TypeError: unhashable type 'slice' in Python [Solved]
Last updated: Apr 10, 2024
Reading time·6 min

# TypeError: unhashable type 'slice' in Python [Solved]
The "TypeError: unhashable type 'slice'" exception in Python occurs for 2 main reasons:
- Trying to slice a dictionary, e.g.
a_dict[:2]. - Trying to slice a
DataFrameobject, e.g.df[:, 2].
If you got the error when slicing a DataFrame object in pandas, click on
the following subheading:
# Slicing a Dictionary in Python
The syntax for list slicing is
a_list[start:stop:step].
a_list = ['bobby', 'hadz', 'com'] print(a_list[:2]) # 👉️ ['bobby', 'hadz'] print(a_list[1:3]) # 👉️ ['hadz', 'com']
The start index is inclusive and the stop index is exclusive (up to, but not
including).
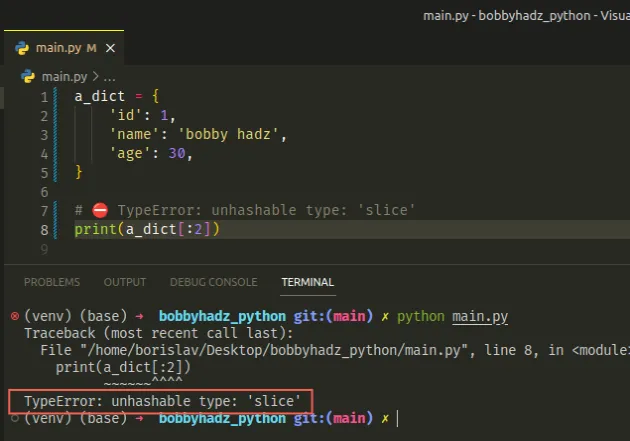
Here is an example of how the error occurs when trying to slice a dictionary.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } # ⛔️ TypeError: unhashable type: 'slice' print(a_dict[:2])
One way to get around the error is to manually access the key-value pairs.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } employee_id = a_dict['id'] print(employee_id) # 👉️ 1 employee_name = a_dict['name'] print(employee_name) # 👉️ bobby hadz
You can access specific key-value pairs using bracket notation.
# Using dict.items() to slice a dictionary
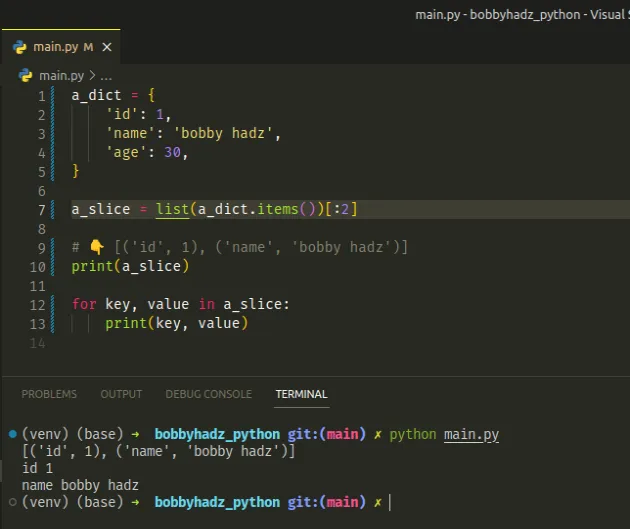
Alternatively, you can use the items() method to slice a dictionary.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } a_slice = list(a_dict.items())[:2] # 👇️ [('id', 1), ('name', 'bobby hadz')] print(a_slice) for key, value in a_slice: print(key, value)
list() class to convert the dictionary's items to a list before slicing.This is necessary because the dict_items object cannot directly be sliced.
The dict.items() method returns a new view of the dictionary's items ((key, value) pairs).
my_dict = {'id': 1, 'name': 'BobbyHadz'} # 👇️ dict_items([('id', 1), ('name', 'BobbyHadz')]) print(my_dict.items())
If you need to iterate over a slice of the dictionary, use a for loop.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } a_slice = list(a_dict.items())[:2] for key, value in a_slice: print(key, value)
The code sample produces the following output.
id 1 name bobby hadz
# Creating a dictionary containing a slice of the original dict
You can use a for loop if you need to create a dictionary that contains a
slice of the original dict.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } dict_slice = {} for key, value in list(a_dict.items())[:2]: dict_slice[key] = value # 👇️ {'id': 1, 'name': 'bobby hadz'} print(dict_slice)
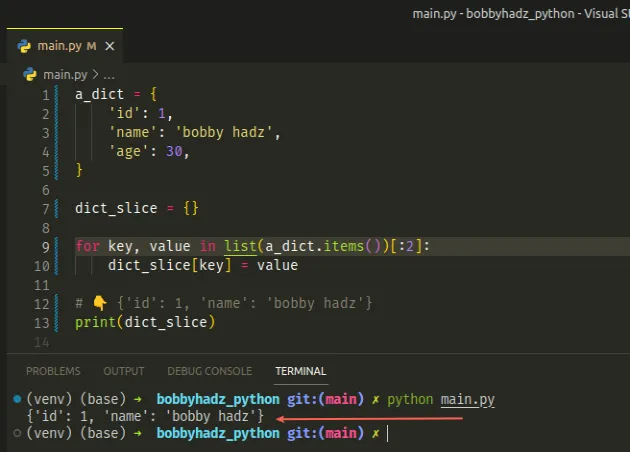
The code sample uses a for loop to iterate over the slice and adds each
key-value pair to a new dictionary.
Alternatively, you can pass the list slice directly to the dict() class.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } a_slice = list(a_dict.items())[:2] print(a_slice) # 👉️ [('id', 1), ('name', 'bobby hadz')] dict_slice = dict(a_slice) print(dict_slice) # 👉️ {'id': 1, 'name': 'bobby hadz'}
We used the dict class to convert the list of key-value pairs to a Python
dictionary.
# Getting a slice of a dictionary's keys or values
You can use the dict.keys() and dict.values() method to slice the
dictionary's keys or values.
a_dict = { 'id': 1, 'name': 'bobby hadz', 'age': 30, } keys_slice = list(a_dict.keys())[1:3] print(keys_slice) # 👉️ ['name', 'age'] values_slice = list(a_dict.values())[1:3] print(values_slice) # 👉️ ['bobby hadz', 30]
list() class to convert the dictionary's keys and values to lists before slicing.This is necessary because the dict_keys and dict_values objects cannot
directly be sliced.
The dict.keys() method returns a new view of the dictionary's keys.
my_dict = {'id': 1, 'name': 'BobbyHadz'} print(my_dict.keys()) # 👉️ dict_keys(['id', 'name'])
The dict.values() method returns a new view of the dictionary's values.
my_dict = {'id': 1, 'name': 'bobbyhadz'} print(my_dict.values()) # 👉️ dict_values([1, 'bobbyhadz'])
# TypeError: unhashable type 'slice' when slicing a DataFrame
You might also get the "TypeError: unhashable type 'slice'" when slicing a
pandas DataFrame object.
import pandas as pd data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) # ⛔️ pandas.errors.InvalidIndexError: (slice(1, 3, None), slice(None, None, None)) print(df[1:3, :])
The df variable stores a DataFrame and can't be sliced directly.
Instead, you should use the
iloc
attribute to slice the DataFrame.
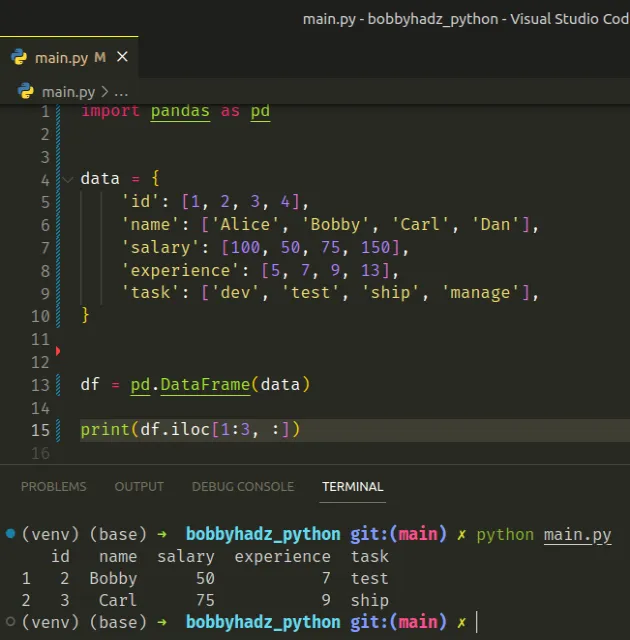
import pandas as pd data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) print(df.iloc[1:3, :])
The code sample produces the following output.
id name salary experience task 1 2 Bobby 50 7 test 2 3 Carl 75 9 ship
iloc is used to select rows and columns by integer location.
There is also a loc attribute that is used for label-based indexing.
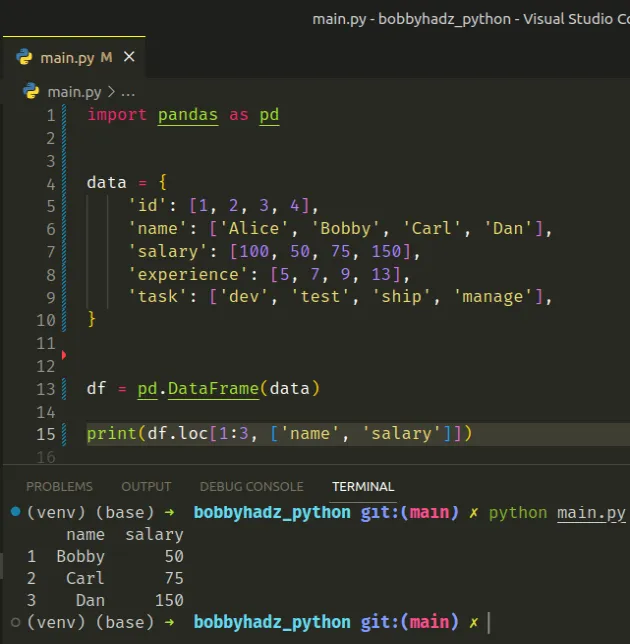
import pandas as pd data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) print(df.loc[1:3, ['name', 'salary']])
The code sample produces the following output.
name salary 1 Bobby 50 2 Carl 75 3 Dan 150
loc is used to select rows and columns by label(s).
You can also access a DataFrame using bracket notation if you need to print
the values of a specific column.
import pandas as pd data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) print(df['name'])
The code sample produces the following output.
0 Alice 1 Bobby 2 Carl 3 Dan Name: name, dtype: object
# Slicing a DataFrame when encoding categorical data
Here is another example of how the error occurs.
import pandas as pd from sklearn.preprocessing import LabelEncoder data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) y = df.iloc[:, 4] x = df.iloc[:, 0:4] labelencoder_X = LabelEncoder() # ⛔️ TypeError: unhashable type: 'slice' x[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3]) print(df.iloc)
The error is caused by the following line.
x[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3])
The x variable stores a DataFrame object and they cannot be sliced directly.
To solve the error, use the iloc attribute for position-based indexing.
import pandas as pd from sklearn.preprocessing import LabelEncoder data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) y = df.iloc[:, 4] x = df.iloc[:, 0:4] labelencoder_X = LabelEncoder() # ✅ Accessing the `iloc` attribute x.iloc[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3])
We only changed the following line in the code sample.
x.iloc[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3])
iloc is used to select rows and columns by integer location.
You can also access the values attribute before slicing.
The values attribute returns the NumPy representation of the DataFrame
object.
import pandas as pd from sklearn.preprocessing import LabelEncoder data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) y = df.iloc[:, 4] x = df.iloc[:, 0:4] labelencoder_X = LabelEncoder() # ✅ Accessing values attribute x.values[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3])
We only changed the last line of the code sample.
The values attribute returns a numpy.ndarray object that stores the values
of the DataFrame.
The
to_numpy
method can also be used to convert the DataFrame object to a NumPy array.
import pandas as pd from sklearn.preprocessing import LabelEncoder data = { 'id': [1, 2, 3, 4], 'name': ['Alice', 'Bobby', 'Carl', 'Dan'], 'salary': [100, 50, 75, 150], 'experience': [5, 7, 9, 13], 'task': ['dev', 'test', 'ship', 'manage'], } df = pd.DataFrame(data) y = df.iloc[:, 4] x = df.iloc[:, 0:4] labelencoder_X = LabelEncoder() # ✅ Calling to_numpy() x.to_numpy()[:, 3] = labelencoder_X.fit_transform(df.iloc[:, 3])
We used the to_numpy() method to convert the DataFrame object to a NumPy
array prior to using slicing notation.
# Conclusion
To solve the "TypeError: unhashable type 'slice'" exception:
- Convert the dictionary's items to a list before slicing.
- Use the
ilocattribute on aDataFrameobject before slicing.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove the First or Last item from a Dictionary in Python
- How to access a Dictionary Key by Index in Python
- Get random Key and Value from a Dictionary in Python
- Check if multiple Keys exist in a Dictionary in Python
- Check if a nested key exists in a Dictionary in Python
- How to filter a List of Dictionaries in Python

