UnicodeEncodeError: 'charmap' codec can't encode characters in position
Last updated: Apr 8, 2024
Reading time·3 min

# UnicodeEncodeError: 'charmap' codec can't encode characters in position
The Python "UnicodeEncodeError: 'charmap' codec can't encode characters in position" occurs when we use an incorrect codec to encode a string to bytes.
To solve the error, specify the correct encoding when opening the file or
encoding the string, e.g. utf-8.
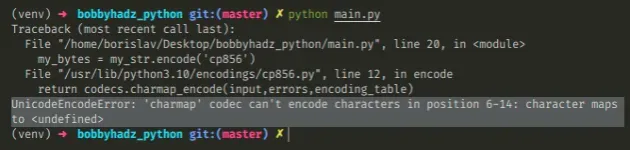
Here is an example of how the error occurs.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # ⛔️ UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-8: character maps to <undefined> my_bytes = my_str.encode('cp856')
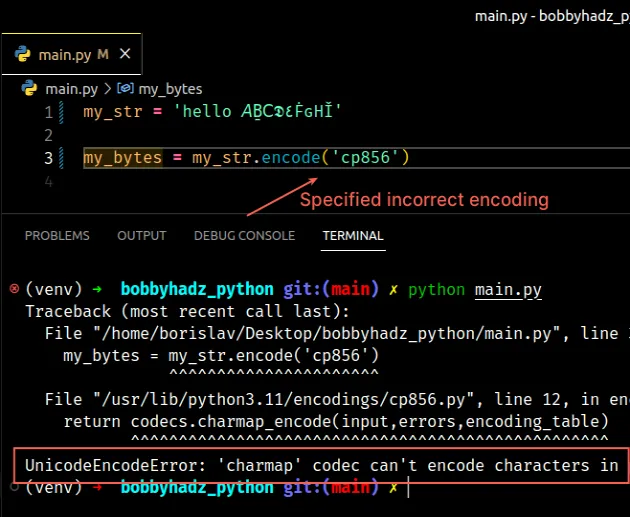
The error is caused because the string cannot be encoded with the specified encoding.
# Use the correct encoding to solve the error
To solve the error, use the correct encoding to encode the string, e.g. utf-8.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_bytes = my_str.encode('utf-8') # 👇️ b'hello \xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_bytes)
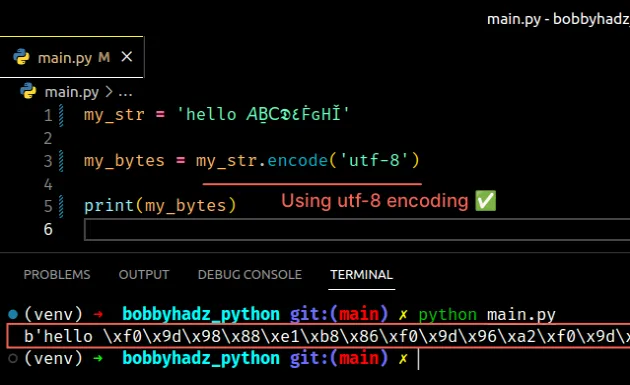
utf-8 encoding is capable of encoding over a million valid character code points in Unicode.You can view all of the standard encodings in this table of the official docs.
# Solving the error when using the BeautifulSoup module
If you use the BeautifulSoup module, set the encoding on the object.
import bs4 as bs import urllib.request source = urllib.request.urlopen('https://example.com').read() soup = bs.BeautifulSoup(source, features="html.parser") # ✅ Set encoding to utf-8 here print(soup.encode("utf-8"))
We used the str.encode() method to
encode the soup string to bytes.
# Set the encoding keyword argument when opening a file
If you get the error when opening a file, set the encoding keyword argument to
utf-8 in the call to the
open() function.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
You can also specify the encoding keyword argument when interacting with CSV files.
import csv # ✅ Specify encoding keyword argument with open('example.csv', 'w', newline='', encoding='utf-8') as csvfile: csv_writer = csv.writer(csvfile, delimiter=',', quoting=csv.QUOTE_MINIMAL) csv_writer.writerow(['Alice', 'Bob', 'Carl'])
The same approach can be used when calling the open() function directly,
without the with statement.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_file = open('example.txt', 'w', encoding='utf-8') my_file.write(my_str) my_file.close()
We explicitly set the encoding keyword argument to utf-8 in the call to the
open() function.
string to a bytes object and decoding is the process of converting a bytes object to a string.Here is what the complete process looks like.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # 👇️ Encode str to bytes my_bytes = my_str.encode('utf-8') print(my_bytes) # 👇️ Decode bytes to str my_str_again = my_bytes.decode('utf-8') print(my_str_again) # 👉️ "hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ"
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
# Set the errors keyword argument to ignore to silence the error
If the error persists when using the utf-8 encoding, try setting the
errors keyword argument
to ignore to ignore characters that cannot be encoded.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' # 👇️ Encode str to bytes my_bytes = my_str.encode('utf-8', errors='ignore') print(my_bytes) # 👇️ Decode bytes to str my_str_again = my_bytes.decode('utf-8', errors='ignore') print(my_str_again) # 👉️ "hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ"
Note that ignoring characters that cannot be encoded can lead to data loss.
You can also set the errors keyword argument to ignore to ignore any
encoding errors when opening a file.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' with open('example.txt', 'w', encoding='utf-8', errors='ignore') as f: f.write(my_str)
The same approach can be used when calling the open() function directly
without the with statement.
my_str = 'hello 𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_file = open('example.txt', 'w', encoding='utf-8', errors='ignore') my_file.write(my_str) my_file.close()
# Setting the encoding globally
If the error persists, try to set the encoding globally by adding the following 3 lines at the top of your file.
import sys sys.stdin.reconfigure(encoding='utf-8') sys.stdout.reconfigure(encoding='utf-8')
If the lines are run before any other code in the file, they override the
encoding used for stdin/stdout/stderr.
Alternatively, you can set the encoding globally with an environment variable.
# on Linux and macOS export PYTHONIOENCODING=utf-8 # on Windows setx PYTHONIOENCODING=utf-8 setx PYTHONLEGACYWINDOWSSTDIO=utf-8
If the
PYTHONIOENCODING
environment variable is set before running the interpreter, it overrides the
encoding used for stdin and stdout.
If you are on Windows, you also have to set the PYTHONLEGACYWINDOWSSTDIO environment variable as shown in the example.
If the variable is set to a non-empty string, Unicode characters are encoded
according to the active console code page and not utf-8.
If the error persists, try setting the PYTHONUTF8 to 1.
# on Linux and macOS export PYTHONUTF8=1 # on Windows setx PYTHONUTF8=1
If the
PYTHONUTF8
variable is set to 1, then
Python UTF-8 mode is
enabled.
# Discussion
When you write a string to a file, Python will try to encode the string according to the specified encoding.
If the string contains characters that are not supported by the specified encoding, the error is raised.
If you don't know what encoding you should specify, your best bet is to try with
utf-8 and see if you get legible results.
Python uses utf-8 as the default encoding on most platforms, so it is one of
the better options.

