How to get the base of a URL in Python
Last updated: Apr 9, 2024
Reading time·2 min

# Get the base of a URL in Python
To get the base of a URL:
- Pass the URL to the
urlparsemethod from theurllib.parsemodule. - Access the
netlocattribute on the parse result.
from urllib.parse import urlparse my_url = 'https://bobbyhadz.com/images/wallpaper.jpg' parsed = urlparse(my_url) # 👇️ ParseResult(scheme='https', netloc='bobbyhadz.com', path='/images/wallpaper.jpg', params='', query='', fragment='') print(parsed) base = parsed.netloc print(base) # 👉️ bobbyhadz.com path = parsed.path print(path) # 👉️ /images/wallpaper.jpg with_path = base + '/'.join(path.split('/')[:-1]) print(with_path) # 👉️ bobbyhadz.com/images print(path.split('/')) # 👉️ ['', 'images', 'wallpaper.jpg']
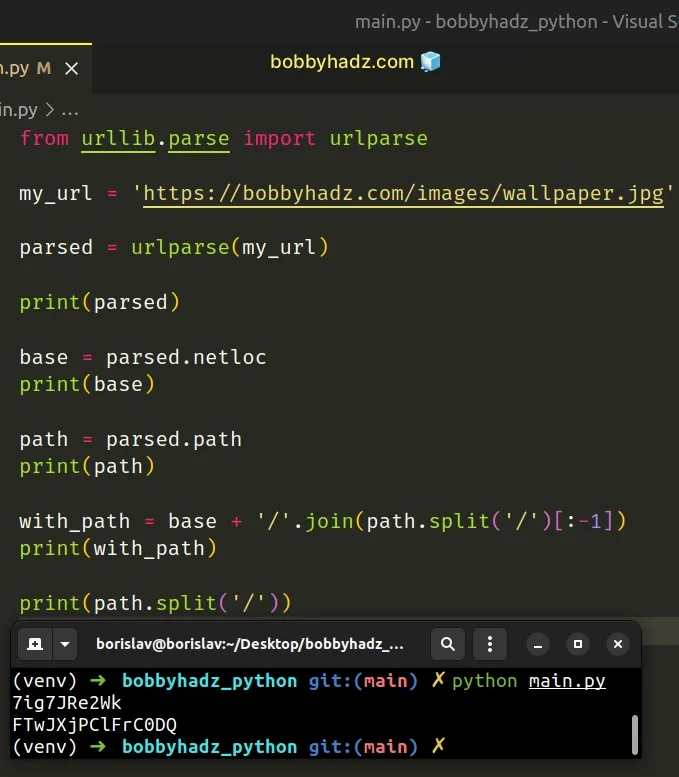
We used the urlparse() method from the urllib.parse module.
The urlparse method takes a URL and parses it into six components.
from urllib.parse import urlparse my_url = 'https://bobbyhadz.com/images/wallpaper.jpg' parsed = urlparse(my_url) # 👇️ ParseResult(scheme='https', netloc='bobbyhadz.com', path='/images/wallpaper.jpg', params='', query='', fragment='') print(parsed) base = parsed.netloc print(base) # 👉️ bobbyhadz.com path = parsed.path print(path) # 👉️ /images/wallpaper.jpg
netloc attribute on the parse result returns the base URL.We also have access to other attributes like path, query, etc.
# Exclude a portion of the path from the result
If you need to exclude a portion of the path from the result, use the
str.rsplit() or str.split() methods.
from urllib.parse import urlparse my_url = 'https://bobbyhadz.com/images/wallpaper.jpg' parsed = urlparse(my_url) base = parsed.netloc print(base) # 👉️ bobbyhadz.com path = parsed.path print(path) # 👉️ /images/wallpaper.jpg with_path = base + '/'.join(path.rsplit('/', 1)[:-1]) print(with_path) # 👉️ bobbyhadz.com/images print(path.rsplit('/', 1)) # 👉️ ['/images', 'wallpaper.jpg']
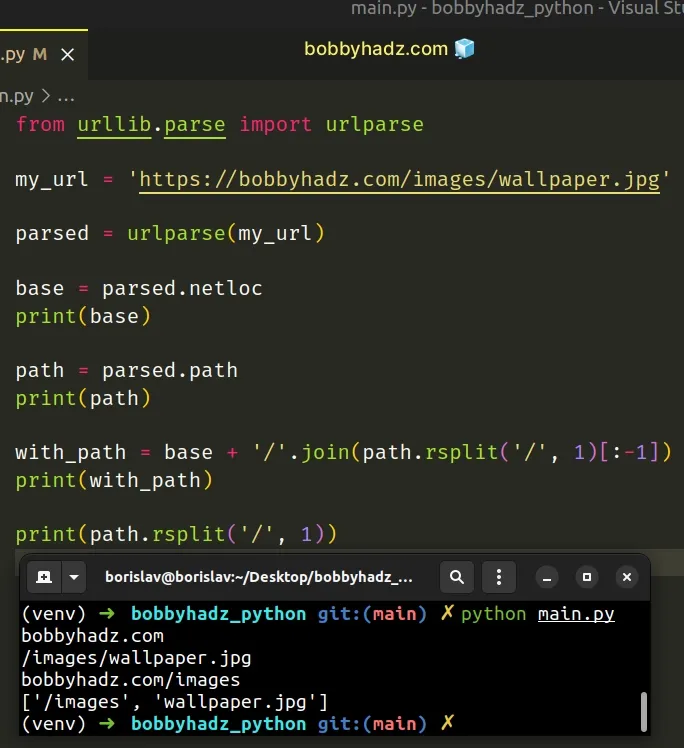
The str.rsplit() method returns a list of the words in the string using the provided separator as the delimiter string.
# 👇️ ['/images', 'wallpaper.jpg'] print('/images/wallpaper.jpg'.rsplit('/', 1)) # 👇️ ['', 'images', 'wallpaper.jpg'] print('/images/wallpaper.jpg'.rsplit('/'))
The method takes the following 2 arguments:
| Name | Description |
|---|---|
| separator | Split the string into substrings on each occurrence of the separator |
| maxsplit | At most maxsplit splits are done, the rightmost ones (optional) |
Except for splitting from the right, rsplit() behaves like split().
maxsplit argument to 1 if you only want to split once from the right.# Working with more deeply nested URL paths
Here is another example with a more deeply nested URL.
from urllib.parse import urlparse my_url = 'https://bobbyhadz.com/images/nature/wallpaper.jpg' parsed = urlparse(my_url) base = parsed.netloc print(base) # 👉️ bobbyhadz.com path = parsed.path print(path) # 👉️ /images/wallpaper.jpg with_path = base + path.rsplit('/', 2)[0] print(with_path) # 👉️ bobbyhadz.com/images print(path.rsplit('/', 2)) # 👉️ ['/images', 'nature', 'wallpaper.jpg']
The URL in the example is one level deeper.
We split the URL 2 times from the right and added the /images path to the base
URL.

