Remove the Tabs from a String or split by Tab in Python
Last updated: Apr 9, 2024
Reading time·7 min

# Table of Contents
- Remove the tabs from a String in Python
- Remove spaces, tabs and newlines from a String in Python
- Split a string by tab in Python
# Remove the tabs from a String in Python
To remove the tabs from a string:
- Use the
split()method to split the string on each whitespace. - Use the
join()method to join the list of strings. - The new string won't contain any tabs.
my_str = 'bobby\thadz\tcom' result = ' '.join(my_str.split()) print(repr(result)) # 👉️ 'bobby hadz com' result = ''.join(my_str.split()) print(repr(result)) # 👉️ 'bobbyhadzcom'
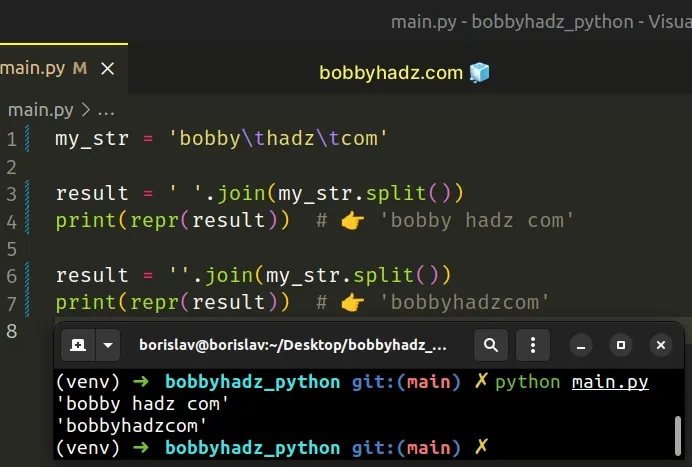
We used the str.split() method to split the string on one or more consecutive
tabs or spaces.
my_str = 'bobby\thadz\tcom' print(my_str.split()) # 👉️ ['bobby', 'hadz', 'com']
The str.split() method splits the string into a list of substrings using a delimiter.
split() method splits the string on one or more whitespace characters (including tabs).The last step is to join the list of strings into a string with a space separator.
my_str = 'bobby\thadz\tcom' result = ' '.join(my_str.split()) print(repr(result)) # 👉️ 'bobby hadz com'
The str.join method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
We called the method on a string containing a space to join the list of strings with a space separator.
# Remove the tabs from a String using replace()
Alternatively, you can use the replace() method.
The replace method will remove the tabs from the string by replacing them with
empty strings.
my_str = 'bobby\thadz\tcom' # ✅ remove tabs from the string result_1 = my_str.replace('\t', '') print(repr(result_1)) # 👉️ 'bobbyhadzcom' # ✅ replace tabs with a space in the string result_2 = my_str.replace('\t', ' ') print(repr(result_2)) # 👉️ 'bobby hadz com'
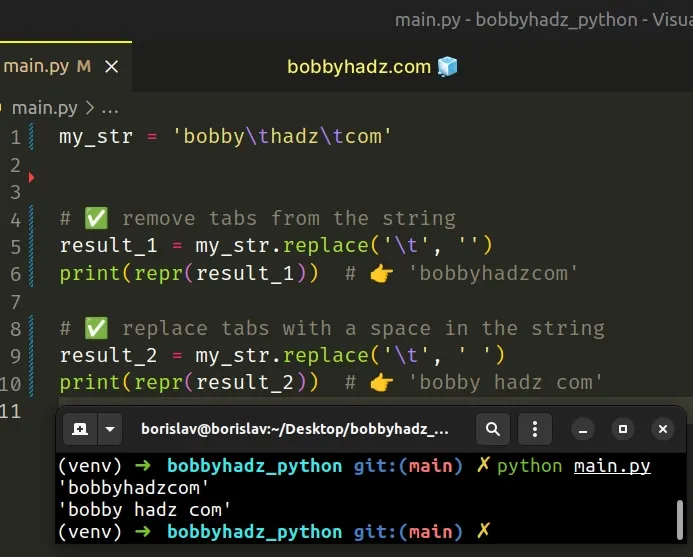
The str.replace() method returns a copy of the string with all occurrences of a substring replaced by the provided replacement.
The method takes the following parameters:
| Name | Description |
|---|---|
| old | The substring we want to replace in the string |
| new | The replacement for each occurrence of old |
| count | Only the first count occurrences are replaced (optional) |
The method doesn't change the original string. Strings are immutable in Python.
# Only removing the leading and trailing tabs from a string
If you only need to remove the leading and trailing tabs from a string, use the
strip() method.
my_str = '\tbobby\thadz\t' result = my_str.strip() print(repr(result)) # 👉️ 'bobby\thadz'
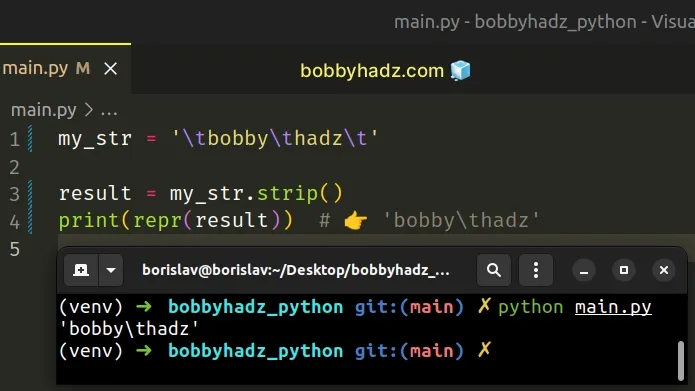
The str.strip() method returns a copy of the string with the leading and trailing whitespace (including the tabs) removed.
# Table of Contents
# Remove spaces, tabs and newlines from a String in Python
Use the re.sub() method to remove the spaces, tabs and newlines from a string.
import re my_str = ' bobby hadz ' result = re.sub(r'\s+', '', my_str) print(result) # 👉️ 'bobbyhadz'
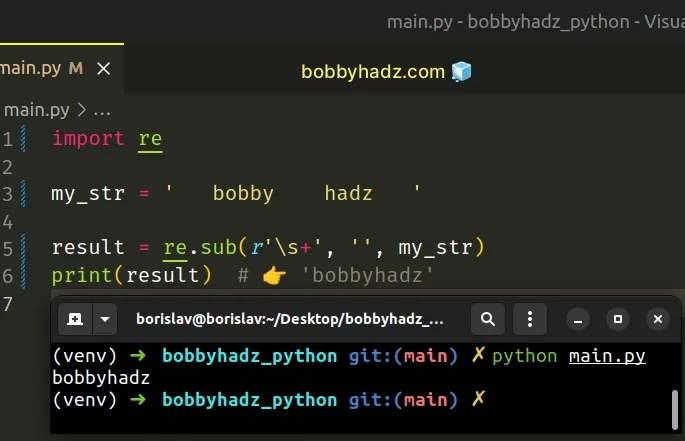
The example uses the re.sub() method to remove the spaces, tabs and newline
characters from the string.
The re.sub method returns a new string that is obtained by replacing the occurrences of the pattern with the provided replacement.
If the pattern isn't found, the string is returned as is.
The \s character matches Unicode whitespace characters like [ \t\n\r\f\v].
The plus + is used to match the preceding character (whitespace) 1 or more
times.
Alternatively, you can use the str.split() and str.join() methods.
# Remove spaces, tabs and newlines from a String using split() and join()
This is a three-step process:
- Use the
str.split()method to split the string on the characters. - Use the
str.join()method to join the list of strings. - The new string won't contain any spaces, tabs and newline characters.
my_str = ' bobby hadz ' result = ''.join(my_str.split()) print(result) # 👉️ 'bobbyhadz'
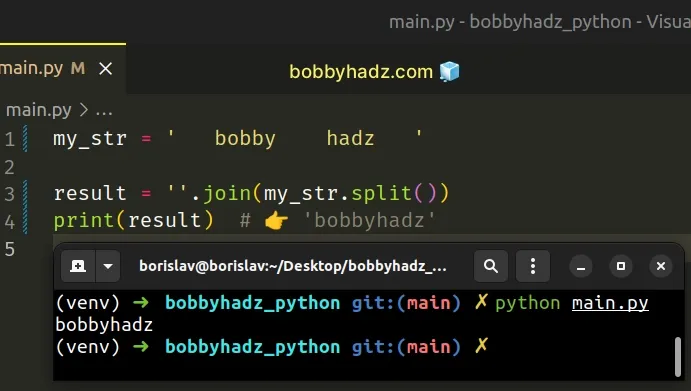
The str.split() method splits the string into a list of substrings using a delimiter.
When the str.split() method is called without a separator, it considers
consecutive whitespace characters as a single separator.
my_str = ' bobby hadz ' result = ''.join(my_str.split()) print(result) # 👉️ 'bobbyhadz'
When called without an argument, the str.split() method splits on consecutive
whitespace characters (e.g. \t, \n, etc), not only spaces.
The next step is to use the str.join() method to join the list of strings
without a separator.
my_str = ' bobby hadz ' result = ''.join(my_str.split()) print(result) # 👉️ 'bobbyhadz'
The str.join() method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The string the method is called on is used as the separator between the elements.
# Removing only the leading and trailing spaces, tabs and newlines from a string
If you need to remove the leading and trailing spaces, tabs and newlines from a
string, use the str.strip() method.
my_str = ' bobby hadz ' result = my_str.strip() print(result) # 👉️ 'bobby hadz' result = my_str.lstrip() print(repr(result)) # 👉️ 'bobby hadz ' result = my_str.rstrip() print(repr(result)) # 👉️ ' bobby hadz'
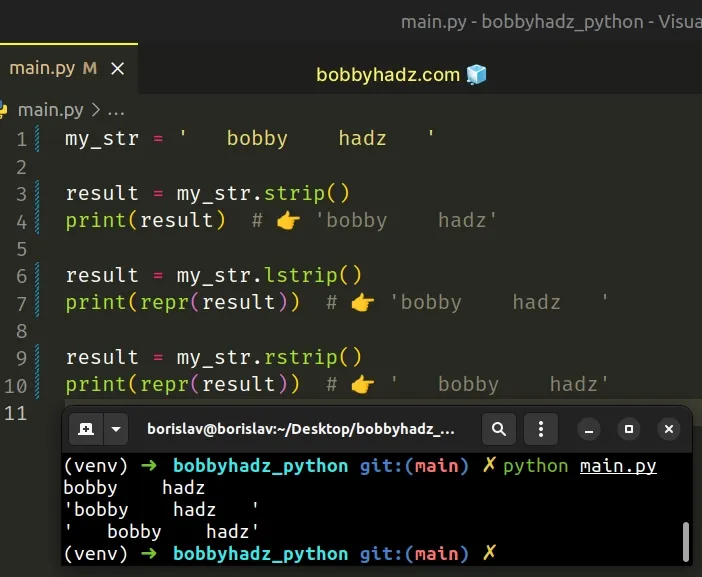
The str.strip() method returns a copy of the string with the leading and trailing whitespace removed.
There are also str.lstrip() and
str.rstrip() methods which remove
the leading or trailing whitespace characters from the string.
# Split a string by tab in Python
Use the str.split() method to split a string by tabs, e.g.
my_str.split('\t').
The str.split method will split the string on each occurrence of a tab and
will return a list containing the results.
my_str = 'bobby\thadz\tcom' my_list = my_str.split('\t') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
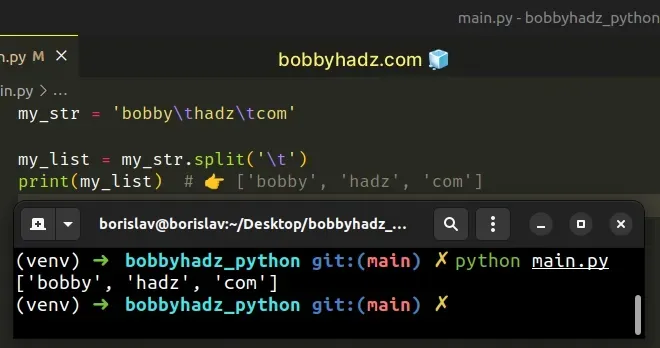
The str.split() method splits the string into a list of substrings using a delimiter.
The method takes the following 2 parameters:
| Name | Description |
|---|---|
| separator | Split the string into substrings on each occurrence of the separator |
| maxsplit | At most maxsplit splits are done (optional) |
If the separator is not found in the string, a list containing only 1 element is returned.
my_str = 'bobby' my_list = my_str.split('\t') # 👇️ ['bobby'] print(my_list)
# Handling leading or trailing tab characters
If your string starts with or ends with a tab, you will get empty string elements in the list.
my_str = '\tbobby\thadz\tcom\t' my_list = my_str.split('\t') print(my_list) # 👉️ ['', 'bobby', 'hadz', 'com', '']
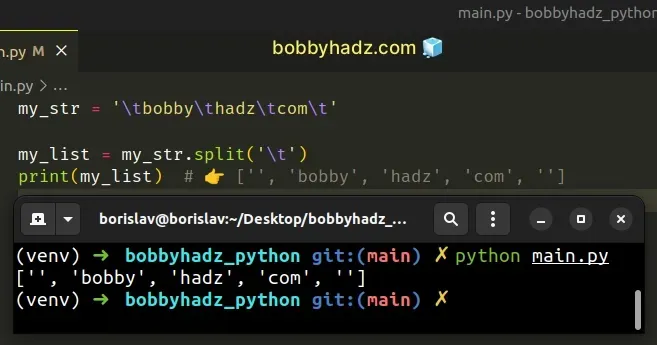
One way to handle the leading and trailing tab characters is to use the
str.strip() method before calling split().
my_str = '\tbobby\thadz\tcom\t' my_list = my_str.strip().split('\t') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The str.strip method returns a copy of the string with the leading and trailing whitespace removed.
We only split the string on each tab once the leading and trailing tabs are removed.
You can also use the filter() function to
remove the empty strings from the list.
my_str = '\tbobby\thadz\tcom\t' my_list = list(filter(None, my_str.split('\t'))) print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The filter function takes a function and an iterable as arguments and constructs an iterator from the elements of the iterable for which the function returns a truthy value.
None for the function argument, all falsy elements of the iterable are removed.Note that the filter() function returns a filter object, so we have to use
the list() class to convert the filter
object to a list.
# Split a string by Tab using re.split()
An alternative is to use the re.split() method.
The re.split() method will split the string on each occurrence of a tab and
return a list containing the results.
import re my_str = '\tbobby\t\thadz\t\tcom\t' my_list = re.split(r'\t+', my_str.strip()) print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The re.split() method takes a pattern and a string and splits the string on each occurrence of the pattern.
The \t character matches tabs.
The plus + is used to match the preceding character (tab) 1 or more times.
In its entirety, the regular expression matches one or more tab characters.
This is useful when you want to count multiple consecutive tabs as a single tab when splitting the string.
Notice that we used the str.strip() method on the string.
The str.strip method returns a copy of the string with the leading and trailing whitespace removed.
my_str = '\tbobby\t\thadz\t\tcom\t' # bobby hadz com print(my_str.strip())
The str.strip() method takes care of removing the leading and trailing
whitespace, so we don't get empty strings in the list.
# Split a string by Tab using re.findall()
You can also use the re.findall() method to split a string on each occurrence
of a tab.
import re my_str = '\tbobby\thadz\tcom\t' pattern = re.compile(r'[^\t]+') my_list = pattern.findall(my_str) print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The re.findall() method takes a pattern and a string as arguments and returns a list of strings containing all non-overlapping matches of the pattern in the string.
The regular expression we passed to the re.compile method contains a character
class.
When the caret ^ is at the beginning of a character class, it means "Not the
following".
In other words, match everything but tab characters.
The + matches the preceding character (everything but tabs) 1 or more times.
In its entirety, the regular expression matches one or more occurrences of non-tab characters in the string.
I've also written an article on how to print a Tab in Python.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove punctuation from a List of strings in Python
- How to remove Quotes from a List of Strings in Python
- Remove characters matching Regex from a String in Python
- Remove special characters except Space from String in Python
- Remove square brackets from a List or a String in Python
- Remove Newline characters from a List or a String in Python
- Remove non-alphanumeric characters from a Python string
- Remove non-ASCII characters from a string in Python
- Remove the non utf-8 characters from a String in Python
- How to Remove \xa0 from a String in Python
- Flake8: f-string is missing placeholders [Solved]

