How to Remove URLs from Text in Python
Last updated: Apr 9, 2024
Reading time·3 min

# Remove URLs from Text in Python
Use the re.sub() method to remove URLs from text. The re.sub() method will
remove any URLs from the string by replacing them with empty strings.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
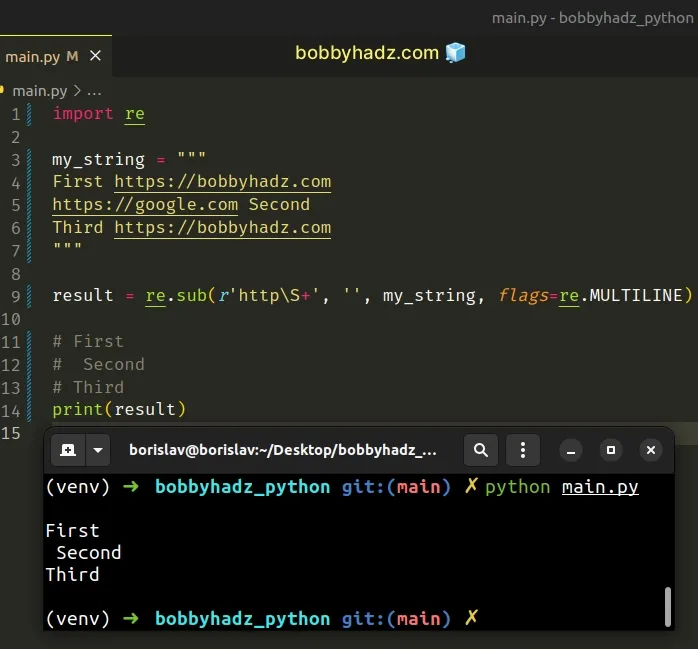
We used the re.sub() method to remove all URLs from a string.
The re.sub method returns a new string that is obtained by replacing the occurrences of the pattern with the provided replacement.
import re my_str = '1apple, 2apple, 3banana' result = re.sub(r'[0-9]', '_', my_str) print(result) # 👉️ _apple, _apple, _banana
If the pattern isn't found, the string is returned as is.
We used an empty string for the replacement because we want to remove all URLs from the string.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
The first argument we passed to the re.sub() method is a regular expression.
The http characters in the regex match the literal characters.
\S matches any character that is not a whitespace character. Notice that the
S is uppercase.
The plus + matches the preceding character (any non-whitespace character) 1 or
more times.
http follows by 1 or more non-whitespace characters.# Making the regex more specific
If you worry about matching strings in the form of http-something, update your
regular expression to r'https?://\S+'.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'https?://\S+', '', my_string) # First # Second # Third print(result)
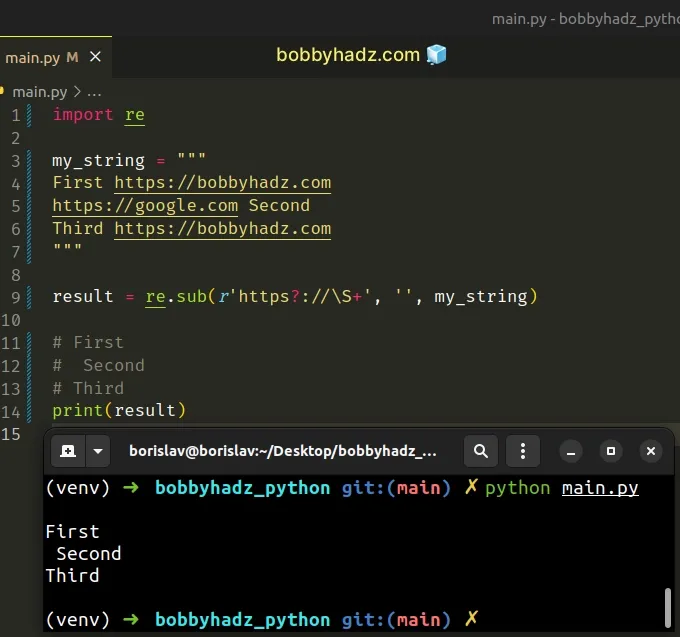
? causes the regular expression to match 0 or 1 repetitions of the preceding character.For example, https? will match either https or http.
We then have the colon and two forward slashes :// to complete the protocol.
In its entirety, the regular expression matches substrings starting with
http:// or https:// followed by 1 or more non-whitespace characters.
If you ever need help reading or writing a regular expression, consult the regular expression syntax subheading in the official docs.
The page contains a list of all of the special characters with many useful examples.
# Remove URLs from Text using re.findall()
You can also use the re.findall() method to remove the URLs from a string.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ new_string = my_string matches = re.findall(r'http\S+', my_string) print(matches) for match in matches: new_string = new_string.replace(match, '') # First # Second # Third print(new_string)
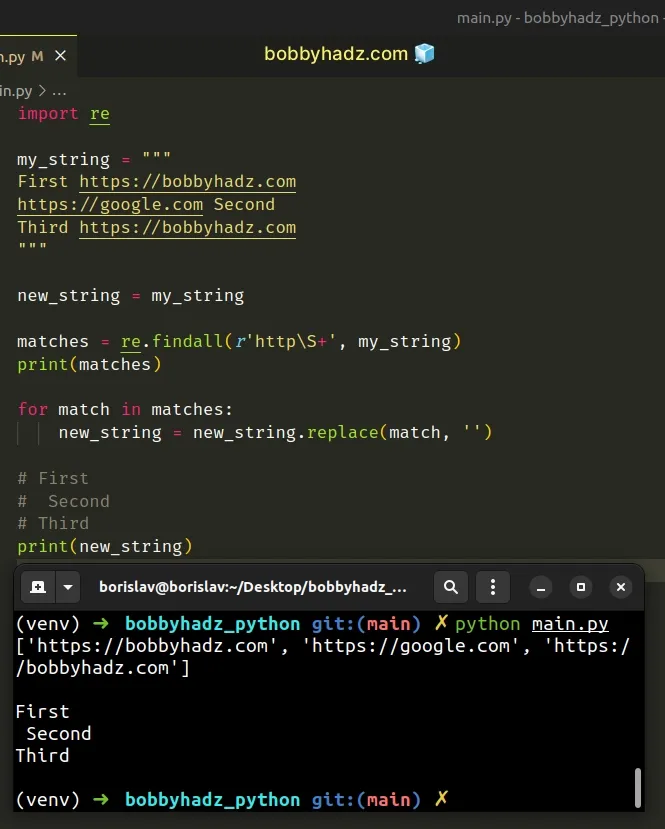
The re.findall() method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
We used a for loop to iterate over the list of matches.
On each iteration, we use the str.replace method to remove the current match
from the URL.
You would use this approach if you want to keep some of the URLs in the text based on a condition.
Here is an example.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ new_string = my_string matches = re.findall(r'http\S+', my_string) print(matches) for match in matches: if 'google' not in match: new_string = new_string.replace(match, '') # First # https://google.com Second # Third print(new_string)
On each iteration of the for loop, we check if the current match doesn't
contain the string google.
If the condition is met, the URL is removed.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove punctuation from a List of strings in Python
- How to remove Quotes from a List of Strings in Python
- Remove characters matching Regex from a String in Python
- Remove special characters except Space from String in Python
- Remove square brackets from a List or a String in Python
- How to Remove the Tabs from a String in Python
- Remove Newline characters from a List or a String in Python
- Remove non-alphanumeric characters from a Python string
- Remove non-ASCII characters from a string in Python
- Remove the non utf-8 characters from a String in Python
- How to Remove \xa0 from a String in Python
- How to Remove \ufeff from a String in Python
- How to decode URL and Form parameters in Python

