Remove duplicates from a List of Dictionaries in Python
Last updated: Apr 9, 2024
Reading time·4 min

# Table of Contents
- Remove duplicates from a List of Dictionaries in Python
- Remove the duplicates from a List of Dictionaries using a for loop
- Remove duplicates from a List of Dictionaries using enumerate()
- Remove duplicates from a List of Dictionaries using pandas
# Remove duplicates from a List of Dictionaries in Python
To remove the duplicates from a list of dictionaries:
- Use a dict comprehension to iterate over the list.
- Use the value of each
idproperty as a key and the dictionary as a value. - Use the
dict.values()method to only get the unique dictionaries. - Use the
list()class to convert the result to a list.
list_of_dictionaries = [ {'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}, {'id': 1, 'site': 'bobbyhadz.com'}, ] result = list( { dictionary['id']: dictionary for dictionary in list_of_dictionaries }.values() ) # 👇️ [{'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}] print(result)
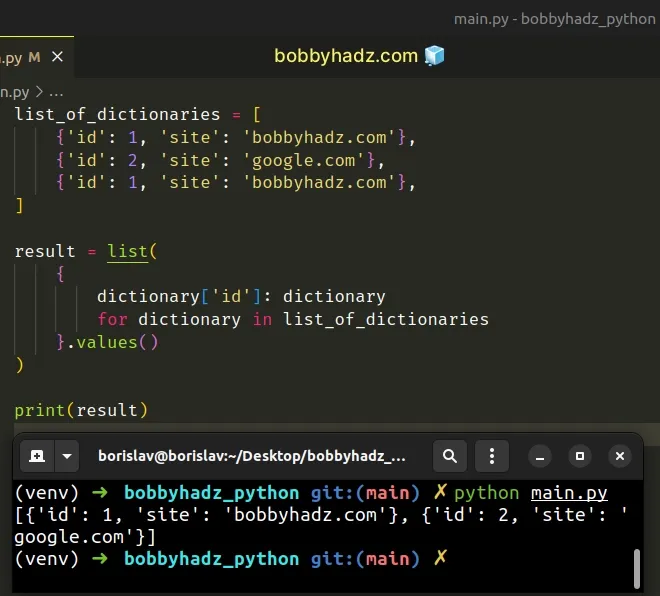
We used a dict comprehension to iterate over the list of dictionaries.
Dict comprehensions are very similar to list comprehensions.
On each iteration, we set the value of the current id as the key and the
actual dictionary as the value.
The keys in a dictionary are unique, so any duplicate values get filtered out.
We then use the dict.values() method to only return the unique dictionaries.
The dict.values method returns a new view of the dictionary's values.
my_dict = {'id': 1, 'name': 'bobbyhadz'} print(my_dict.values()) # 👉️ dict_values([1, 'bobbyhadz'])
The last step is to use the list() class to convert the view object to a list
containing the unique dictionaries.
The list class takes an iterable and returns a list object.
Here is the complete code snippet.
list_of_dictionaries = [ {'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}, {'id': 1, 'site': 'bobbyhadz.com'}, ] result = list( { dictionary['id']: dictionary for dictionary in list_of_dictionaries }.values() ) # 👇️ [{'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}] print(result)
# Remove the duplicates from a List of Dictionaries using a for loop
This is a three-step process:
- Declare a new variable that stores an empty list.
- Use a
forloop to iterate over the list of dictionaries. - Use the
list.append()method to add unique dictionaries to the new list.
list_of_dictionaries = [ {'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}, {'id': 1, 'site': 'bobbyhadz.com'}, ] new_list = [] for dictionary in list_of_dictionaries: if dictionary not in new_list: new_list.append(dictionary) # 👇️ [{'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}] print(new_list)
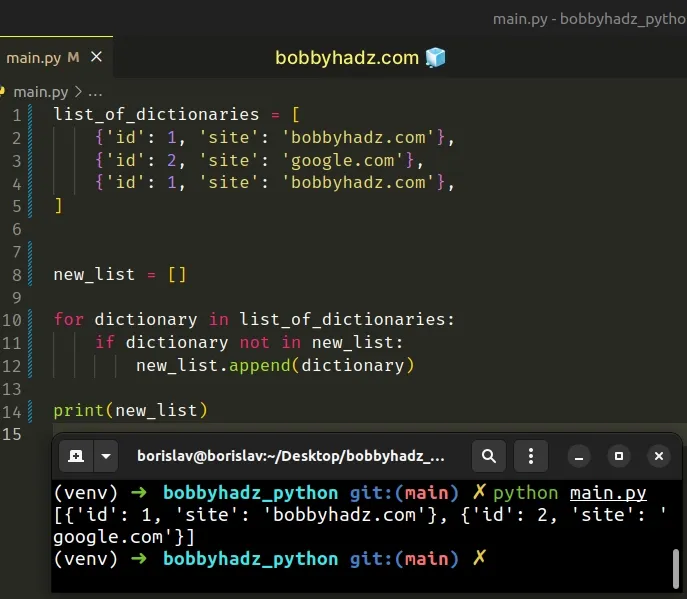
We used a for loop to iterate over the list of dictionaries.
On each iteration, we use the not in operator to check if the dictionary is
not present in the new list.
If the condition is met, we use the list.append() method to append the
dictionary to the list.
The in operator tests
for membership. For example, x in l evaluates to True if x is a member of
l, otherwise, it evaluates to False.
x not in l returns the negation of x in l.The list.append() method adds an item to the end of the list.
my_list = ['bobby', 'hadz'] my_list.append('com') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
# Remove duplicates from a List of Dictionaries using enumerate()
You can also use the enumerate() function to remove the duplicates from a list
of dictionaries.
list_of_dictionaries = [ {'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}, {'id': 1, 'site': 'bobbyhadz.com'}, ] new_list = [ dictionary for index, dictionary in enumerate(list_of_dictionaries) if dictionary not in list_of_dictionaries[index + 1:] ] # 👇️ [{'id': 2, 'site': 'google.com'}, # {'id': 1, 'site': 'bobbyhadz.com'}] print(new_list)
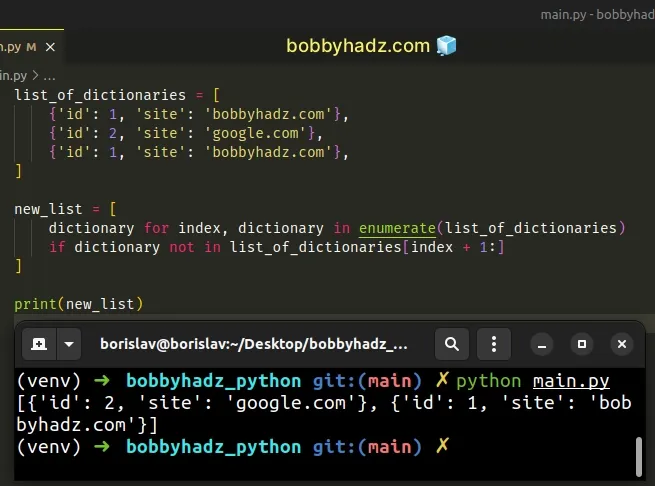
The enumerate() function takes an iterable and returns an enumerate object containing tuples where the first element is the index and the second is the corresponding item.
On each iteration, we check if the dictionary is not contained in the remainder of the list.
Notice that we used a list slice that starts at the next index.
If the dictionary is not contained in the remainder of the list, then it's not a duplicate.
# Remove duplicates from a List of Dictionaries using pandas
If you use the pandas module, you can also convert the dictionary to a
DataFrame and drop the duplicates.
Make sure you have pandas installed to run the code sample.
pip install pandas # 👇️ or with pip3 pip3 install pandas
Now, pass the list of dictionaries to the DataFrame class.
import pandas as pd list_of_dictionaries = [ {'id': 1, 'site': 'bobbyhadz.com'}, {'id': 2, 'site': 'google.com'}, {'id': 1, 'site': 'bobbyhadz.com'}, ] new_list = pd.DataFrame( list_of_dictionaries ).drop_duplicates().to_dict('records') # [{'id': 1, 'site': 'bobbyhadz.com'}, # {'id': 2, 'site': 'google.com'}] print(new_list)
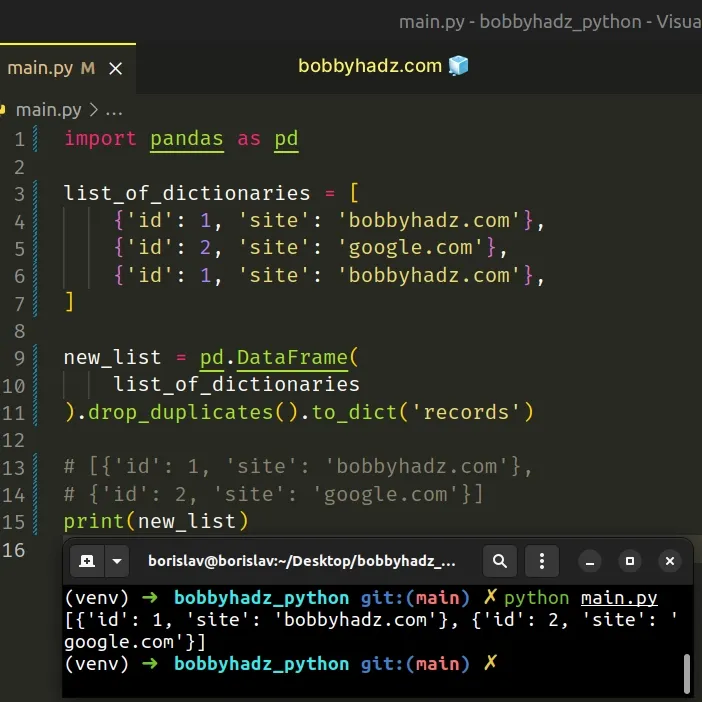
The
drop_duplicates()
method returns the DataFrame with the duplicates removed.
The
to_dict()
method converts the DataFrame object to a dictionary.
I've also written a detailed article on how to remove a dictionary from a list of dictionaries.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

