UnicodeDecodeError: 'utf-8' codec can't decode byte in position: invalid continuation byte
Last updated: Apr 8, 2024
Reading time·7 min

# UnicodeDecodeError: 'utf-8' codec can't decode byte in position: invalid continuation byte
The Python "UnicodeDecodeError: 'utf-8' codec can't decode byte in position: invalid continuation byte" occurs when we specify an incorrect encoding when decoding a bytes object.
To solve the error, specify the correct encoding, e.g. latin-1.
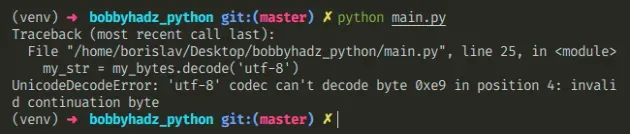
Here is an example of how the error occurs.
my_bytes = 'one é two'.encode('latin-1') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 4: invalid continuation byte my_str = my_bytes.decode('utf-8')
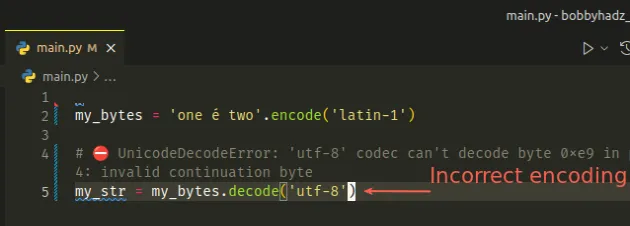
Notice that the string was encoded to bytes using the latin-1 encoding.
If we try to decode the bytes object using a different encoding (e.g. utf-8),
the error is raised.
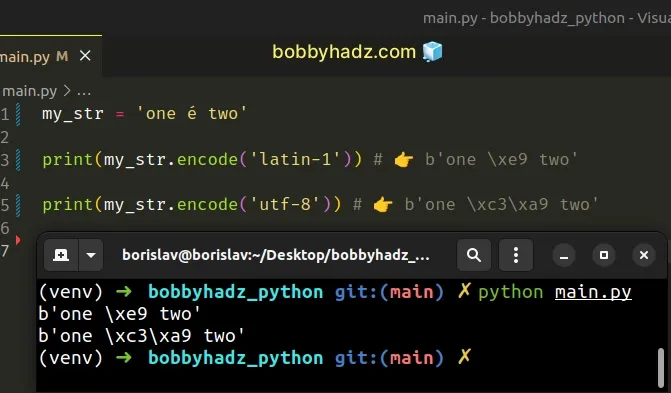
The two encodings are different and produce different results.
my_str = 'one é two' print(my_str.encode('latin-1')) # 👉️ b'one \xe9 two' print(my_str.encode('utf-8')) # 👉️ b'one \xc3\xa9 two'
string to a bytes object and decoding is the process of converting a bytes object to a string.When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
# Set the encoding to latin-1 to solve the error
In the example, we can set the encoding to latin-1.
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('latin-1') print(my_str) # 👉️ "one é two"
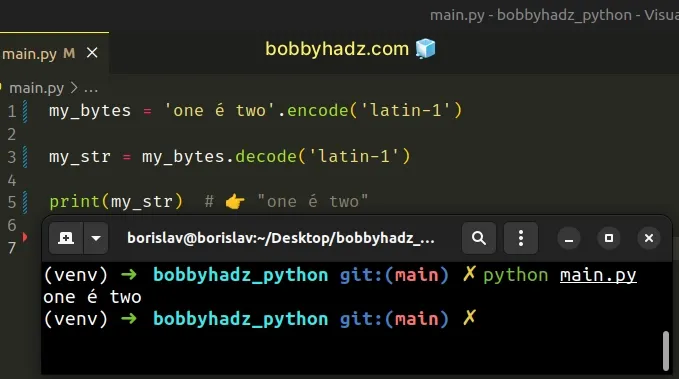
The encoding that was used to convert the string to a bytes object matches the encoding that was used to convert the bytes object to a string, so everything works as expected.
The latin-1 encoding consists of 191 characters from the Latin script and is used throughout the Americas, Western Europe, Oceania and Africa.
# Setting the encoding to latin-1 when reading from files
If you got the error when reading from a file using pandas, try setting the
encoding to latin-1 or ISO-8859-1 in the call to the
read_csv() method.
import pandas as pd # 👇️ set encoding to latin-1 df = pd.read_csv('employees.csv', sep='|', encoding='latin-1') # first_name last_name # 0 Alice Smith # 1 Bobby Hadz print(df)
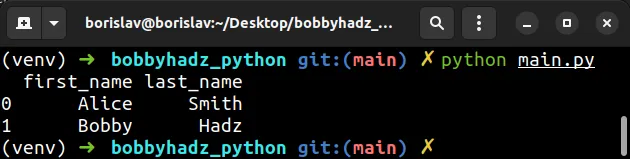
The code sample assumes that there is an employees.csv file in the same
directory as your Python script.
first_name|last_name Alice|Smith Bobby|Hadz
You can try doing the same if using the native open() function.
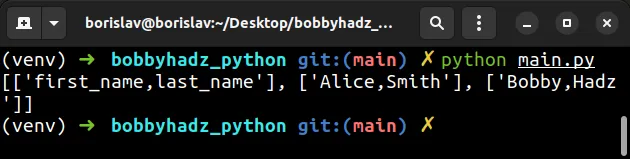
import csv with open('employees.csv', newline='', encoding='latin-1') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader)
The same approach can be used if you use the native open() function without
the with statement.
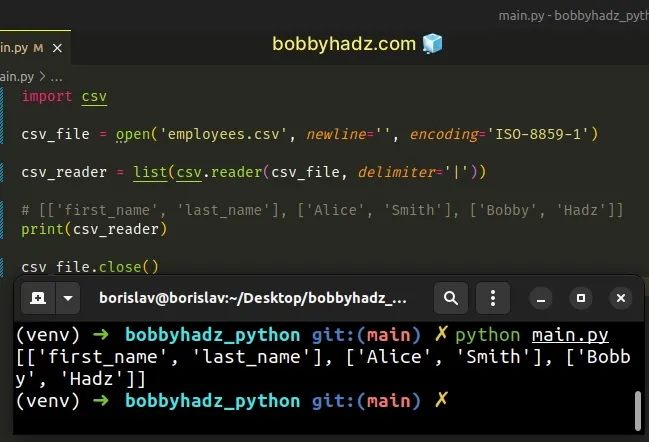
import csv csv_file = open('employees.csv', newline='', encoding='latin-1') csv_reader = list(csv.reader(csv_file, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader) csv_file.close()
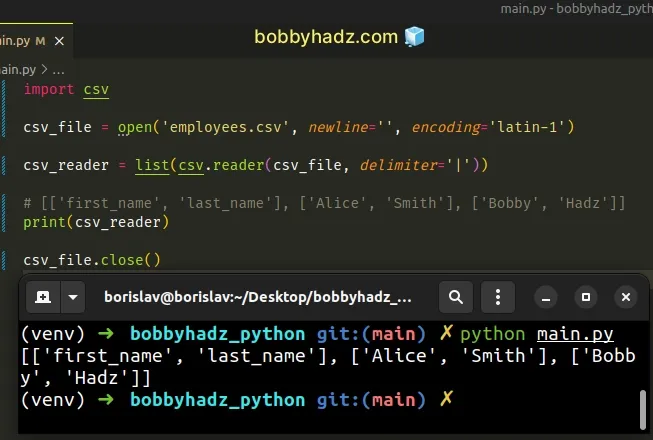
If the latin-1 encoding doesn't produce legible results, try setting the
encoding to ISO-8859-1.
import pandas as pd # 👇️ set encoding to ISO-8859-1 df = pd.read_csv('employees.csv', sep='|', encoding='ISO-8859-1') # first_name last_name # 0 Alice Smith # 1 Bobby Hadz print(df)
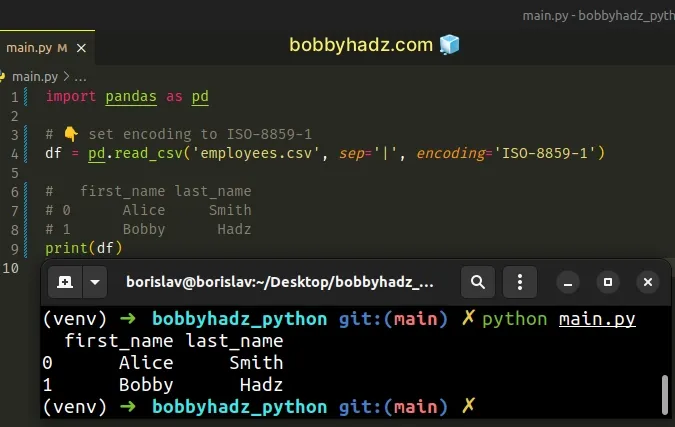
The ISO-8859-1 encoding defines a character for each of the 256 possible byte
values, so no error is raised.
The encoding can also be passed to the native open() function.
import csv csv_file = open('employees.csv', newline='', encoding='ISO-8859-1') csv_reader = list(csv.reader(csv_file, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader) csv_file.close()
# Setting the errors keyword argument to ignore
If the error persists, you could set the
errors keyword argument
to ignore to ignore the characters that cannot be decoded.
Note that ignoring characters that cannot be decoded can lead to data loss.
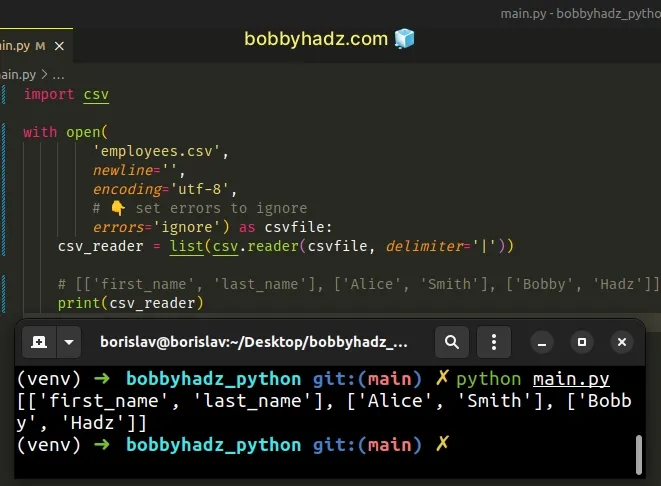
import csv # 👇️ set errors to ignore with open('employees.csv', newline='', encoding='utf-8', errors='ignore') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader)
Opening the file with an incorrect encoding with errors set to ignore won't
raise a UnicodeDecodeError.
Make sure you didn't open a file in rb (read binary) mode if you have to read
from it.
# Setting the errors argument to ignore when decoding bytes
You can also set the errors argument to ignore in the call to the decode()
method.
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('utf-8', errors='ignore') print(my_str) # 👉️ one two
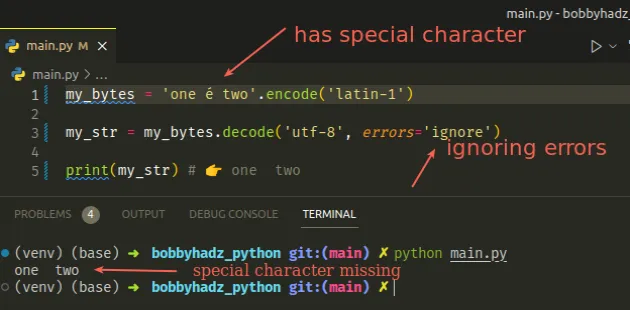
We set an incorrect encoding but didn't get an error because the errors
keyword argument is set to ignore.
However, note that ignoring characters that cannot be decoded can lead to data loss.
# Opening the file in binary mode
If you don't need to interact with the contents of the file, you can open it in binary mode without decoding it.
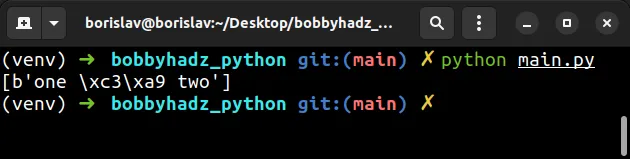
with open('example.txt', 'rb') as f: lines = f.readlines() # ✅ [b'one \xc3\xa9 two'] print(lines)
The code sample assumes that you have an example.txt file in the same
directory as your main.py script.
one é two
We opened the file in binary mode (using the rb mode), so the lines list
contains bytes objects.
You shouldn't specify encoding when opening a file in binary mode.
# Use the rb or wb encoding if reading from or writing to PDF files
Note that if you are trying to read from or write to a PDF file, you have to use
the rb (read binary) or wb (write binary) modes as PDF files are stored as
bytes.
with open('example.pdf', 'rb') as file1: my_bytes = file1.read() # 👇️ specify correct encoding print(my_bytes.decode('latin-1'))
The code sample assumes that there is an example.pdf file located in the same
directory as your main.py script.
# Try using the 'ISO-8859-1' encoding
If the error persists, try using the ISO-8859-1 encoding.
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('ISO-8859-1') print(my_str) # 👉️ one é two
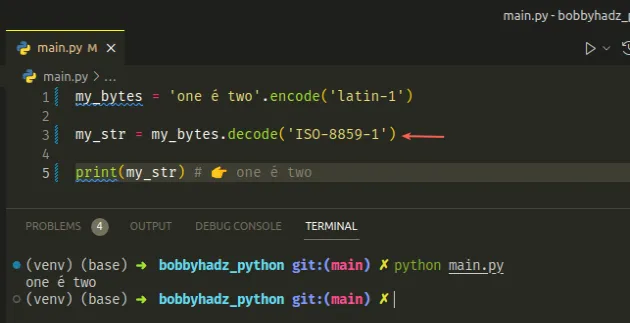
You won't get an error when the encoding is set to ISO-8859-1, however, you might get illegible results.
The ISO-8859-1 encoding defines a character for each of the 256 possible byte
values, so no error is raised.
Here is an example of using the encoding when reading from a file.
with open('example.txt', 'r', encoding='ISO-8859-1') as f: lines = f.readlines() print(lines)
# Trying to find the encoding of the file
You can try to figure out what the encoding of the file is by using the file
command.
The command is available on macOS and Linux, but can also be used on Windows if you have Git and Git Bash installed.
Make sure to run the command in Git Bash if on Windows.
Open your shell in the directory that contains the file and run the following command.
file *
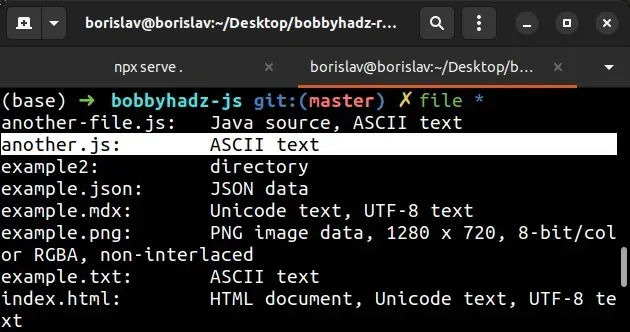
The screenshot shows that the file uses the ASCII encoding.
This is the encoding you should specify when opening the file.
with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
If you are on Windows, you can also:
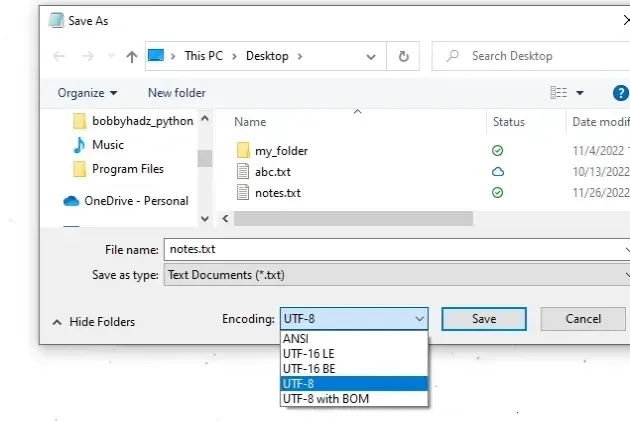
- Open the file in the basic version of Notepad.
- Click on "Save as".
- Look at the selected encoding right next to the "Save" button.
# Using the chardet module to detect the file's encoding
If you were unable to find the encoding of the file, try to install and use the chardet Python module.
pip install chardet # 👇️ or pip3 pip3 install chardet
Now run the chardetect command as follows.
chardetect your_file
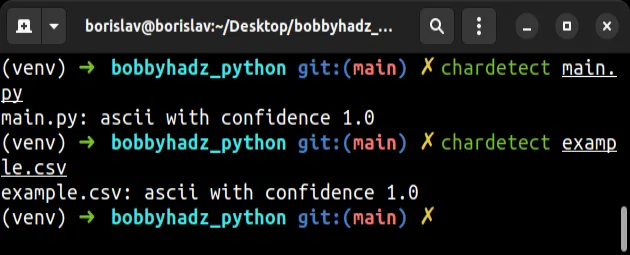
The package will try to detect the encoding of the specified file.
You can then try to use the encoding when opening the file.
with open('example.txt', 'r', encoding='your_encoding') as f: lines = f.readlines() print(lines)
You can also try to open the file in binary mode and use the chardet package
to detect the encoding of the file.
import chardet with open('example.txt', 'rb') as f: print(chardet.detect(f.read()))
We used the rb (read binary) mode and fed the output of the file to the
chardet.detect() method.
The encoding you get from calling the method is the one you should try when opening the file in reading mode.
# Saving the file with a UTF-8 encoding
Another thing you can try is to save the file with a UTF-8 encoding.
You can:
- Click on "File" in the top menu.
- Click on "Save as".
- Set the encoding to
UTF-8and save the file.
# How the error occurs
Encoding is the process of converting a string to a bytes object and
decoding is the process of converting a bytes object to a string.
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
Here is an example that shows how using a different encoding to encode a string to bytes than the one used to decode the bytes object causes the error.
my_text = 'one æåäãé two' my_binary_data = my_text.encode('latin-1') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe6 in position 4: invalid continuation byte my_text_again = my_binary_data.decode('utf-8')
We can solve the error by using the latin-1 encoding to decode the bytes
object.
my_text = 'one æåäãé two' my_binary_data = my_text.encode('latin-1') my_text_again = my_binary_data.decode('latin-1') print(my_text_again) # "one æåäãé two"
# Common causes of the error
The "UnicodeDecodeError: 'utf-8' codec can't decode byte in position: invalid continuation byte" error is often caused when:
- An incorrect encoding is used when decoding a
bytesobject. - We open a file in
rb(read binary) orwb(write binary) and attempt to read from it or write to it.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

