Remove the non utf-8 characters from a String in Python
Last updated: Apr 9, 2024
Reading time·2 min

# Remove the non utf-8 characters from a String in Python
To remove the non utf-8 characters from a string:
- Use the
str.encode()method to encode the string to a bytes object. - Set the
errorskeyword argument toignoreto drop any non utf-8 characters. - Use the
bytes.decode()method to decode the bytes object to a string.
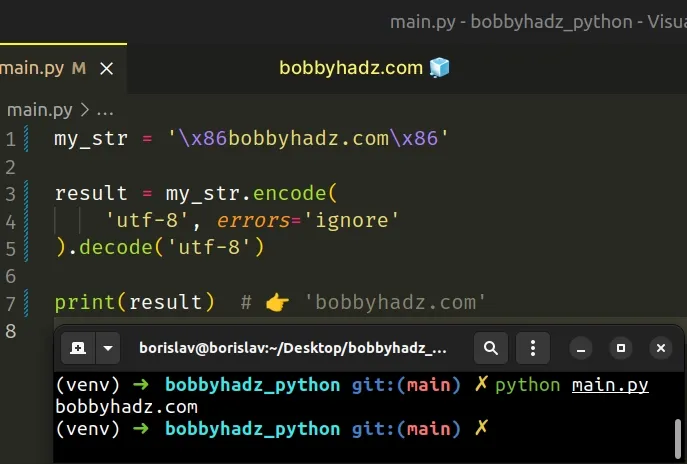
my_str = '\x86bobbyhadz.com\x86' result = my_str.encode( 'utf-8', errors='ignore' ).decode('utf-8') print(result) # 👉️ 'bobbyhadz.com'
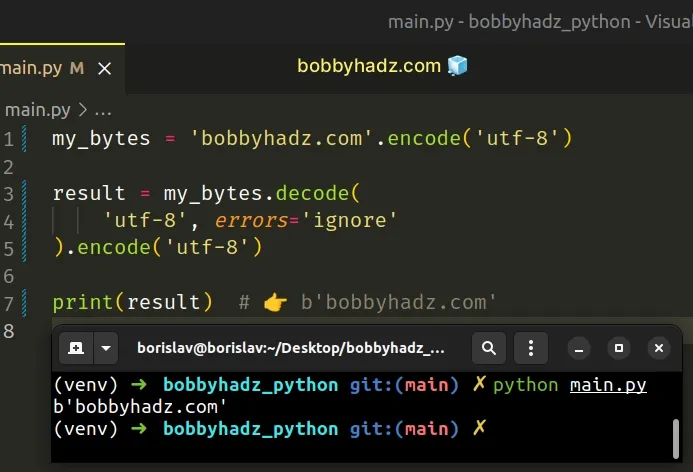
If you are starting with a bytes object, use the following code sample instead.
my_bytes = 'bobbyhadz.com'.encode('utf-8') result = my_bytes.decode( 'utf-8', errors='ignore' ).encode('utf-8') print(result) # 👉️ b'bobbyhadz.com'
The example removes the non utf-8 characters from a string.
The str.encode() method returns an
encoded version of the string as a bytes object. The default encoding is
utf-8.
errors keyword argument is set to ignore, characters that cannot be encoded are dropped.Any characters that cannot be encoded using the utf-8 encoding will get
dropped from the string.
The next step is to decode the bytes object using the utf-8 encoding.
my_str = 'abc' result = my_str.encode('utf-8', errors='ignore').decode('utf-8') print(result) # 👉️ 'abc'
The bytes.decode() method returns a
string decoded from the given bytes. The default encoding is utf-8.
The result is a string that doesn't contain any non utf-8 characters.
# Remove the non utf-8 characters from a File
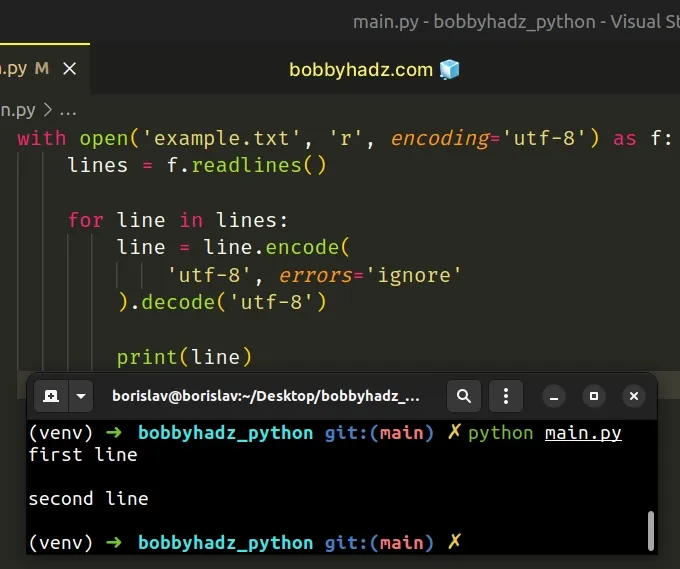
If you need to remove the non-utf-8 characters when reading from a file, use a
for loop to iterate over the lines in the file and repeat the same process.
with open('example.txt', 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: line = line.encode( 'utf-8', errors='ignore' ).decode('utf-8') print(line)
The code sample assumes that you have an example.txt file located in the same
directory as your Python script.
string to a bytes object and decoding is the process of converting a bytes object to a string.# Remove the non utf-8 characters when starting with a Bytes object
If you are starting with a bytes object, you have to use the decode() method
to decode the bytes object to a string first.
my_bytes = 'bobbyhadz.com'.encode('utf-8') result = my_bytes.decode('utf-8', errors='ignore').encode('utf-8') print(result) # 👉️ b'bobbyhadz.com'
Make sure to set the errors keyword argument to ignore in the call to the
decode() method to drop any non-utf-8 characters when converting to a string.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove Newline characters from a List or a String in Python
- Remove non-alphanumeric characters from a Python string
- Remove non-ASCII characters from a string in Python
- Remove punctuation from a List of strings in Python
- How to remove Quotes from a List of Strings in Python
- Remove characters matching Regex from a String in Python
- Remove special characters except Space from String in Python
- Remove square brackets from a List or a String in Python
- How to Remove the Tabs from a String in Python

