How to decode URL and Form parameters in Python
Last updated: Apr 13, 2024
Reading time·2 min

# Decoding URL parameters and Form parameters in Python
Use the unquote() method from the urllib.parse module to decode URL
parameters in Python.
The method replaces %xx escapes with their single-character equivalent.
from urllib.parse import unquote url = 'https://bobbyhadz.com/blog%3Fpage%3D1%26offset%3D10' # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(unquote(url))

The
urllib.parse.unquote()
method takes a string as a parameter and replaces the %xx escapes in the
string with their single-character equivalent.
The method also takes an optional encoding argument which defaults to utf-8.
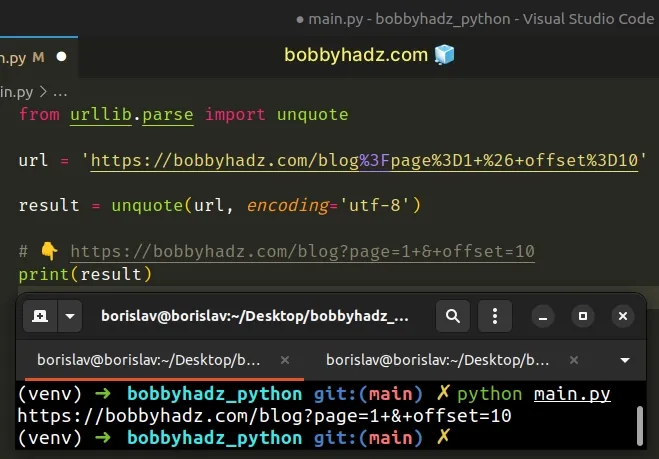
from urllib.parse import unquote url = 'https://bobbyhadz.com/blog%3Fpage%3D1%26offset%3D10' # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(unquote(url, encoding='utf-8'))

The query parameters in the string are UTF-8 encoded bytes that are escaped with
URL quoting, so the unquote() method is able to decode the string.
The urllib.parse.unquote() method automatically decodes the bytes into a
string literal.
This would also work if you only had a UTF-8 encoded bytes and not an entire URL.
from urllib.parse import unquote a_str = '%3Fpage%3D1%26offset%3D10' # 👇️ ?page=1&offset=10 print(unquote(a_str, encoding='utf-8'))

# Replacing plus signs with spaces with unquote_plus()
If you also need to replace plus signs with spaces, as required for decoding HTML form values, use the urllib.parse.unquote_plus method.
from urllib.parse import unquote_plus url = 'https://bobbyhadz.com/blog%3Fpage%3D1+%26+offset%3D10' result = unquote_plus(url, encoding='utf-8') # 👇️ https://bobbyhadz.com/blog?page=1 & offset=10 print(result)

Notice that each plus + character is replaced with a space when using the
unquote_plus() method.
This is not the case when using unquote().
from urllib.parse import unquote url = 'https://bobbyhadz.com/blog%3Fpage%3D1+%26+offset%3D10' result = unquote(url, encoding='utf-8') # 👇️ https://bobbyhadz.com/blog?page=1+&+offset=10 print(result)
# If your input is double-encoded, use unquote() twice
If your input is double-encoded, you might still get illegible results after
calling unquote().
from urllib.parse import unquote url = 'https://bobbyhadz.com/blog%253Fpage%253D1%2526offset%253D10' result = unquote(url, encoding='utf-8') # 👇️ https://bobbyhadz.com/blog%3Fpage%3D1%26offset%3D10 print(result)

The input in the example is double-encoded, so we have to call unquote()
twice.
from urllib.parse import unquote url = 'https://bobbyhadz.com/blog%253Fpage%253D1%2526offset%253D10' result = unquote(unquote(url)) # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(result)

We called the unquote() method twice and successfully decoded the URL
parameters.
If you also need to replace plus signs with spaces, as required for decoding HTML form values, use the urllib.parse.unquote_plus method.
from urllib.parse import unquote_plus url = 'https://bobbyhadz.com/blog%253Fpage%253D1%2526offset%253D10' result = unquote_plus(unquote_plus(url)) # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(result)
# Use urllib.unquote in Python 2
If you use Python 2, import the unquote method from the urllib module.
# ⛔️ Only for Python 2 from urllib import unquote url = 'https://bobbyhadz.com/blog%3Fpage%3D1%26offset%3D10' # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(unquote(url).decode('utf-8'))
After passing the URL to urllib.unquote(), we used the
bytes.decode method to decode the
bytes into a string.
# Using the requests module to decode URL and form parameters
You can also use the requests module to decode URL and form parameters.
First, make sure that you
have the requests module installed.
pip install requests # or with pip3 pip3 install requests
Now, import the module and use the requests.utils.unquote() method.
import requests url = 'https://bobbyhadz.com/blog%3Fpage%3D1%26offset%3D10' result = requests.utils.unquote(url) # 👇️ https://bobbyhadz.com/blog?page=1&offset=10 print(result)

This approach also works in Python 2.
Using the requests.utils.unquote() method is generally only recommended if you
already have the requests module installed.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

