Find all occurrences of a Substring in a String in Python
Last updated: Apr 10, 2024
Reading time·5 min

# Table of Contents
- Find all indexes of a substring using startswith()
- Find all indexes of a substring in a String using re.finditer()
- Find all indexes of a substring in a String using a for loop
- Find all indexes of a substring using a while loop
- Finding only non-overlapping results
# Find all indexes of a substring using startswith()
To find all indexes of a substring in a string:
- Use a list comprehension to iterate over a
rangeobject of the string's length. - Check if each character starts with the given substring and return the result.
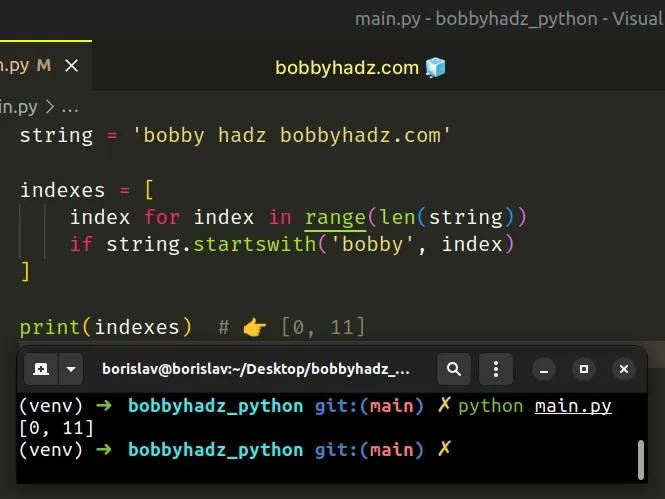
string = 'bobby hadz bobbyhadz.com' indexes = [ index for index in range(len(string)) if string.startswith('bobby', index) ] print(indexes) # 👉️ [0, 11]
We used a range object to iterate over the string.
string = 'bobby hadz bobbyhadz.com' # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, # 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23] print(list(range(len(string))))
The range() class is commonly used for looping a specific number of times in for loops and takes the following arguments:
| Name | Description |
|---|---|
start | An integer representing the start of the range (defaults to 0) |
stop | Go up to, but not including the provided integer |
step | Range will consist of every N numbers from start to stop (defaults to 1) |
If you only pass a single argument to the range() constructor, it is
considered to be the value for the stop parameter.
for n in range(5): print(n) # 👉️ 0 1 2 3 4 result = list(range(5)) # 👇️ [0, 1, 2, 3, 4] print(result)
On each iteration, we check if the slice of the string that starts at the current character starts with the given substring.
string = 'bobby hadz bobbyhadz.com' indexes = [ index for index in range(len(string)) if string.startswith('bobby', index) ] print(indexes) # 👉️ [0, 11]
If the condition is met, the corresponding index is returned.
The new list contains all of the indexes of the substring in the string.
# Find all indexes of a substring in a String using re.finditer()
This is a three-step process:
- Use the
re.finditer()to get an iterator object of the matches. - Use a list comprehension to iterate over the iterator.
- Use the
match.start()method to get the indexes of the substring in the string.
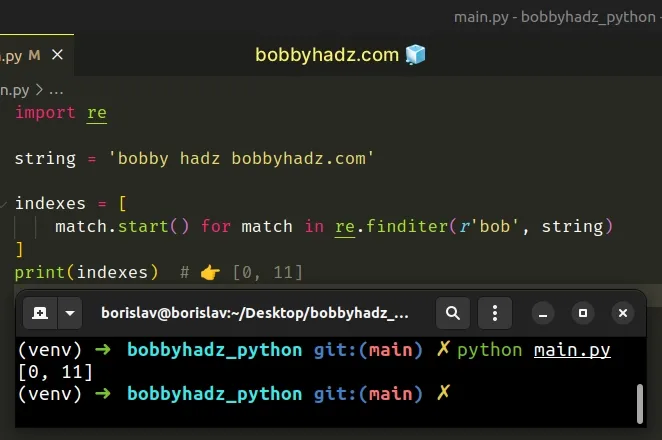
import re string = 'bobby hadz bobbyhadz.com' indexes = [ match.start() for match in re.finditer(r'bob', string) ] print(indexes) # 👉️ [0, 11]
The re.finditer() method takes a regular expression and a string and returns an iterator object containing the matches for the pattern in the string.
import re string = 'bobby hadz bobbyhadz.com' # 👇️ [<re.Match object; span=(0, 3), match='bob'>, # <re.Match object; span=(11, 14), match='bob'>] print(list( re.finditer(r'bob', string) ))
The match.start() method returns the index of the first character of the
match.
import re string = 'bobby hadz bobbyhadz.com' print( list(re.finditer(r'bob', string))[0].start() # 👉️ 0 ) print( list(re.finditer(r'bob', string))[1].start() # 👉️ 11 )
The new list contains the index of all occurrences of the substring in the string.
import re string = 'bobby hadz bobbyhadz.com' indexes = [ match.start() for match in re.finditer(r'bob', string) ] print(indexes) # 👉️ [0, 11]
Alternatively, you can use a for loop.
# Find all indexes of a substring in a String using a for loop
This is a four-step process:
- Declare a new variable that stores an empty list.
- Use the
re.finditer()to get an iterator object of the matches. - Use a
forloop to iterate over the object. - Append the index of each match to the list.
import re string = 'bobby hadz bobbyhadz.com' indexes = [] for match in re.finditer(r'bob', string): indexes.append(match.start()) print(indexes) # 👉️ [0, 11]
We used a for loop to iterate over the iterator object.
On each iteration, we use the match.start() method to get the index of the
current match and append the result to the indexes list.
The list.append() method adds an item to the end of the list.
# Find all indexes of a substring using a while loop
You can also use a while loop to find all indexes of a substring in a string.
def find_indexes(a_string, substring): start = 0 indexes = [] while start < len(a_string): start = a_string.find(substring, start) if start == -1: return indexes indexes.append(start) start += 1 return indexes string = 'bobby hadz bobbyhadz.com' print(find_indexes(string, 'bob')) # 👉️ [0, 11] string = 'bobobobob' print(find_indexes(string, 'bob')) # 👉️ [0, 2, 4, 6]
The find_indexes substring takes a string and a substring and returns a list
containing all of the indexes of the substring in the string.
We used a while loop to iterate for as long as the start variable is less
than the string's length.
On each iteration, we use the str.find() method to find the next index of the
substring in the string.
The str.find method returns the index of the first occurrence of the provided
substring in the string.
The method returns -1 if the substring is not found in the string.
If the substring is not found in the string -1 is returned and we return the
indexes list.
Otherwise, we add the index of the occurrence to the list and increment the
start variable by 1.
Notice that the function in the example finds indexes of overlapping substrings as well.
def find_indexes(a_string, substring): start = 0 indexes = [] while start < len(a_string): start = a_string.find(substring, start) if start == -1: return indexes indexes.append(start) start += 1 return indexes string = 'bobobobob' print(find_indexes(string, 'bob')) # 👉️ [0, 2, 4, 6]
# Finding only non-overlapping results
If you need to only find the indexes of the non-overlapping substrings, add the
length of the substring to the start variable.
def find_indexes(a_string, substring): start = 0 indexes = [] while start < len(a_string): start = a_string.find(substring, start) if start == -1: return indexes indexes.append(start) start += len(substring) # 👈️ only non-overlapping return indexes string = 'bobobobob' print(find_indexes(string, 'bob')) # 👉️ [0, 4]
Instead of adding 1 to the start variable when iterating, we added the
length of the substring to only get the indexes of the non-overlapping matches.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

