Python: How to calculate the MD5 Hash of a File
Last updated: Apr 13, 2024
Reading time·4 min

# Table of Contents
- Python: How to calculate the MD5 Hash of a File
- Using the open() function directly
- Verifying the returned MD5 hash
- Calculate the MD5 Hash of a large File in chunks
- Using the hashlib.file_digest() method (Python3.11+)
- Calculate the MD5 Hash of a File using mmap
- Using a pathlib.Path object instead
# Python: How to calculate the MD5 Hash of a File
To calculate the MD5 hash of a file in Python:
- Use the
with open()statement to open the file inrb(read bytes) mode. - Use the
file.read()method to read the file's contents. - Use the
hashlib.md5().hexdigest()method to get the MD5 hash of the file.
Suppose we have the following example.txt file.
bobby hadz com
Here is the related Python script.
import hashlib file_name = 'example.txt' with open(file_name, 'rb') as file_obj: file_contents = file_obj.read() md5_hash = hashlib.md5(file_contents).hexdigest() # 👇️ cfd2db7dd4ffe42ce26e0b57e7e8b342 print(md5_hash)
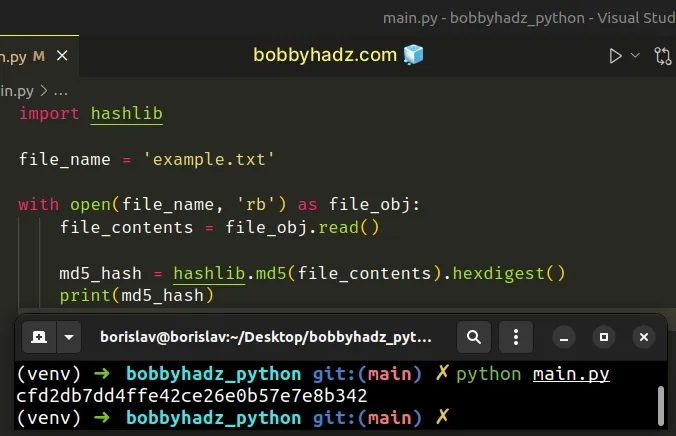
We used the with open()
statement to open the file in rb (read binary) mode.
with open() statement takes care of closing the file after we're done, even if an exception occurs.The next step is to read the contents of the file into a string with
file.read().
The hash.hexdigest() method returns the digest as a string.
If you need to take the file path from user input, check out this article.
# Using the open() function directly
If you use the older syntax that uses the open() function directly, make sure
to manually close the file.
import hashlib file_name = 'example.txt' file_obj = open(file_name, 'rb') file_contents = file_obj.read() md5_hash = hashlib.md5(file_contents).hexdigest() # 👇️ cfd2db7dd4ffe42ce26e0b57e7e8b342 print(md5_hash) file_obj.close()
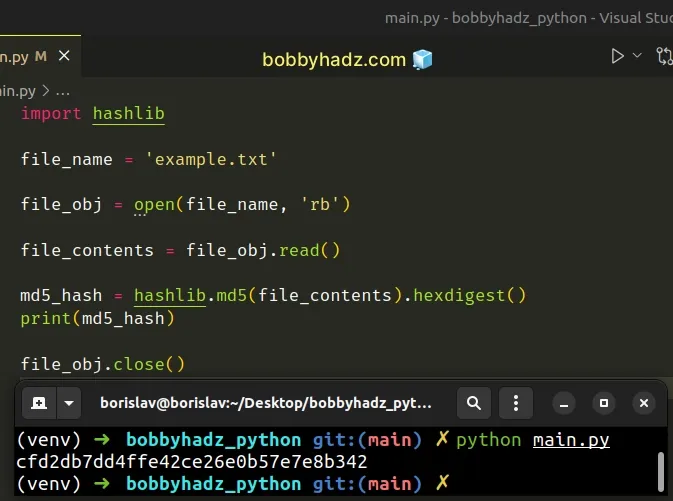
This helps you avoid memory leaks in your Python program.
# Verifying the returned MD5 hash
If you need to compare the returned MD5 hash against a string, use the equality operator.
import hashlib file_name = 'example.txt' md5_hash_original = 'cfd2db7dd4ffe42ce26e0b57e7e8b342' with open(file_name, 'rb') as file_obj: file_contents = file_obj.read() md5_hash_new = hashlib.md5(file_contents).hexdigest() print(md5_hash_new) if md5_hash_original == md5_hash_new: print('MD5 hash verified') else: print('MD5 hash verification failed')
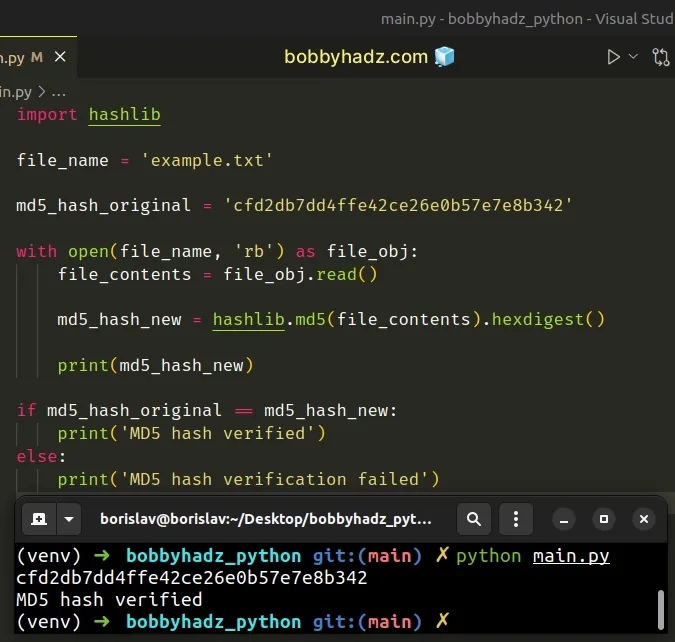
If the returned MD5 hash matches, the if block runs, otherwise, the else
block runs.
# Calculate the MD5 Hash of a large File in chunks
If you're working with a relatively large file, you might not want to read its entire contents in memory.
In this case, you can use file.read() with a specific number of bytes to read
the file in chunks.
Suppose we have the same example.txt file.
bobby hadz com
Here is the related Python code.
import hashlib file_name = 'example.txt' with open(file_name, 'rb') as file_obj: md5_hash = hashlib.md5() while chunk := file_obj.read(4096): md5_hash.update(chunk) # 👇️ as a string print(md5_hash.hexdigest()) # 👇️ or as bytes print(md5_hash.digest())
Running the code sample produces the following output.
b'\xcf\xd2\xdb}\xd4\xff\xe4,\xe2n\x0bW\xe7\xe8\xb3B' cfd2db7dd4ffe42ce26e0b57e7e8b342
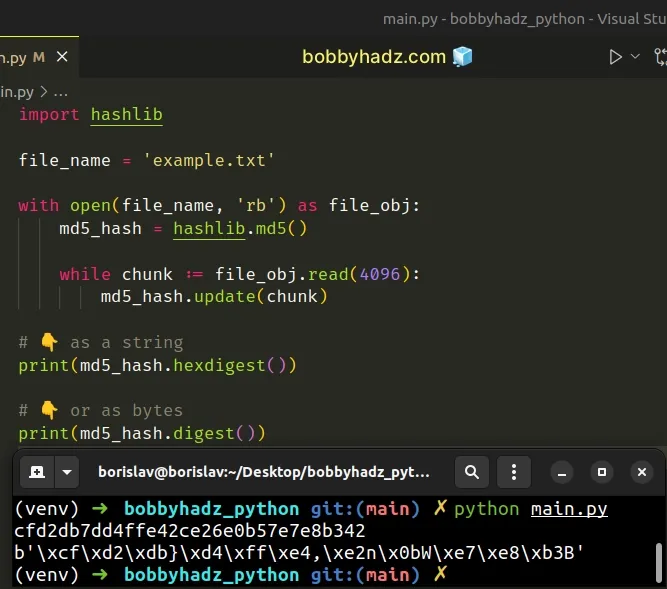
We opened the file in rb (read binary) mode and used a while loop to iterate
over the file's contents in chunks of 4096 bytes.
On each iteration, we update the hash with the current chunk.
You can use the hash.hexdigest() method to print the hash as a string or the
hash.digest() method to print it as bytes.
If you have to do this often, define a reusable function.
import hashlib def get_md5_hash(file_path, block_size=4096): with open(file_path, 'rb') as file_obj: md5_hash = hashlib.md5() while chunk := file_obj.read(block_size): md5_hash.update(chunk) return md5_hash.hexdigest() file_name = 'example.txt' print(get_md5_hash(file_name))
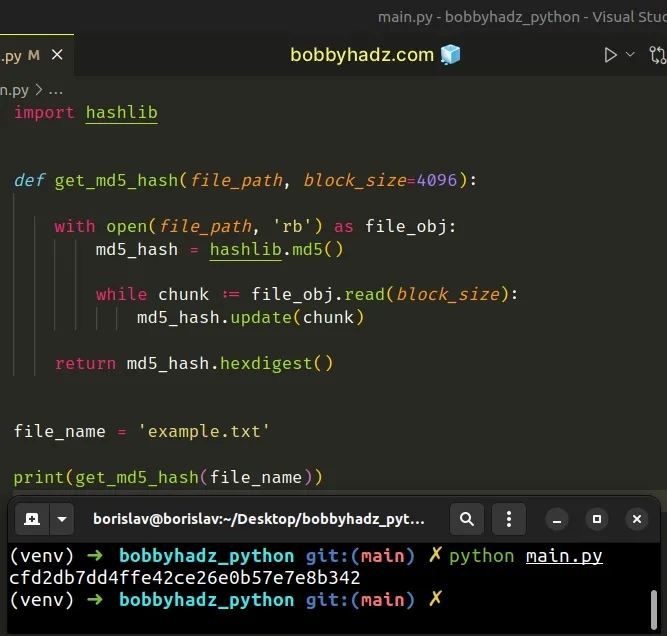
The function takes the file path and the block size as arguments and returns the MD5 hash of the file.
You can achieve the same result by using a for loop.
import hashlib def get_md5_hash(file_path, block_size=4096): with open(file_path, 'rb') as file_obj: md5_hash = hashlib.md5() for chunk in iter( lambda: file_obj.read(block_size), b'' ): md5_hash.update(chunk) return md5_hash.hexdigest() file_name = 'example.txt' print(get_md5_hash(file_name))
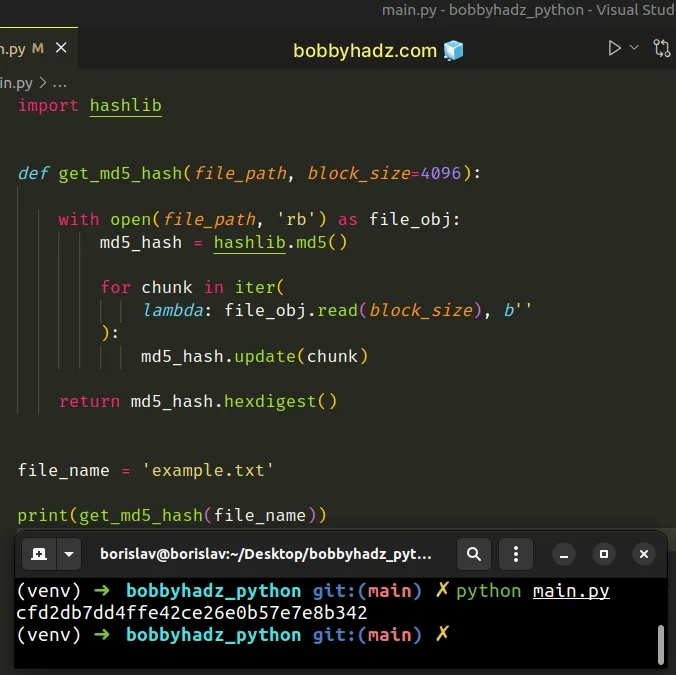
# Using the hashlib.file_digest() method (Python3.11+)
If your Python version is greater than 3.11, you can also use the efficient
hashlib.file_digest
method.
You can check your Python version with the python --version command.
python --version # or python3 python3 --version
If your Python version is greater than 3.11, try using the
hashlib.file_digest() method.
import hashlib file_name = 'example.txt' with open(file_name, 'rb') as file_obj: digest = hashlib.file_digest(file_obj, 'md5') print(digest.hexdigest())
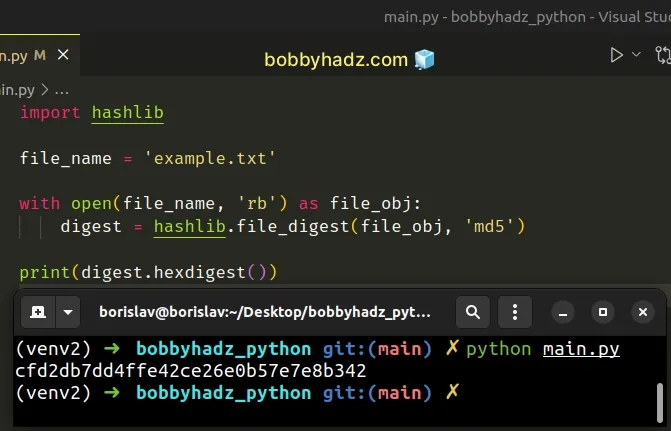
The hashlib.file_digest() method takes a file object and a digest as
parameters and returns a digest object that has been updated with the contents
of the file object.
The digest argument must either be a hash algorithm name as a string, a hash
constructor or a callable that returns a hash object.
Note that the hashlib.file_digest() method is introduced in Python v3.11.
# Calculate the MD5 Hash of a File using mmap
You can slo use the
mmap() class from the
mmap module to calculate the hash of a file.
from mmap import mmap, ACCESS_READ from hashlib import md5 file_name = 'example.txt' with open(file_name, 'rb') as file, mmap( file.fileno(), 0, access=ACCESS_READ) as file: print(md5(file).hexdigest())
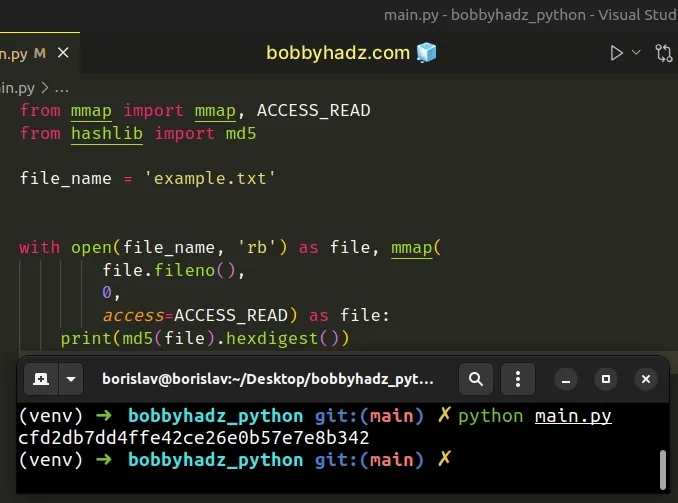
The mmap() class maps N bytes from the file and returns a mmap object.
We set the length argument to 0, so the max length of the map will be the
current size of the file when mmap is called.
# Using a pathlib.Path object instead
The pathlib.Path
class is used to create a PosixPath or a WindowsPath object depending on
your operating system.
If your code should be able to run on both Windows and Unix, use the
pathlib.Path class to construct a PurePath.
import pathlib import hashlib file_name = 'example.txt' path_obj = pathlib.Path(file_name) md5_hash = hashlib.md5(path_obj.read_bytes()).hexdigest() print(md5_hash)
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

