NameError: name 'unicode' is not defined in Python [Solved]
Last updated: Apr 8, 2024
Reading time·2 min

# NameError: name 'unicode' is not defined in Python
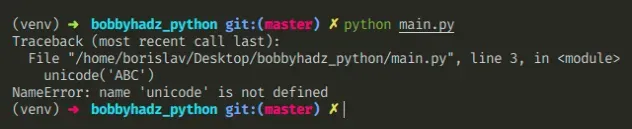
The Python "NameError name 'unicode' is not defined" occurs when using the
unicode object in Python 3.
To solve the error, replace all calls to unicode() with str() because
unicode was renamed to str in Python 3.
result = str('ABC') print(result) # 👉️ 'ABC'
Make sure to replace all occurrences of unicode with str in your code.
# Declaring a unicode variable in your code
Alternatively, you can declare a unicode variable and set its value to the
str class.
import sys if sys.version_info[0] >= 3: unicode = str print(unicode('ABC')) # 👉️ "ABC"
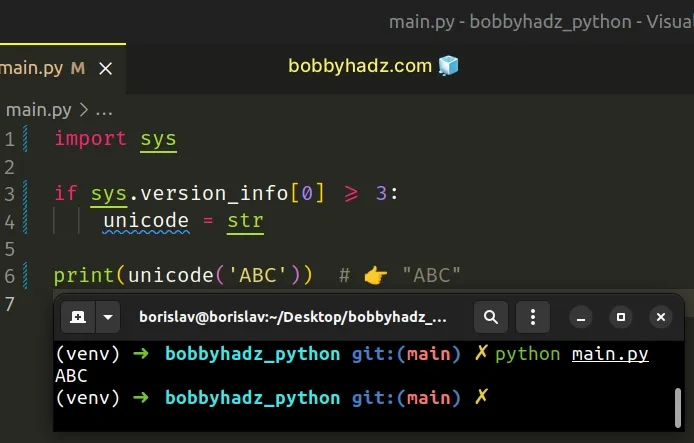
Our if statement checks if the version of the Python interpreter is greater or
equal to 3, and if it is, we set the unicode variable to the str class.
All text in Python is Unicode, however, encoded Unicode is represented as binary data.
# Use the str type to store text in Python 3
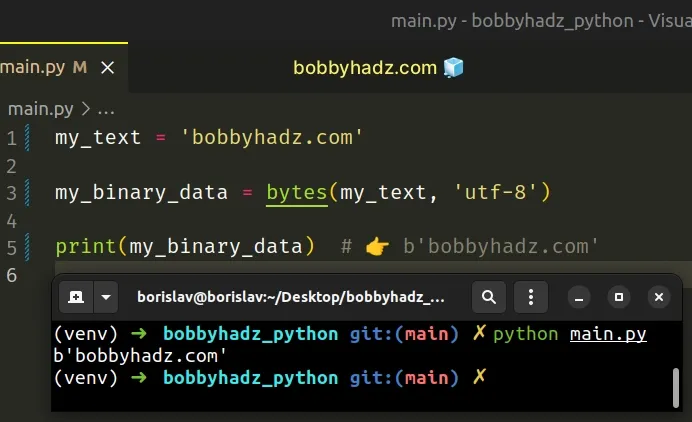
You can use the str type to store text and the bytes type to store binary
data.
my_text = 'bobbyhadz.com' my_binary_data = bytes(my_text, 'utf-8') print(my_binary_data) # 👉️ b'bobbyhadz.com'
In Python 3 you can no longer use u'...' literals for Unicode text because all
strings are now Unicode.
However, you must use b'...' literals for binary data.
# Converting a string to bytes and vice versa
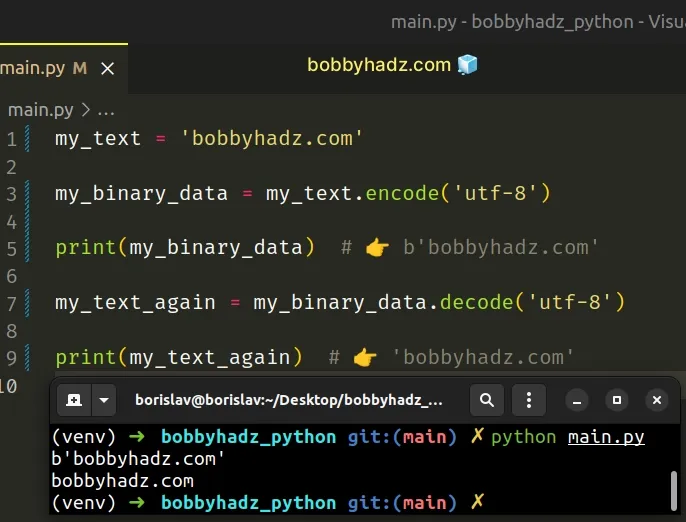
You can use str.encode() to go from str to bytes and bytes.decode() to
go from bytes to str.
my_text = 'bobbyhadz.com' my_binary_data = my_text.encode('utf-8') print(my_binary_data) # 👉️ b'bobbyhadz.com' my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ 'bobbyhadz.com'
The str.encode() method is the
opposite of bytes.decode() and returns a bytes representation of the Unicode
string, encoded in the requested encoding.
You can also use bytes(s, encoding=...) and str(b, encoding=...).
my_text = 'bobbyhadz.com' my_binary_data = bytes(my_text, encoding='utf-8') print(my_binary_data) # 👉️ b'bobbyhadz.com' my_text_again = str(my_binary_data, encoding='utf-8') print(my_text_again) # 👉️ 'bobbyhadz.com'
The str class returns a string version of the given object. If an object is not provided, the class returns an empty string.
The syntax for using the
bytes class is the
same, except that a b prefix is added.

