ValueError: pattern contains no capture groups [Solved]
Last updated: Apr 13, 2024
Reading time·4 min

# Table of Contents
- ValueError: pattern contains no capture groups
- Use parentheses to specify capture groups
- Using a named capture group to name the DataFrame column
- Getting the result of calling str.extract() as a Series
# ValueError: pattern contains no capture groups [Solved]
The Pandas "ValueError: pattern contains no capture groups" occurs when you
use the DataFrame.str.extract() method with a regular expression that doesn't
contain any capture groups.
To solve the error use parentheses to specify capture groups inside your regular expression.
Here is an example of how the error occurs.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) # ⛔️ ValueError: pattern contains no capture groups new_df = df['name'].str.extract(r'[a-zA-Z]+\d') print(new_df)
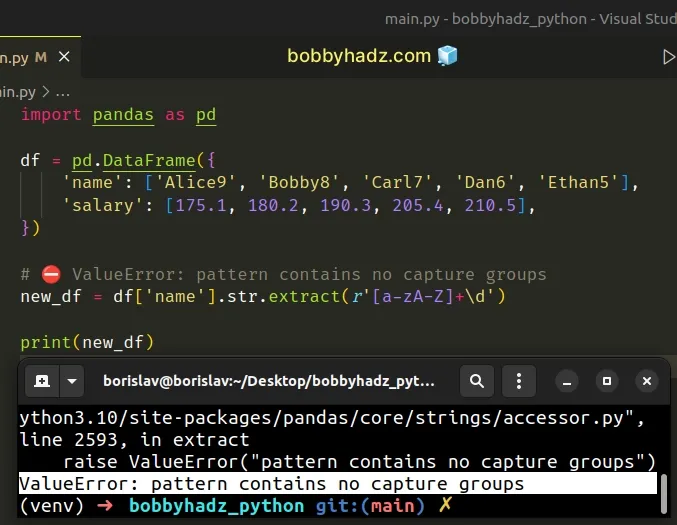
The issue in the code sample is that we didn't use any capture groups with the str.extract() method.
# Use parentheses to specify capture groups
You have to use parentheses to specify capture group(s) when calling
str.extract.
Each capture group in the regex pattern is a separate DataFrame column in the
output.
Here in an example that uses 2 capture groups when calling str.extract().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) new_df = df['name'].str.extract(r'([a-zA-Z]+)(\d)') print(new_df)
Running the code sample produces the following output.
0 1 0 Alice 9 1 Bobby 8 2 Carl 7 3 Dan 6 4 Ethan 5
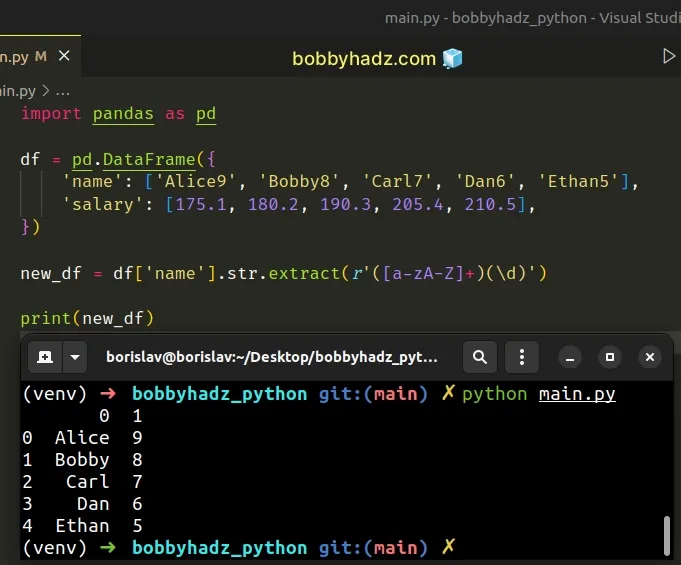
Notice that we have 2 capture groups (2 sets of parentheses).
new_df = df['name'].str.extract(r'([a-zA-Z]+)(\d)') # 0 1 # 0 Alice 9 # 1 Bobby 8 # 2 Carl 7 # 3 Dan 6 # 4 Ethan 5 print(new_df)
The first column in the resulting DataFrame contains the values from the first
capture group and the next column contains the values from the second capture
group.
The square brackets [] are used to indicate a set of characters.
new_df = df['name'].str.extract(r'([a-zA-Z]+)(\d)')
The a-z and A-Z characters represent the lowercase and uppercase letter
ranges.
The + character matches the preceding character one or more times.
The \d special character matches any digit in the range of 0 to 9.
If you only need to get the name of each person, you would only use one capture
group ().
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) new_df = df['name'].str.extract(r'([a-zA-Z]+)\d') # 0 # 0 Alice # 1 Bobby # 2 Carl # 3 Dan # 4 Ethan print(new_df)
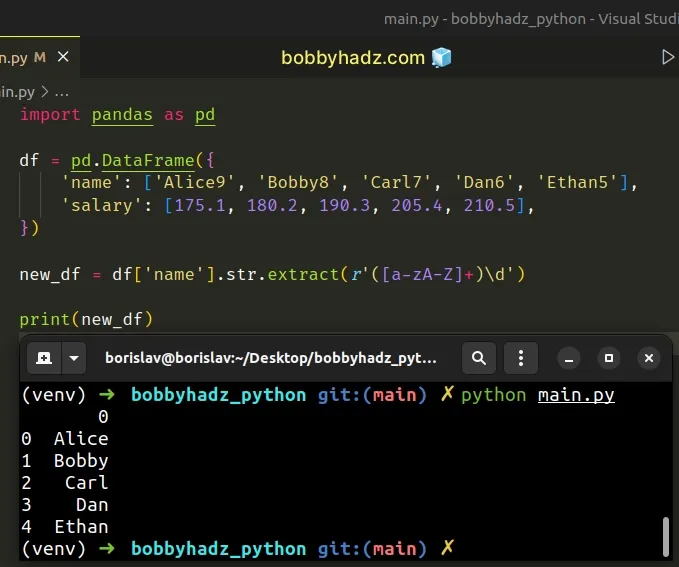
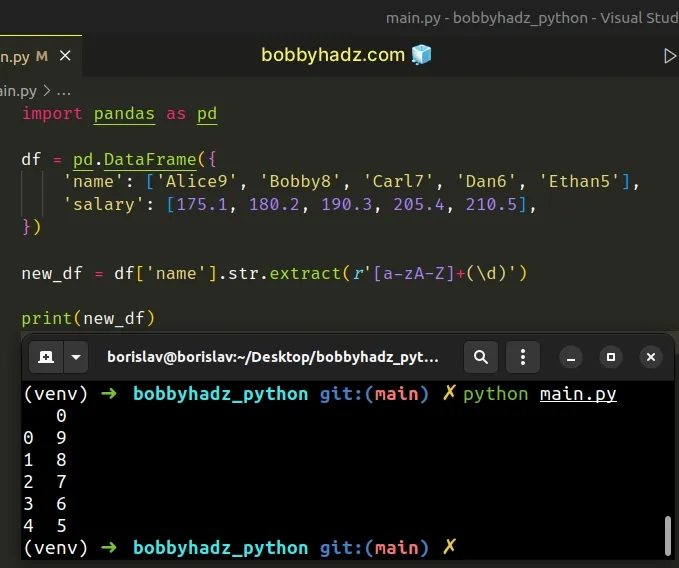
Similarly, if you only need to get the digit after each name, you would wrap the
\d special character in parentheses.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) new_df = df['name'].str.extract(r'[a-zA-Z]+(\d)') # 0 # 0 9 # 1 8 # 2 7 # 3 6 # 4 5 print(new_df)
# Using a named capture group to name the DataFrame column
If you need to name the DataFrame columns in the output, use named capture
groups.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) new_df = df['name'].str.extract(r'(?P<first_name>[a-zA-Z]+)\d') # first_name # 0 Alice # 1 Bobby # 2 Carl # 3 Dan # 4 Ethan print(new_df)
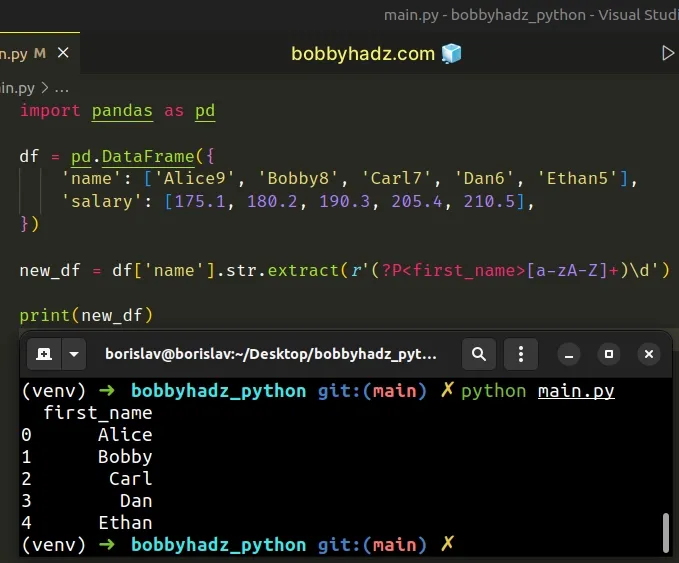
The syntax for a named capture group is ?P<GROUP_NAME>.
We set the name of the capture group to first_name in the example.
We could also repeat the process to name the capture group of the digit after each name.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) new_df = df['name'].str.extract( r'(?P<first_name>[a-zA-Z]+)(?P<id>\d)' ) # first_name id # 0 Alice 9 # 1 Bobby 8 # 2 Carl 7 # 3 Dan 6 # 4 Ethan 5 print(new_df)
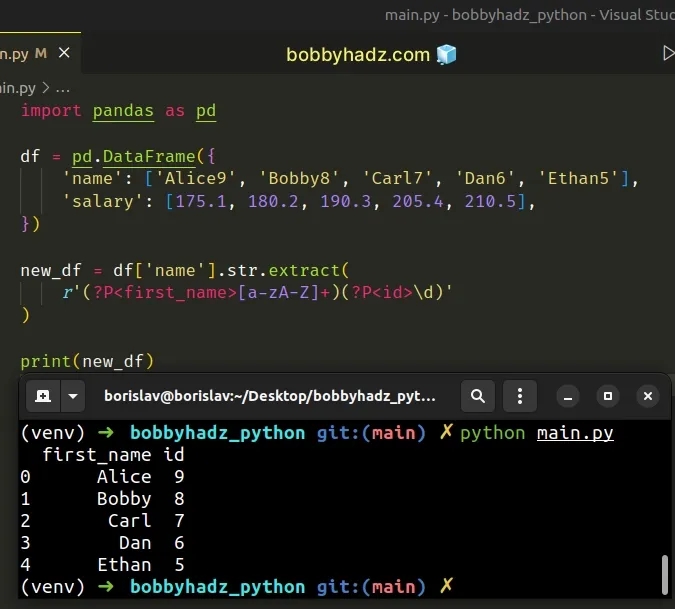
We named the first capture group first_name and the second id.
# Getting the result of calling str.extract() as a Series
If you need to get the output of the str.extract() method as a Series, set
the expand argument to False.
import pandas as pd df = pd.DataFrame({ 'name': ['Alice9', 'Bobby8', 'Carl7', 'Dan6', 'Ethan5'], 'salary': [175.1, 180.2, 190.3, 205.4, 210.5], }) series = df['name'].str.extract( r'([a-zA-Z]+)\d', expand=False ) print(series) print('-' * 50) print(type(series)) print('-' * 50) print(series[0])
Running the code sample produces the following output.
0 Alice 1 Bobby 2 Carl 3 Dan 4 Ethan Name: name, dtype: object -------------------------------------------------- <class 'pandas.core.series.Series'> -------------------------------------------------- Alice
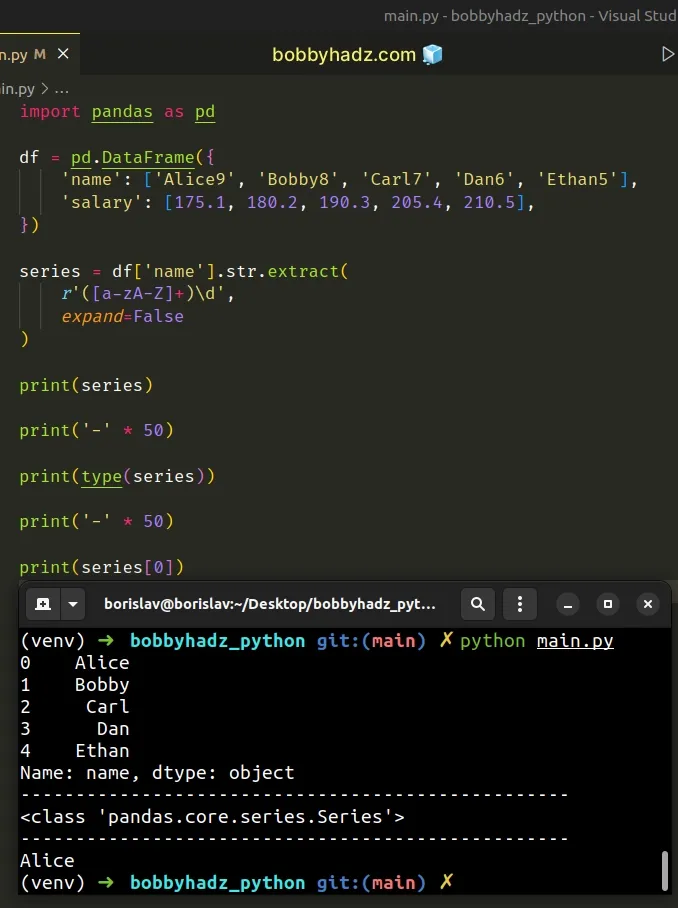
Notice that we set the expand argument to False when calling
str.extract().
series = df['name'].str.extract( r'([a-zA-Z]+)\d', expand=False )
When the expand argument is set to True, the method returns a DataFrame
with a separate column for each capture group.
When the argument is set to False:
- the method returns a
Seriesif there is one capture group. - the method returns a
DataFrameif there are multiple capture groups.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

