UnicodeDecodeError: 'ascii' codec can't decode byte [Solved]
Last updated: Apr 8, 2024
Reading time·3 min

# UnicodeDecodeError: 'ascii' codec can't decode byte
The Python "UnicodeDecodeError: 'ascii' codec can't decode byte in position"
occurs when we use the ascii codec to decode bytes that were encoded using a
different codec.
To solve the error, specify the correct encoding, e.g. utf-8.
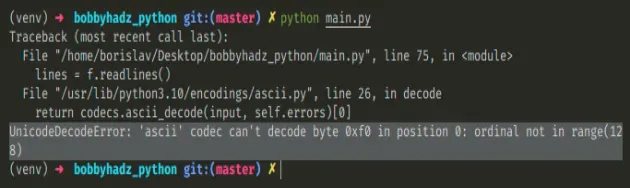
Here is an example of how the error occurs.
I have a file called example.txt with the following contents.
𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
And here is the code that tries to decode the contents of example.txt using
the ascii codec.
# ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
The error is caused because the example.txt file doesn't use the ascii
encoding.
𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
If you know the encoding the file uses, make sure to specify it using the encoding keyword argument.
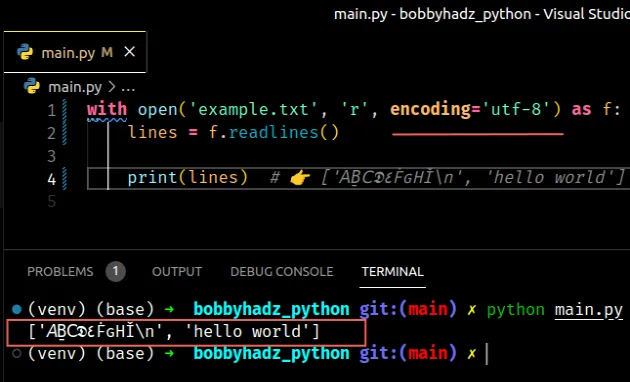
# Try setting the encoding to utf-8
Otherwise, the first thing you can try is setting the encoding to utf-8.
# 👇️ Set encoding to utf-8 with open('example.txt', 'r', encoding='utf-8') as f: lines = f.readlines() print(lines) # 👉️ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
utf-8 encoding is capable of encoding over a million valid character code points in Unicode.You can view all of the standard encodings in this table of the official docs.
string to a bytes object and decoding is the process of converting a bytes object to a string.When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
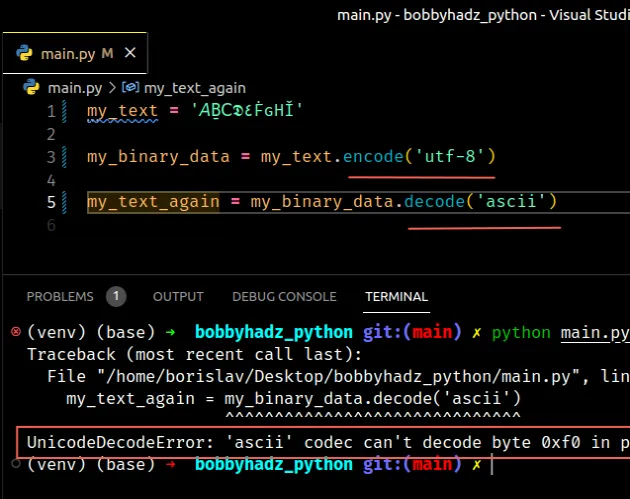
Here is an example that shows how using a different encoding to encode a string to bytes than the one used to decode the bytes object causes the error.
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) my_text_again = my_binary_data.decode('ascii')
We can solve the error by using the utf-8 encoding to decode the bytes object.
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ Specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
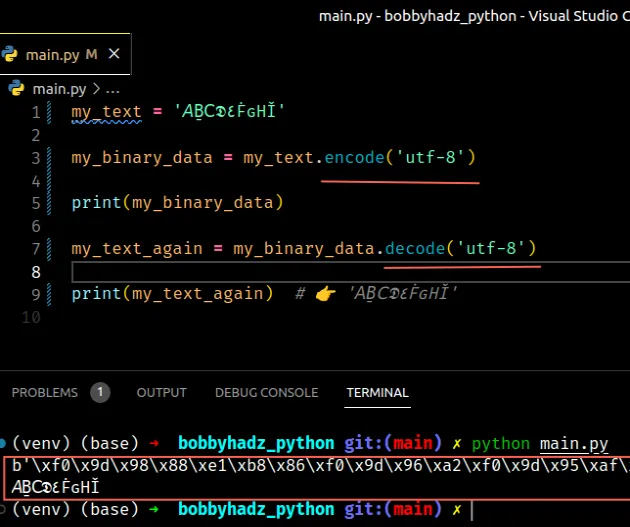
The code sample doesn't cause an issue because the same encoding was used to encode the string into bytes and decode the bytes object into a string.
# Set the errors keyword argument to ignore
If you get an error when decoding the bytes using the utf-8 encoding, you can
try setting the
errors keyword argument
to ignore to ignore the characters that cannot be decoded.
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👇️ Set errors to ignore my_text_again = my_binary_data.decode('utf-8', errors='ignore') print(my_text_again)
Note that ignoring characters that cannot be decoded can lead to data loss.
Here is an example where errors is set to ignore when opening a file.
# 👇️ Set errors to ignore with open('example.txt', 'r', encoding='utf-8', errors='ignore') as f: lines = f.readlines() # ✅ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world'] print(lines)
Opening the file with an incorrect encoding with errors set to ignore won't
raise an error.
with open('example.txt', 'r', encoding='ascii', errors='ignore') as f: lines = f.readlines() # ✅ ['\n', 'hello world'] print(lines)
The example.txt file doesn't use the ascii encoding, however, opening the
file with errors set to ignore doesn't raise an error.
𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
Instead, it ignores the data it cannot parse and returns the data it can parse.
# Make sure you aren't mixing up encode() and decode()
Make sure you aren't mixing up calls to the str.encode() and bytes.decode()
method.
string to a bytes object and decoding is the process of converting a bytes object to a string.If you have a str that you want to convert to bytes, use the encode()
method.
my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ Specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
If you have a bytes object that you need to convert to a string, use the
decode() method.
Make sure to specify the same encoding in the call to the
str.encode() and bytes.decode()
methods.
# Discussion
The default encoding in Python 3 is utf-8.
Python 3 no longer has the concept of Unicode like Python 2 did.
Instead, Python 3 supports strings and bytes objects.
Using the ascii encoding to decode a bytes object that was encoded in a
different encoding causes the error.

