Count number of unique Words/Characters in String in Python
Last updated: Apr 9, 2024
Reading time·8 min

# Table of Contents
- Count the number of unique words in a String in Python
- Count the unique words in a text File in Python
- Count the number of unique characters in a String in Python
# Count the number of unique words in a String in Python
To count the number of unique words in a string:
- Use the
str.split()method to split the string into a list of words. - Use the
set()class to convert the list to aset. - Use the
len()function to get the count of unique words in the string.
my_str = 'one one two two' unique_words = set(my_str.split()) print(unique_words) # 👉️ {'one', 'two'} length = len(unique_words) print(length) # 👉️ 2
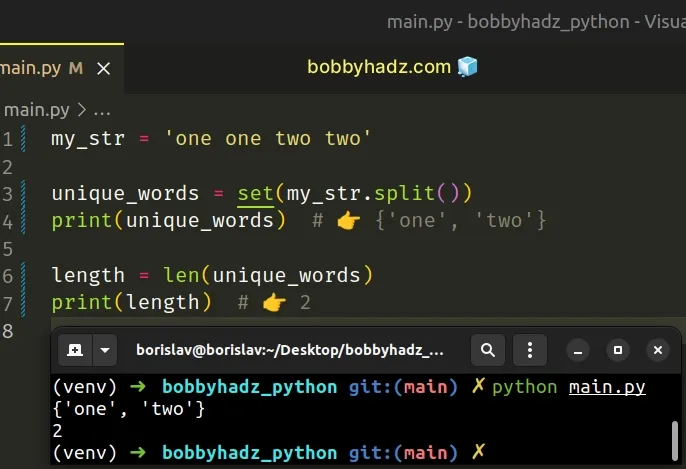
If you need to count the unique words in a file, click on the following subheading:
We first used the str.split() method to split the string into a list of words.
my_str = 'one one two two' print(my_str.split()) # 👉️ ['one', 'one', 'two', 'two']
The str.split() method splits the string into a list of substrings using a delimiter.
str.split() method, it splits the input string on one or more whitespace characters.The next step is to use the set() class to convert the list of words to a
set object.
my_str = 'one one two two' unique_words = set(my_str.split()) print(unique_words) # 👉️ {'one', 'two'}
The set() class takes an
iterable optional argument and returns a new set object with elements taken
from the iterable.
set removes all duplicate elements.The last step is to use the len() function to get the number of unique words.
my_str = 'one one two two' unique_words = set(my_str.split()) print(unique_words) # 👉️ {'one', 'two'} length = len(unique_words) print(length) # 👉️ 2
The len() function returns the length (the number of items) of an object.
# Count the unique words in a text File in Python
To count the unique words in a text file:
- Read the contents of the file into a string and split it into words.
- Use the
set()class to convert the list to asetobject. - Use the
len()function to count the unique words in the text file.
with open('example.txt', 'r', encoding='utf-8') as f: words = f.read().split() print(words) # 👉️ ['one', 'one', 'two', 'two', 'three', 'three'] unique_words = set(words) print(len(unique_words)) # 👉️ 3 print(unique_words) # {'three', 'one', 'two'}
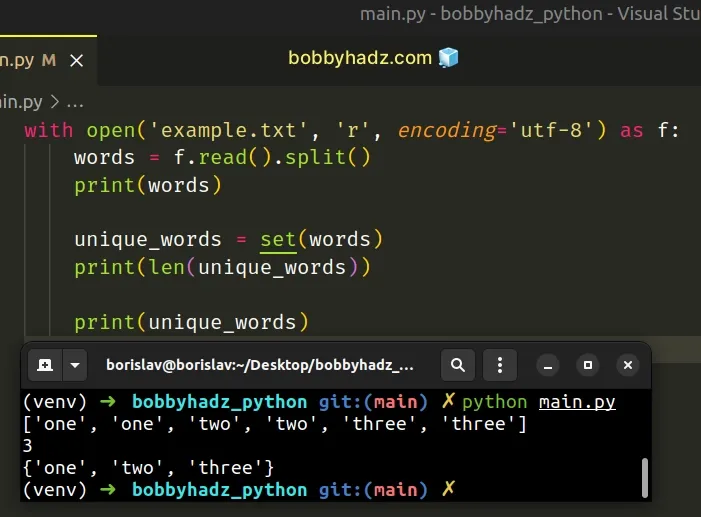
The example above assumes that you have a file named example.txt with the
following contents.
one one two two three three
We opened the file in reading mode and used the read() method to read its
contents into a string.
The next step is to use the str.split() method to split the string into a list
of words.
with open('example.txt', 'r', encoding='utf-8') as f: words = f.read().split() print(words) # 👉️ ['one', 'one', 'two', 'two', 'three', 'three']
The str.split() method splits the string into a list of substrings using a delimiter.
str.split() method, it splits the input string on one or more whitespace characters.We used the set() class to convert the list to a set object.
with open('example.txt', 'r', encoding='utf-8') as f: words = f.read().split() print(words) # 👉️ ['one', 'one', 'two', 'two', 'three', 'three'] unique_words = set(words) print(len(unique_words)) # 👉️ 3 print(unique_words) # {'three', 'one', 'two'}
The set() class takes an
iterable optional argument and returns a new set object with elements taken
from the iterable.
set removes all duplicate elements.The last step is to use the len() function to get the count of unique words in
the file.
The len() function returns the length (the number of items) of an object.
The argument the function takes may be a sequence (a string, tuple, list, range or bytes) or a collection (a dictionary, set, or frozen set).
# Count the number of unique words in a String using for loop
This is a five-step process:
- Declare a new variable that stores an empty list.
- Use the
str.split()method to split the string into a list of words. - Use a
forloop to iterate over the list. - Use the
list.append()method to append all unique words to the list. - Use the
len()function to get the length of the list.
my_str = 'one one two two' unique_words = [] for word in my_str.split(): if word not in unique_words: unique_words.append(word) print(len(unique_words)) # 👉️ 2 print(unique_words) # 👉️ ['one', 'two']
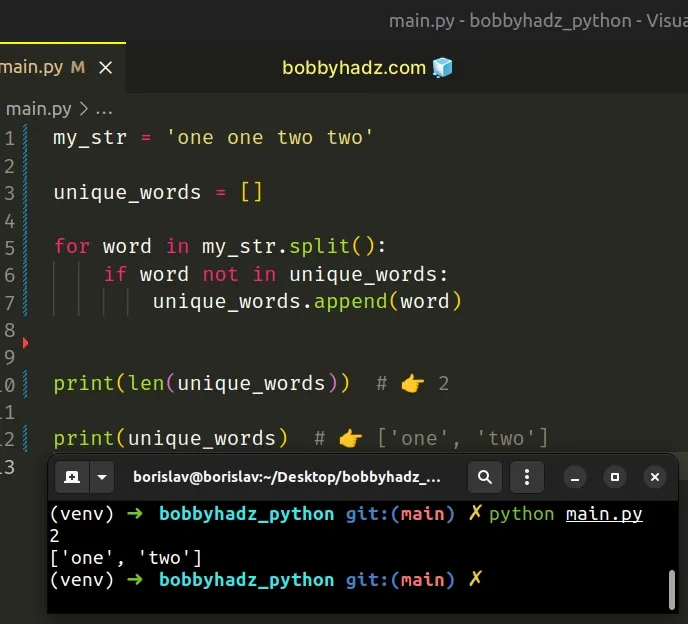
We used the str.split() method to split the string into a list of words and
used a for loop to iterate over the list.
On each iteration, we use the not in operator to check if the element is not
present in the list.
The in operator tests
for membership. For example, x in l evaluates to True if x is a member of
l, otherwise it evaluates to False.
x not in l returns the negation of x in l.The list.append() method adds an item to the end of the list.
my_list = ['bobby', 'hadz'] my_list.append('com') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The last step is to use the len() function to get the number of unique words
in the string.
# Count the unique words in a text File using a for loop
This is a five-step process:
- Declare a new variable that stores an empty list.
- Read the contents of the file into a string and split it into words.
- Use a
forloop to iterate over the list. - Use the
list.append()method to append all unique words to the list. - Use the
len()function to get the length of the list.
unique_words = [] with open('example.txt', 'r', encoding='utf-8') as f: words = f.read().split() print(words) # 👉️ ['one', 'one', 'two', 'two', 'three', 'three'] for word in words: if word not in unique_words: unique_words.append(word) print(len(unique_words)) # 👉️ 3 print(unique_words) # 👉️ ['one', 'two', 'three']
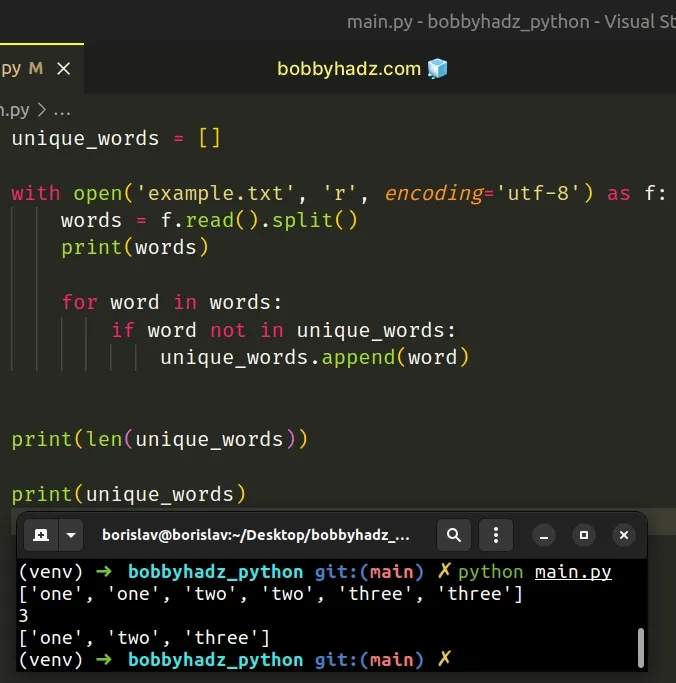
We read the contents of the file into a string and used the str.split() method
to split the string into a list of words.
On each iteration, we use the not in operator to check if the word is not
present in the list of unique words.
If the condition is met, we use the list.append() method to append the value
to the list.
The in operator tests
for membership. For example, x in l evaluates to True if x is a member of
l, otherwise it evaluates to False.
x not in l returns the negation of x in l.The list.append() method adds an item to the end of the list.
my_list = ['bobby', 'hadz'] my_list.append('com') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The last step is to use the len() function to get the count of unique words in
the text file.
# Count the number of unique characters in a String in Python
To count the number of unique characters in a string:
- Use the
set()class to convert the string to asetof unique characters. - Use the
len()function to get the number of unique characters in the string.
my_str = 'bobby' # ✅ using set() result = len(set(my_str)) print(result) # 👉️ 3
If you need to get the unique characters in a string, use the following code sample instead.
my_str = 'bobby' # ✅ Get unique characters in a string (order not preserved) result = ''.join(set(my_str)) print(result) # 👉️ byo
The example uses the set() class to count the number of unique characters in a
string.
The set() class takes an
iterable optional argument and returns a new set object with elements taken
from the iterable.
my_str = 'bobby' print(set(my_str)) # 👉️ {'y', 'b', 'o'}
set removes all duplicate characters.The last step is to use the len() function to get the total count.
my_str = 'bobby' result = len(set(my_str)) print(result) # 👉️ 3
The len() function returns the length (the number of items) of an object.
If you need to get the unique characters in the string, use the str.join()
method instead of the len() function.
my_str = 'bobby' result = ''.join(set(my_str)) print(result) # 👉️ byo
The str.join method takes an iterable as an argument and returns a string which is the concatenation of the strings in the iterable.
The string the method is called on is used as the separator between the elements.
Alternatively, you can use the dict.fromkeys() method.
# Count the number of unique characters in a String using dict.fromkeys()
This is a two-step process:
- Use the
dict.fromkeys()method to create a dictionary from the string. - Use the
len()function to get the number of unique characters in the string.
my_str = 'bobby' result = len(dict.fromkeys(my_str)) print(result) # 👉️ 3
If you need to get the unique characters, use the following code sample instead.
my_str = 'bobby' result = ''.join(dict.fromkeys(my_str).keys()) print(result) # 👉️ boy
The dict.fromkeys method takes an iterable and a value and creates a new dictionary with keys from the iterable and values set to the provided value.
my_str = 'bobby' # 👇️ {'b': None, 'o': None, 'y': None} print(dict.fromkeys(my_str))
Dictionary keys are unique, so any duplicate characters get removed.
If you need to get the unique characters in the string, use the str.join()
method instead of the len() function.
my_str = 'bobby' result = ''.join(dict.fromkeys(my_str).keys()) print(result) # 👉️ boy
We used the dict.keys() method to get a view of the dictionary's keys and
joined the object into a string.
Dictionaries preserve the insertion order of keys in Python 3.7 and more recent version.
Alternatively, you can use a simple for loop.
# Count the number of unique characters in a String using for loop
This is a four-step process:
- Declare a new variable that stores an empty list.
- Use a
forloop to iterate over the string. - Use the
list.append()method to append all unique characters to the list. - Use the
len()function to get the length of the list.
my_str = 'bobby' unique_chars = [] for char in my_str: if char not in unique_chars: unique_chars.append(char) print(len(unique_chars)) # 👉️ 3 print(unique_chars) # 👉️ ['b', 'o', 'y']
We used a for loop to iterate over the string.
On each iteration, we use the not in operator to check if the character is not
present in the list.
If the condition is met, we use the list.append() method to append the
character to the list.
The in operator tests
for membership. For example, x in l evaluates to True if x is a member of
l, otherwise it evaluates to False.
x not in l returns the negation of x in l.The list.append() method adds an item to the end of the list.
my_list = ['bobby', 'hadz'] my_list.append('com') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The last step is to use the len() function to get the length of the list of
unique characters.

