Parse a URL query string to get query parameters in Python
Last updated: Apr 9, 2024
Reading time·2 min

# Parse a URL query string to get query parameters in Python
To parse a URL query string and get query parameters:
- Import the
urlparseandparse_qsmethods from theurllib.parsemodule. - Use the
urlparsemethod to get a parse result object. - Pass the object to the
parse_qsmethod to get a dictionary of the query params.
from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC' parse_result = urlparse(url) # 👇️ "page=10&limit=15&price=ASC" print(parse_result) dict_result = parse_qs(parse_result.query) # 👇️ {'page': ['10'], 'limit': ['15'], 'price': ['ASC']} print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ 'ASC'
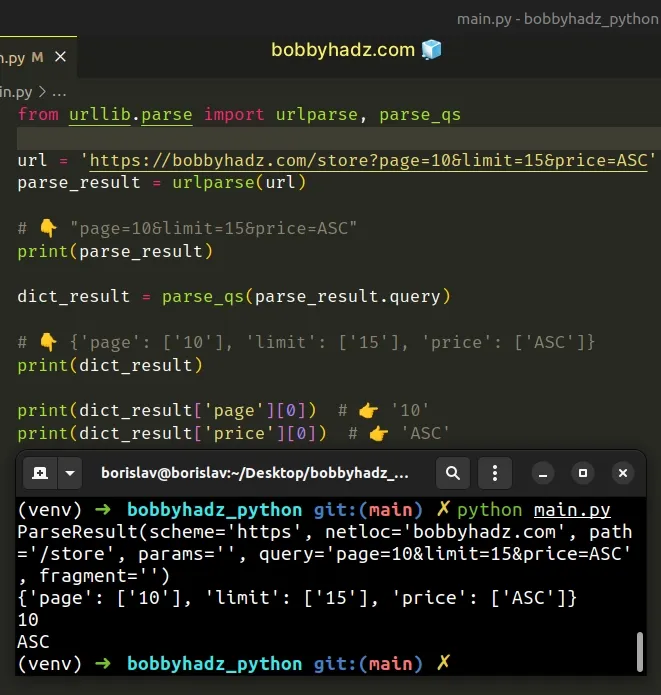
We used the urlparse() and parse_qs() methods from the urllib.parse module to parse a URL query string.
The urlparse method takes a URL and parses it into six components.
from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC' parse_result = urlparse(url) # 👇️ ParseResult(scheme='https', netloc='bobbyhadz.com', path='/store', params='', query='page=10&limit=15&price=ASC', fragment='') print(parse_result) # 👇️ page=10&limit=15&price=ASC print(parse_result.query)
We can access the query attribute on the object to get the query string.
Notice that other components like path and fragment are also available.
from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC#my-fragment' parse_result = urlparse(url) # 👇️ page=10&limit=15&price=ASC print(parse_result.query) # 👇️ /store print(parse_result.path) # 👇️ my-fragment print(parse_result.fragment)
# Getting a dictionary containing the URL's query parameters
After we parse the URL and get the query string, we can pass the string to the
parse_qs method to get a dictionary containing the URL's query parameters.
from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price=ASC#my-fragment' parse_result = urlparse(url) # 👇️ "page=10&limit=15&price=ASC" print(parse_result) dict_result = parse_qs(parse_result.query) # 👇️ {'page': ['10'], 'limit': ['15'], 'price': ['ASC']} print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ 'ASC'
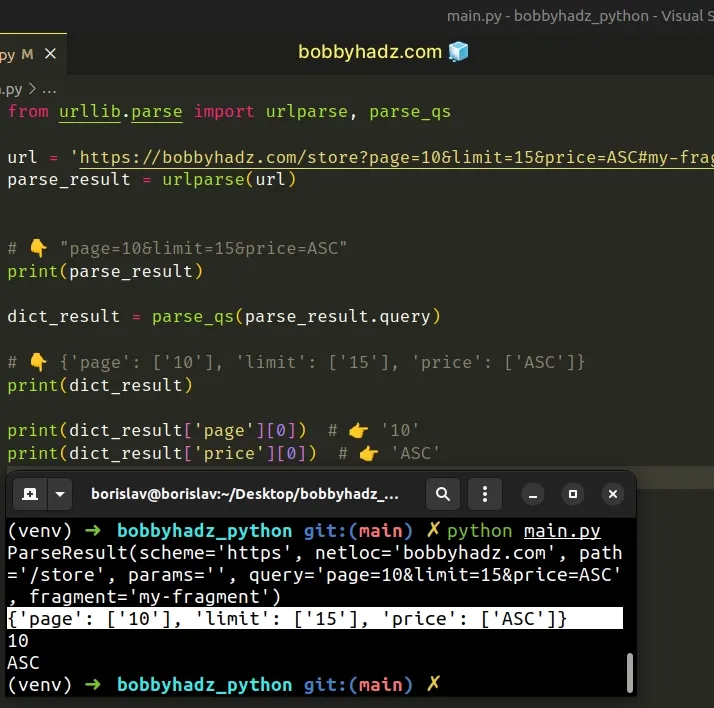
The parse_qs() method parses the given query string and returns the results as
a dictionary.
The dictionary keys are the names of the query parameters and the values are lists that store the values for each parameter.
0 unless you have a query param with multiple values).# Keeping query parameters without values in the results
If your URL has query parameters without values that you want to keep in the
results, set the keep_blank_values argument to True when calling parse_qs.
from urllib.parse import urlparse, parse_qs url = 'https://bobbyhadz.com/store?page=10&limit=15&price' parse_result = urlparse(url) print(parse_result) dict_result = parse_qs(parse_result.query, keep_blank_values=True) # 👇️ {'page': ['10'], 'limit': ['15'], 'price': ['']} print(dict_result) print(dict_result['page'][0]) # 👉️ '10' print(dict_result['price'][0]) # 👉️ ""
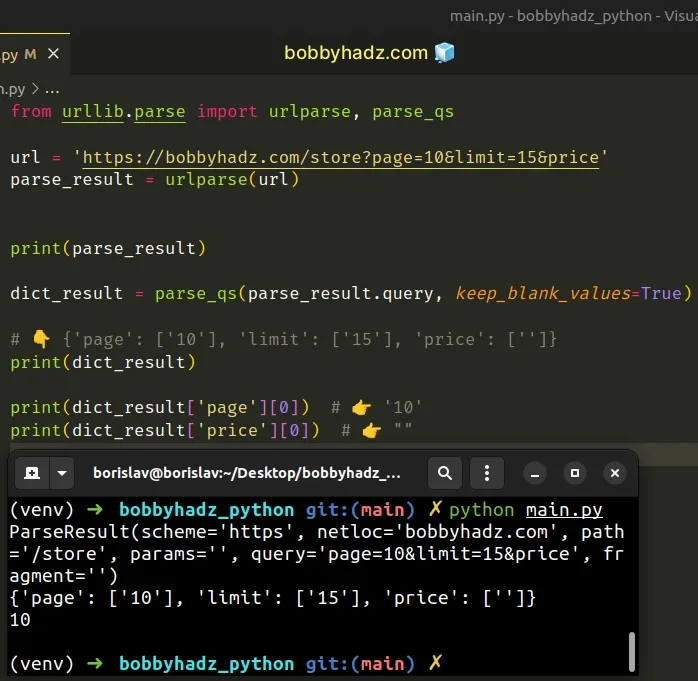
Even though the price query parameter doesn't have a value specified, it is
still included in the dictionary if keep_blank_values is set to True.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

