Python: How to ignore #comment lines in a File
Last updated: Apr 13, 2024
Reading time·3 min

# Python: How to ignore #comment lines in a File
To ignore #comment lines when reading a file in Python:
- Use the
with open()statement to open the file in reading mode. - Use a
forloop to iterate over the lines in the file. - Check if each line doesn't start with a comment.
Suppose we have the following example.txt file.
bobby # hadz #.com one # two three
Here is the related Python script.
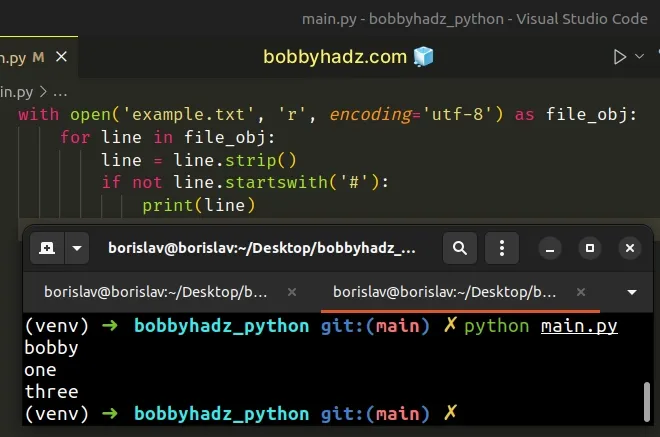
with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: line = line.strip() if not line.startswith('#'): print(line)
Running the code sample produces the following output.
bobby one three
The with open() statement takes care of closing the file after we're done reading from it.
We used a for loop to iterate over the lines in the file.
On each iteration, we used a negated call to the
str.startswith()
method to verify the string doesn't start with a hash #.
if not line.startswith('#'): print(line)
Notice that we also used the str.strip() method.
The str.strip() method returns a copy of the string with the specified leading and trailing characters removed.
You can also use the continue statement to achieve the same result.
with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: line = line.strip() if line.startswith('#'): continue print(line)
Running the code sample produces the following output.
bobby one three
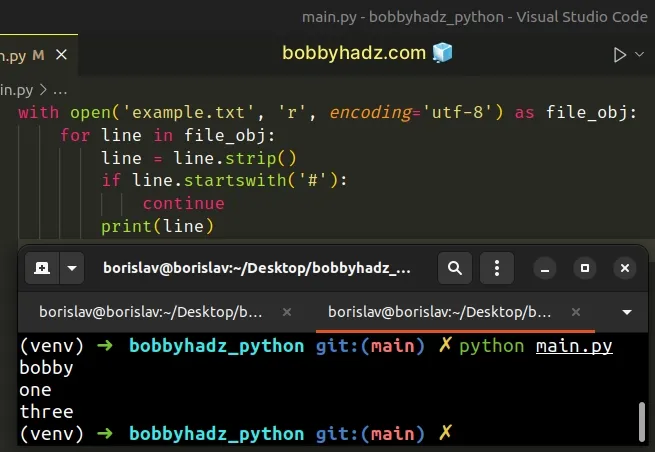
The continue statement continues with the next iteration of the loop.
If the line starts with a hash #, we simply skip to the next iteration.
If you also need to process the comment lines in a different way, use the else
statement.
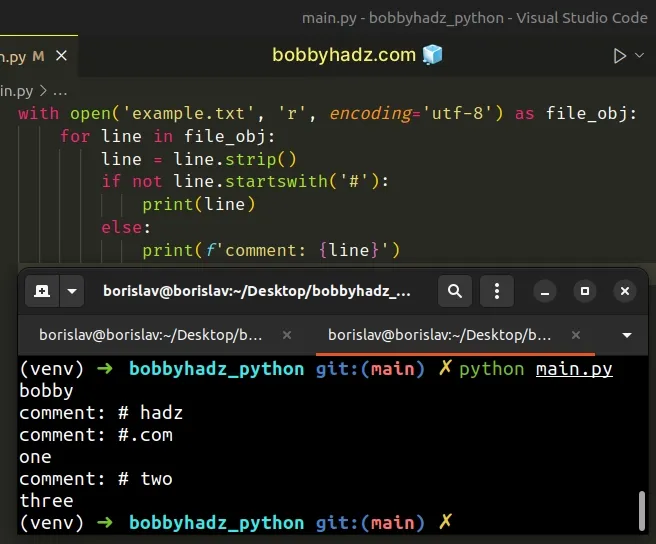
with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: line = line.strip() if not line.startswith('#'): print(line) else: print(f'comment: {line}')
Running the code sample produces the following output.
bobby comment: # hadz comment: #.com one comment: # two three
# Only ignoring the text after the hash #
If you only want to ignore the text after the hash # and not necessarily the
newline character, use the
str.partition()
method.
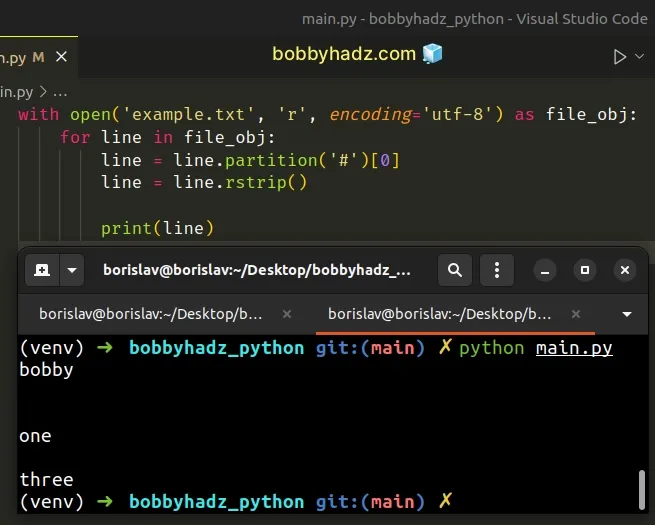
with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: line = line.partition('#')[0] line = line.rstrip() print(line)
Running the code sample produces the following output.
bobby one three
The str.partition method splits the string at the first occurrence of the
supplied separator.
# ('', '#', '.com') print('#.com'.partition('#'))
The method returns a tuple containing 3 elements - the part before the separator, the separator, and the part after the separator.
# Python: How to ignore #comment lines in a File using shlex
You can also use the shlex class from the shlex module to ignore #comment
lines in a file.
from shlex import shlex with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: lex_analyzer = shlex(line) lex_analyzer.whitespace = '\n' line = ''.join(list(lex_analyzer)) if not line: continue print(line)
Running the code sample produces the following output.
bobby one three
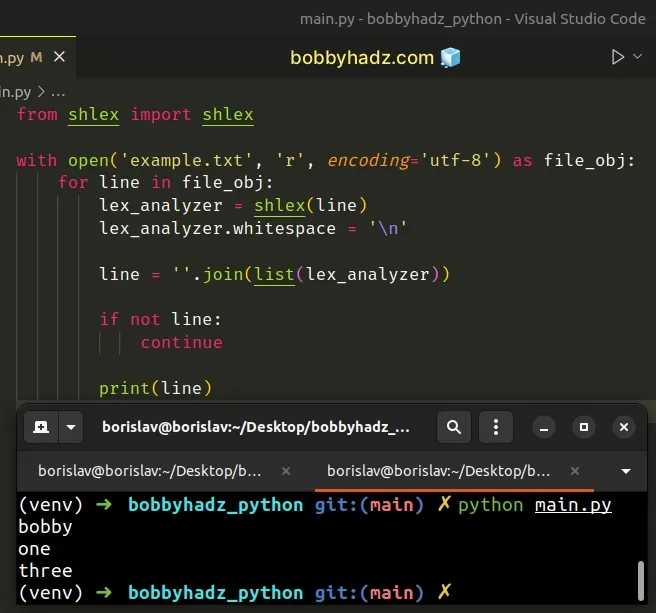
The shlex.shlex class creates a lexical analyzer object that is used for shell-like syntaxes.
I set the whitespace attribute to \n to remove the newlines.
lex_analyzer.whitespace = '\n'
If you don't want to strip the newlines, set the attribute to an empty string.
lex.whitespace = ''
If you need to get each line that doesn't contain a comment as a list of words,
use the shlex.split() method.
Suppose we have the following example.txt file.
bobby one two # hadz abc #.com def three # four five six
Here is the related Python script.
from shlex import split with open('example.txt', 'r', encoding='utf-8') as file_obj: for line in file_obj: line = split(line, comments=True) print(line) if not line: continue print(line)
Running the code sample produces the following output.
['bobby', 'one', 'two'] ['bobby', 'one', 'two'] [] [] ['three'] ['three'] [] ['five', 'six'] ['five', 'six']
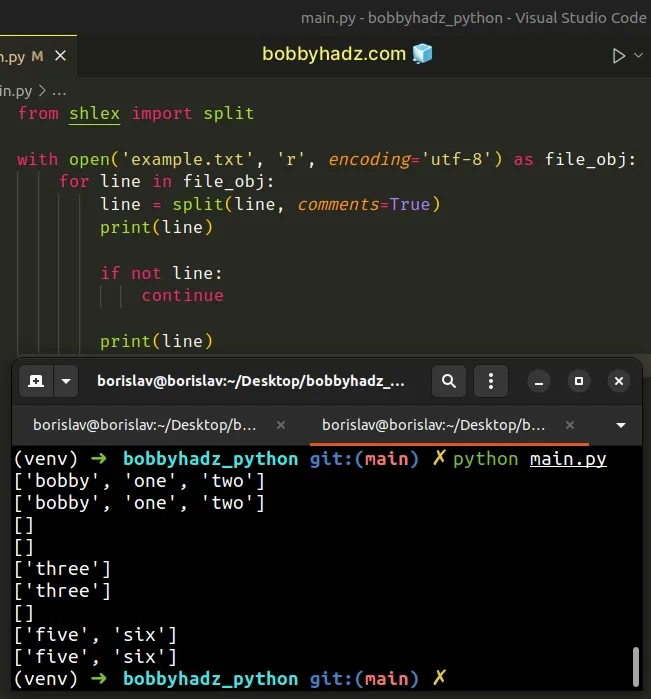
The shlex.split() method splits the supplied string using a shell-like syntax.
line = split(line, comments=True)
When the comments argument is set to True, the parsing of comments in the
given string is enabled.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

