Remove everything Before or After a Character in Python
Last updated: Apr 9, 2024
Reading time·6 min

# Table of Contents
- Remove everything after a character in a string in Python
- Remove everything after the Last occurrence of a character
- Remove everything Before a Character in a String in Python
- Remove everything before the Last occurrence of a character
# Remove everything after a character in a string in Python
To remove everything after a character in a string:
- Use the
str.split()method to split the string on the separator. - Access the list element at index
0to get everything before the separator. - Optionally, use the addition (+) operator to add the separator.
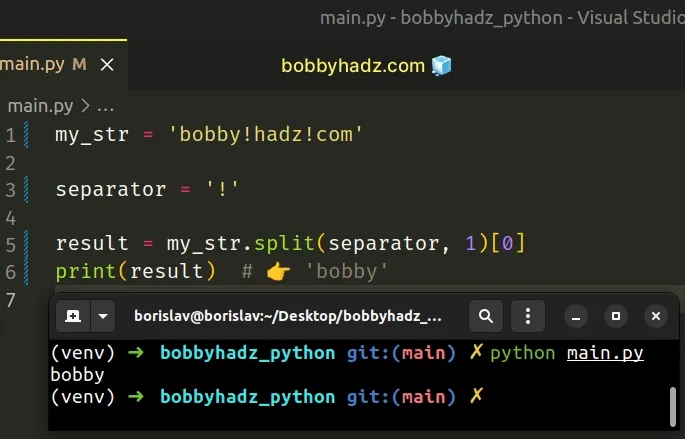
my_str = 'bobby!hadz!com' separator = '!' result = my_str.split(separator, 1)[0] print(result) # 👉️ 'bobby'
Note: if you need to remove everything BEFORE a character, click on the following subheading:
We used the str.split() method to remove everything after a character (! in
the example).
The str.split() method splits the string into a list of substrings using a delimiter.
The method takes the following 2 parameters:
| Name | Description |
|---|---|
separator | Split the string into substrings on each occurrence of the separator |
maxsplit | At most maxsplit splits are done (optional) |
If the separator is not found in the string, a list containing only 1 element is returned.
maxsplit argument to 1 because we only need to split the string once.The example removes everything after the first occurrence of the character in the string.
my_str = 'bobby!hadz!com' separator = '!' result_1 = my_str.split(separator, 1)[0] print(result_1) # 👉️ 'bobby' # 👇️ ['bobby', 'hadz!com'] print(my_str.split(separator, 1))
# Remove everything after a character, keeping the separator
Notice that the separator is not included in the string. If you need to include it, use the addition (+) operator.
my_str = 'bobby!hadz!com' # ✅ Remove everything after a character, keeping the separator separator = '!' result = my_str.split(separator, 1)[0] + separator print(result) # 👉️ bobby!
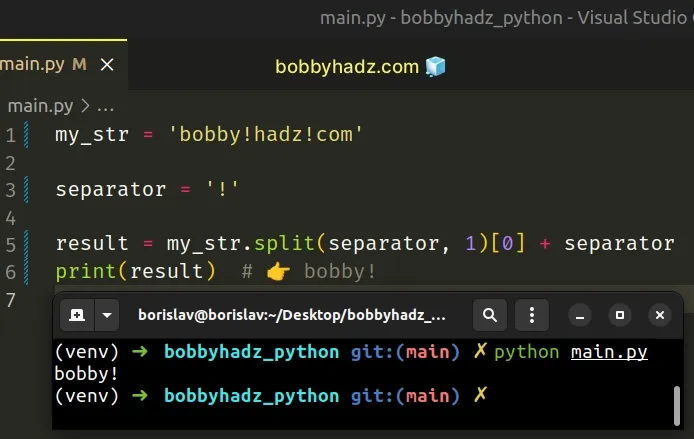
The addition (+) operator can be used to concatenate strings in Python.
Note: if you need to remove everything BEFORE a character, click on the following subheading:
# Remove everything after the Last occurrence of a character
If you need to remove everything after the last occurrence of the character in
the string, use the str.rsplit() method.
my_str = 'bobby!hadz!com' separator = '!' # ✅ Remove everything after the LAST occurrence of character result = my_str.rsplit(separator, 1)[0] print(result) # 👉️ 'bobby!hadz'
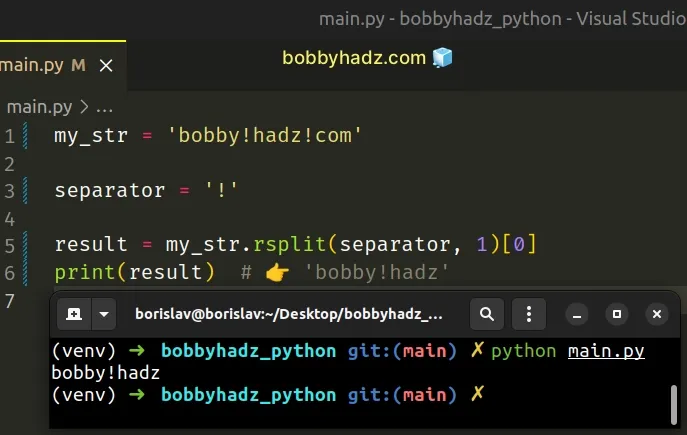
Except for splitting from the right, rsplit() behaves like split().
str.rsplit() method splits the string from the right, and with maxsplit set to 1, it only splits once.# Remove everything after the Last occurrence, keeping the separator
If you need to include the character you split on, use the addition operator (+).
my_str = 'bobby!hadz!com' separator = '!' result = my_str.rsplit(separator, 1)[0] + separator print(result) # 👉️ 'bobby!hadz!'
# Remove everything after a character using str.partition()
You can also use the str.partition() method to remove everything after a
specific character in a string.
my_str = 'bobby!hadz!com' separator = '!' result = my_str.partition(separator)[0] print(result) # 👉️ 'bobby' result = ''.join(my_str.partition(separator)[0:2]) print(result) # 👉️ 'bobby!'
The str.partition() method splits the string at the first occurrence of the provided separator.
The method returns a tuple containing 3 elements - the part before the separator, the separator, and the part after the separator.
my_str = 'bobby!hadz!com' separator = '!' # 👇️ ('bobby', '!', 'hadz!com') print(my_str.partition(separator))
If you need to include the separator in the result, use the str.join() method
to join the first and second list items.
my_str = 'bobby!hadz!com' separator = '!' result = ''.join(my_str.partition(separator)[0:2]) print(result) # 👉️ 'bobby!'
The str.join() method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The string the method is called on is used as the separator between the elements.
# Remove everything Before a Character in a String in Python
To remove everything before a character in a string:
- Use the
str.find()method to get the index of the character. - Use string slicing and set the
startindex to the index of the character. - The new string won't contain the preceding characters.
my_str = 'apple, banana' result = my_str[my_str.find('b'):] print(result) # 👉️ banana
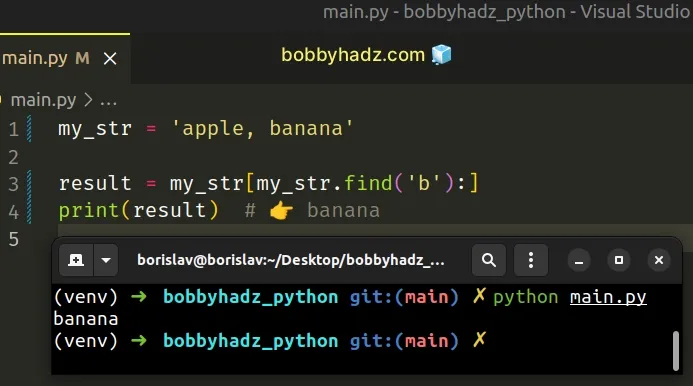
The str.find method returns the index of the first occurrence of the provided
substring in the string.
We used string slicing to get a part of the original string that starts at the index of the character and continues to the end of the string.
Note that the str.find() method returns -1 if the substring is not found in
the string.
# Handling a scenario where the character does not exist
You can handle the scenario where the find() method returns -1 in an
if/else statement.
my_str = 'apple, banana' index = my_str.find('b') print(index) # 👉️ 7 if index != -1: result = my_str[index:] else: result = my_str # 👉️ alternatively raise an error print(result) # 👉️ 'banana'
And, here is an example of a case where the provided character is not in the string.
my_str = 'apple, banana' index = my_str.find('z') print(index) # 👉️ -1 if index != -1: result = my_str[index:] else: result = my_str # 👉️ alternatively raise an error print(result) # 👉️ 'apple, banana'
Our else statement assigns the result variable to the entire string,
however, you could also raise an exception.
my_str = 'apple, banana' index = my_str.find('z') print(index) # 👉️ -1 if index != -1: result = my_str[index:] else: # 👇️ this runs raise IndexError('provided character not in string')
# Remove everything before the Last occurrence of a character
If you need to remove everything before the last occurrence of a character, use
the str.rfind() method.
my_str = 'apple,banana,bear' result = my_str[my_str.rfind('b'):] print(result) # 👉️ 'bear'
The str.rfind() method returns the highest index in the string where the provided substring is found.
The method returns -1 if the substring is not contained in the string.
You can handle the scenario where the character is not present in the string
with an if/else statement.
my_str = 'apple,banana,bear' index = my_str.rfind('b') if index != -1: result = my_str[index:] else: result = my_str print(result) # 👉️ 'bear'
If the else block runs, we set the result variable to the entire string.
Alternatively, you can raise an error in the else block, e.g.
raise IndexError('your message here').
# Remove everything before Last occurrence of character using rsplit()
This is a three-step process:
- Use the
str.rsplit()method to split the string from the right. - Access the list item at index
1. - The result will be a string containing everything after the last occurrence of the character.
my_str = 'example.com/articles/python' result = my_str.rsplit('/', 1)[1] print(result) # 👉️ 'python' # 👇️ if you want to include the character in the result result_2 = '/' + my_str.rsplit('/', 1)[1] print(result_2) # 👉️ '/python' # 👇️ ['example.com/articles', 'python'] print(my_str.rsplit('/', 1))
We used the str.rsplit() method to remove everything before the last
occurrence of a character.
The str.rsplit() method returns a list of the words in the string using the provided separator as the delimiter string.
my_str = 'one two three' print(my_str.rsplit(' ')) # 👉️ ['one', 'two', 'three'] print(my_str.rsplit(' ', 1)) # 👉️ ['one two', 'three']
The method takes the following 2 arguments:
| Name | Description |
|---|---|
| separator | Split the string into substrings on each occurrence of the separator |
| maxsplit | At most maxsplit splits are done, the rightmost ones (optional) |
Except for splitting from the right, rsplit() behaves like split().
1 for the maxsplit argument because we only want to split the string once, from the right.my_str = 'example.com/articles/python' result = my_str.rsplit('/', 1)[1] print(result) # 👉️ 'python' # 👇️ ['example.com/articles', 'python'] print(my_str.rsplit('/', 1))
The last step is to access the list element at index 1 to get a string
containing everything after the last occurrence of the specified character.
If you want to include the character in the result, use the addition (+) operator.
my_str = 'example.com/articles/python' result = '/' + my_str.rsplit('/', 1)[1] print(result) # 👉️ '/python'
# Remove everything before Last occurrence of Character using rpartition()
Alternatively, you can use the str.rpartition() method.
my_str = 'example.com/articles/python' result = my_str.rpartition('/')[2] print(result) # 👉️ 'python' # 👇️ ('example.com/articles', '/', 'python') print(my_str.rpartition('/'))
The str.rpartition() method splits the string at the last occurrence of the provided separator.
The method returns a tuple containing 3 elements - the part before the separator, the separator, and the part after the separator.
If you need to include the separator in the result, use the str.join() method
to join the second and third list items.
my_str = 'example.com/articles/python' result = ''.join(my_str.rpartition('/')[1:]) print(result) # 👉️ '/python'
The str.join() method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The string the method is called on is used as the separator between the elements.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Remove all Non-Numeric characters from a String in Python
- Remove First and Last Characters from a String in Python
- Remove first occurrence of character from String in Python
- Remove the First N characters from String in Python
- Remove the last N characters from a String in Python
- Remove Newline characters from a List or a String in Python
- Remove non-alphanumeric characters from a Python string
- Remove non-ASCII characters from a string in Python
- Remove the non utf-8 characters from a String in Python
- Remove characters matching Regex from a String in Python
- Remove special characters except Space from String in Python

