, whereas the dot . that we prefixed with a backslash \
is treated as a literal dot.
The string from the example doesn't match the pattern, so the matches_pattern
variable stores a False value.
If you ever need help reading or writing a regular expression, consult the regular expression syntax subheading in the official docs.
The page contains a list of all of the special characters with many useful examples.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Get the first character of each string in a List in Python
- How to sum a List of Strings in Python
- Split a String into a List of Integers in Python
- Remove punctuation from a List of strings in Python
- How to remove Quotes from a List of Strings in Python
- Remove all Empty Strings from a List of Strings in Python
- Join a List of Integers into a String in Python

