TypeError: a bytes-like object is required, not 'str'
Last updated: Apr 8, 2024
Reading time·7 min

# Table of Contents
- TypeError: a bytes-like object is required, not 'str'
- (CSV) TypeError: a bytes-like object is required, not 'str'
- (JSON) TypeError: a bytes-like object is required, not 'str'
- TypeError: a bytes-like object is required, not _io.BytesIO
# TypeError: a bytes-like object is required, not 'str'
To solve the Python "TypeError: a bytes-like object is required, not 'str'",
encode the str to bytes, e.g. my_str.encode('utf-8').
The str.encode method returns an encoded version of the string as a bytes
object. The default encoding is utf-8.
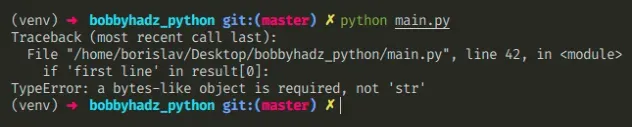
socket module, scroll down to the next section.Here is an example of how the error occurs.
# 👇️ Open the file with open('example.txt', 'rb') as f: result = f.readlines() # ⛔️ TypeError: a bytes-like object is required, not 'str' if 'first line' in result[0]: print('success')
We opened the file in binary mode (using the rb mode), so the result list
contains bytes objects.
# Encode the string into bytes to solve the error
To solve the error, use the
str.encode method to encode the
str into bytes.
with open('example.txt', 'rb') as f: result = f.readlines() # 👇️ Call encode() on the string if 'first line'.encode('utf-8') in result[0]: # ✅ This runs print('success')
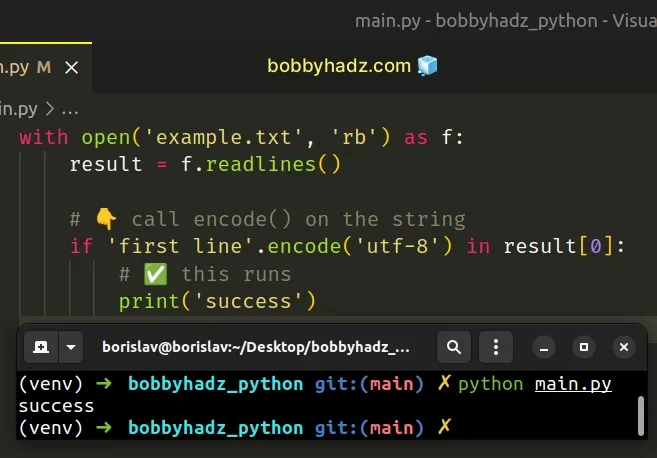
Now the values on both sides of the in operator are bytes objects, so the
error is resolved.
# Decoding the bytes object into a string
Note that we could have also decoded the bytes object into a string.
with open('example.txt', 'rb') as f: result = f.readlines() # ✅ Decode the bytes into str if 'first line' in result[0].decode('utf-8'): print('success')
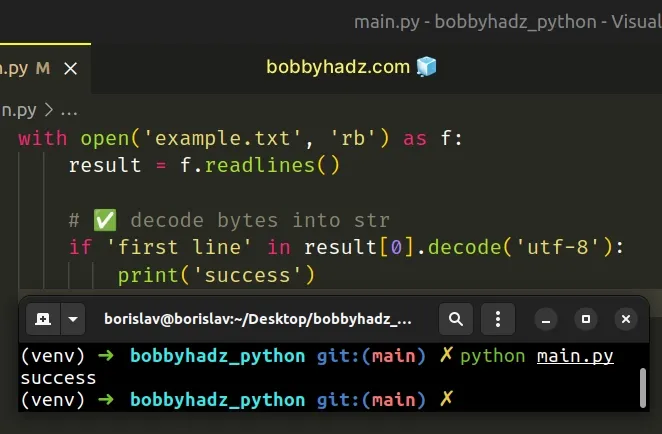
The values on the left and right-hand side of the in operator are of the same
type (str).
The bytes.decode() method returns a
string decoded from the given bytes. The default encoding is utf-8.
You can also use a list comprehension to perform the operation on each element in a list.
with open('example.txt', 'rb') as f: lines = [l.decode('utf-8') for l in f.readlines()] if 'first line' in lines[0]: print('success')
The example shows how to decode each bytes object in the list to a string.
# Solve the error when using the socket module
The error is also caused when sending data to a socket with the socket module.
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(('example.com', 80)) # ⛔️ TypeError: a bytes-like object is required, not 'str' s.send('GET https://example.com/example.txt HTTP/1.0\n\n') while True: data = s.recv(1024) if not data: break print(data) s.close()
One way to solve the error is to encode the str to a bytes object by using
the encode() method.
You should also make sure to use the
sendall()
method instead of
send(),
because sendall() continues to send data from bytes until either all data has
been sent or an error occurs.
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(('example.com', 80)) # ✅ Call .encode('utf-8') on the string 👇️ s.sendall( 'GET https://example.com/example.txt HTTP/1.0\n\n'.encode('utf-8') ) while True: data = s.recv(1024) if not data: break print(data) s.close()
encode method to encode the string into bytes, which solves the error.If you have a string literal, you can simply prefix it with b which achieves
the same result.
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(('example.com', 80)) # ✅ Prefix string literal with b'' s.sendall(b'GET https://example.com/example.txt HTTP/1.0\n\n') while True: data = s.recv(1024) if not data: break print(data) s.close()
.encode('utf-8') method instead.The str.encode() method returns an
encoded version of the string as a bytes object. The default encoding is
utf-8.
# Table of Contents
- (CSV) TypeError: a bytes-like object is required, not 'str'
- (JSON) TypeError: a bytes-like object is required, not 'str'
- TypeError: a bytes-like object is required, not _io.BytesIO
# (CSV) TypeError: a bytes-like object is required, not 'str'
To solve the Python CSV "TypeError: a bytes-like object is required, not
'str'", make sure to open the CSV file in w mode and not wb and use the
io.StringIO class instead of io.BytesIO if working with streams.
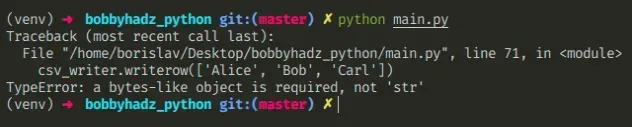
Here is an example of how the error occurs.
import csv # 👇️ Note: file is open in wb mode with open('example.csv', 'wb') as csvfile: csv_writer = csv.writer(csvfile, delimiter=',', quoting=csv.QUOTE_MINIMAL) # ⛔️ TypeError: a bytes-like object is required, not 'str' csv_writer.writerow(['Alice', 'Bob', 'Carl'])
We opened the file in wb (binary) mode rather than w (text) mode which
caused the error.
# Use the w mode when writing to a CSV file
To solve the error, use the w mode when writing to a CSV file.
import csv # ✅ Make sure to set the mode to `w` and set newline kwarg with open('example.csv', 'w', newline='') as csvfile: csv_writer = csv.writer(csvfile, delimiter=',', quoting=csv.QUOTE_MINIMAL) csv_writer.writerow(['Alice', 'Bob', 'Carl'])
w (text) and set the newline keyword argument to an empty string, which is mandatory when working with CSV files in Python 3.If newline='' is not specified, newlines embedded inside quoted fields are not
interpreted correctly.
For example, on platforms that use \r\n line endings on write, an extra \r
will be added unless newline='' is specified.
If you are writing to an io.BytesIO object, use the
io.StringIO class
instead as the CSV writer only handles strings.
# Table of Contents
- (JSON) TypeError: a bytes-like object is required, not 'str'
- TypeError: a bytes-like object is required, not _io.BytesIO
# (JSON) TypeError: a bytes-like object is required, not 'str'
To solve the Python JSON "TypeError: a bytes-like object is required, not
'str'", make sure to open the JSON file in w mode and not wb mode when
writing strings to a file.

Here is an example of how the error occurs.
import json my_json = json.dumps({'name': 'Alice', 'age': 30}) file_name = 'example.json' # 👇️ Opened the file in wb mode with open(file_name, 'wb') as f: # ⛔️ TypeError: a bytes-like object is required, not 'str' f.write(my_json)
We opened the file in wb (binary) mode rather than w (text) mode which
caused the error.
# Use the w mode when writing to a JSON file
To solve the error, use the w mode when writing to a JSON file.
import json my_json = json.dumps({'name': 'Alice', 'age': 30}) file_name = 'example.json' # ✅ opened file in w mode and set encoding to utf-8 with open(file_name, 'w', encoding='utf-8') as f: f.write(my_json)
We opened the JSON file in w (text) mode.
When a file is opened in text mode, we read and write strings from and to the file.
Those strings are encoded using a specific encoding (utf-8 in the example).
encoding keyword argument, the default is platform-dependent.If you want to both read from and write to the file, use the r+ mode when
opening it.
b to the mode (like in the first code snippet), the file is opened in binary mode.Note that you cannot specify encoding when opening a file in binary mode.
When a file is opened in binary mode, data is read and written as bytes
objects.
This means that you could encode your JSON string to a bytes object using the
encode() method if you have the wb mode set.
import json my_json = json.dumps({'name': 'Alice', 'age': 30}) file_name = 'example.json' with open(file_name, 'wb') as f: f.write(my_json.encode('utf-8'))
The str.encode() method returns an
encoded version of the string as a bytes object. The default encoding is
utf-8.
However, it is much simpler to open the JSON file in w (or another text) mode,
so you can write strings directly.
# TypeError: a bytes-like object is required, not _io.BytesIO
To solve the Python "TypeError: a bytes-like object is required, not
_io.BytesIO", call the read() method on the _io.BytesIO object, e.g.
b.read().
The read method reads the bytes from the object and returns them.
Here is an example of how the error occurs.
import io b = io.BytesIO(b"abcd") print(type(b)) # <class '_io.BytesIO'> with open('example.zip', 'wb') as f: # ⛔️ TypeError: a bytes-like object is required, not '_io.BytesIO' f.write(b)
We tried using an _io.BytesIO object where a bytes object is expected.
To solve the error, call the read() method on the _io.BytesIO object.
import io b = io.BytesIO(b"abcd") print(type(b)) # <class '_io.BytesIO'> with open('example.zip', 'wb') as f: # 👇️ Change the stream position to the start b.seek(0) # 👇️ Read the bytes from the object f.write(b.read())
We used the
seek() method to
change the stream position to an offset of 0 (to the beginning).
This means that we will start reading the stream from the start.
The read() method can be used to read the bytes from an object and return them.
The method takes an optional size argument if you want to specify up to how
many bytes to return.
If the argument is not provided, all bytes until the end of the file are returned.
seek() method with a position of 0 is important because if you use the `read` method somewhere else in your code, you would change the offset.Here is an example that demonstrates this - once we call the read() method,
the stream is positioned at the end, so it doesn't return anything.
import io b = io.BytesIO(b"abcd") with open('example.zip', 'wb') as f: # 👇️ Change the stream position to the start b.seek(0) print(b.read()) # 👉️ b'abcd' print(b.read()) # 👉️ b''
You can use the seek(0) method to reset the stream position.
import io b = io.BytesIO(b"abcd") with open('example.zip', 'wb') as f: # 👇️ Change the stream position to the start b.seek(0) print(b.read()) # 👉️ b'abcd' # 👇️ Change the stream position to the start b.seek(0) print(b.read()) # 👉️ b'abcd'

