Convert Letters to Numbers and vice versa in Python
Last updated: Apr 10, 2024
Reading time·5 min

# Table of Contents
- Convert letters to numbers in Python
- Convert numbers to letters in Python
- Convert all letters in a string to numbers
# Convert letters to numbers in Python
Use the ord() function to convert a letter to a number, e.g.
number = ord('a').
The ord() function takes a string that represents 1 Unicode character and
returns an integer representing the Unicode code point of the given character.
number = ord('a') print(number) # 👉️ 97 one_based = ord('a') - 96 print(one_based) # 👉️ 1 # ------------------------------------ number = ord('A') print(number) # 👉️ 65 one_based = ord('A') - 64 print(one_based) # 👉️ 1
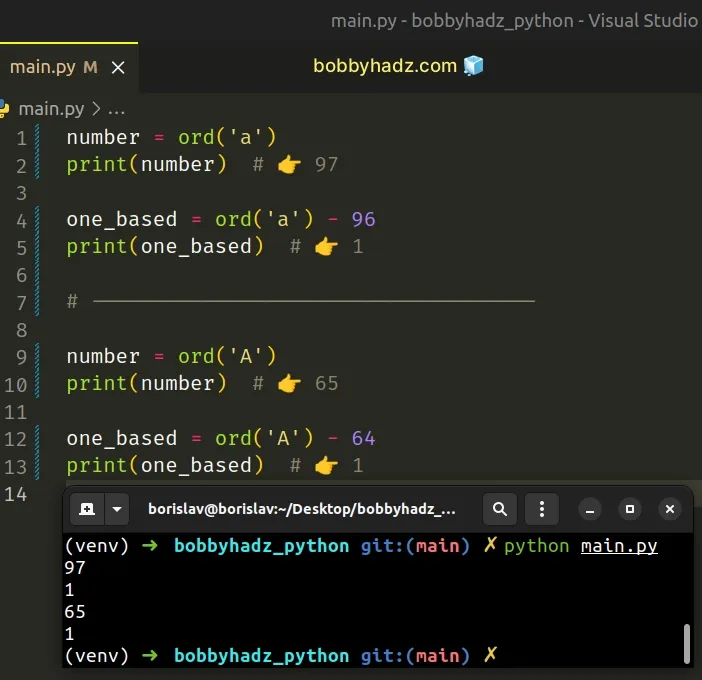
If you need to convert an integer to its letter equivalent, click on the following subheading:
The ord() function takes a string that represents 1 Unicode character and returns an integer representing the Unicode code point of the given character.
print(ord('a')) # 👉️ 97 print(ord('b')) # 👉️ 98
If you need to get a one-based result instead of the Unicode code point of the
character, subtract 96 for lowercase characters or 64 for uppercase
characters.
number = ord('a') print(number) # 👉️ 97 one_based = ord('a') - 96 print(one_based) # 👉️ 1 # ------------------------------------ number = ord('A') print(number) # 👉️ 65 one_based = ord('A') - 64 print(one_based) # 👉️ 1
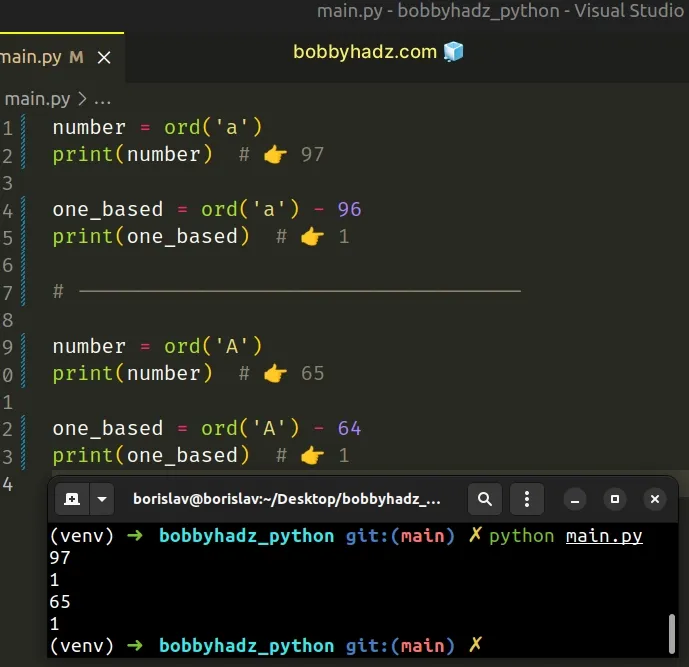
The lowercase letter a has a Unicode code point of 97, so subtracting 96 gives
us a value of 1.
The chr function is the
inverse of ord().
print(chr(97)) # 👉️ 'a' print(chr(98)) # 👉️ 'b'
It takes an integer that represents a Unicode code point and returns the corresponding character.
# Convert numbers to letters in Python
Use the chr() function to convert a number to a letter, e.g.
letter = chr(97).
The chr() function takes an integer that represents a Unicode code point and
returns the corresponding character.
# ✅ convert number to letter (standard) letter = chr(97) print(letter) # 👉️ 'a' letter = chr(65) print(letter) # 👉️ 'A' # -------------------------- # ✅ convert number to letter (starting at 1) letter = chr(ord('`') + 1) print(letter) # 👉️ 'a' letter = chr(ord('@') + 1) print(letter) # 👉️ 'A'
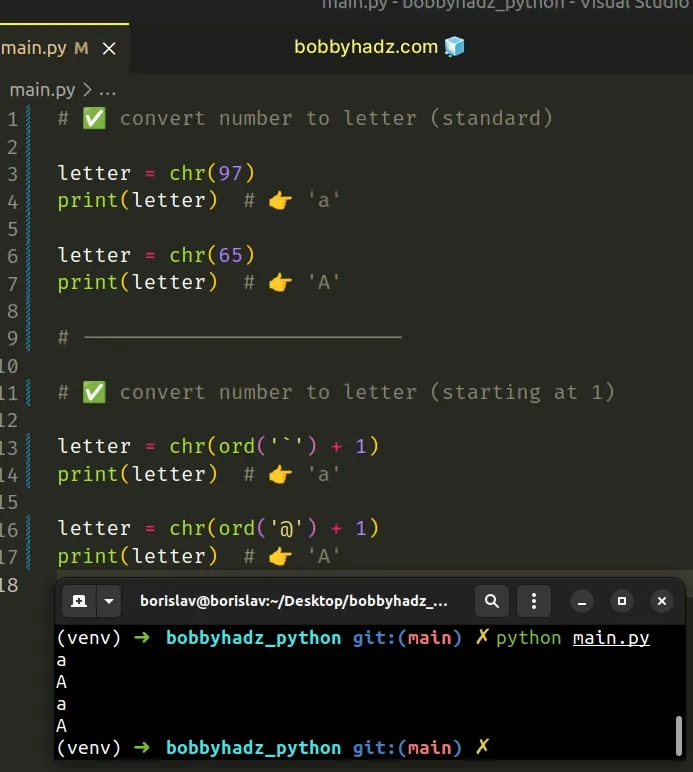
The chr() function takes an integer that represents a Unicode code point and returns the corresponding character.
For example, lowercase a has a Unicode code point of 97 and uppercase A
has a Unicode code point of 65.
letter = chr(97) print(letter) # 👉️ 'a' print(chr(98)) # 👉️ 'b' letter = chr(65) print(letter) # 👉️ 'A' print(chr(66)) # 👉️ 'B'
If you need to convert the number 1 to lowercase or uppercase a, use the
ord() function in conjunction with chr().
letter = chr(ord('`') + 1) print(letter) # 👉️ 'a' letter = chr(ord('@') + 1) print(letter) # 👉️ 'A' print(ord('`')) # 👉️ 96 print(ord('@')) # 👉️ 64
The ord function takes a string that represents 1 Unicode character and returns an integer representing the Unicode code point of the given character.
print(ord('a')) # 👉️ 97 print(ord('b')) # 👉️ 98
We used the ord() function to get the Unicode code point of the tilde
character because it is the last character before the lowercase letter a and
added 1 to the result.
letter = chr(ord('`') + 1) print(letter) # 👉️ 'a' letter = chr(ord('@') + 1) print(letter) # 👉️ 'A' print(ord('`')) # 👉️ 96 print(ord('@')) # 👉️ 64
The @ symbol is the last character before the capital letter A, so adding
1 to the result and calling the chr() function gets us the capital letter
A.
You can use a list comprehension if you need to get a list of some or all of the letters in the alphabet.
list_of_lowercase_letters = [ chr(i) for i in range(ord('a'), ord('z') + 1) ] # 👇️ ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] print(list_of_lowercase_letters) list_of_uppercase_letters = [ chr(i) for i in range(ord('A'), ord('Z') + 1) ] # 👇️ ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] print(list_of_uppercase_letters)
We used the range() class to get a range that we can iterate over and used a
list comprehension to iterate over the range.
You can use list slicing if you need to get a slice of the list of letters.
letters = [ chr(i) for i in range(ord('a'), ord('z') + 1) ] # 👇️ ['a', 'b', 'c', 'd', 'e', 'f'] print(letters[:letters.index('f') + 1])
The syntax for list slicing is my_list[start:stop:step].
The start index is inclusive and the stop index is exclusive (up to, but not
including).
Python indexes are zero-based, so the first item in a list has an index of 0,
and the last item has an index of -1 or len(my_list) - 1.
We didn't specify a start index, so the list slice starts at index 0.
# Convert all letters in a string to numbers
To convert all of the letters in a string to numbers:
- Use a list comprehension to iterate over the string.
- Use the
ord()function to get the Unicode code point of each character. - The new list will contain the corresponding numbers.
my_str = 'bobbyhadz' numbers = [ ord(char) - 96 for char in my_str.lower() ] print(numbers) # 👉️ [2, 15, 2, 2, 25, 8, 1, 4, 26]
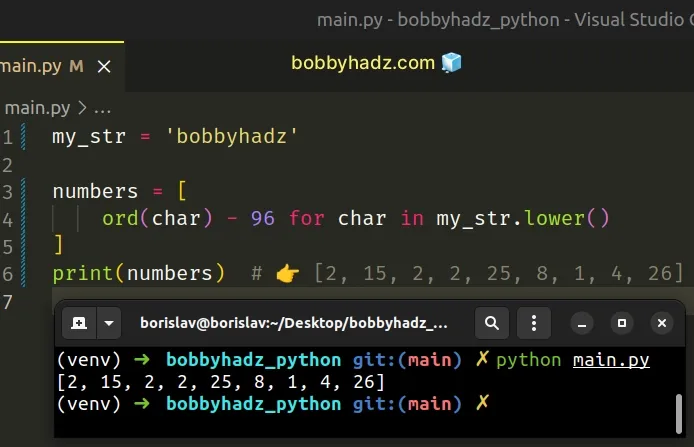
We used a list comprehension to iterate over the lowercase version of the string.
On each iteration, we use the ord() function to get the Unicode code point of
the current letter and subtract 96 to get a one-based result.
If you need to get a list containing the Unicode code points of each character
in the string, don't subtract 96 from each call to ord().
my_str = 'bobbyhadz' numbers = [ ord(char) for char in my_str.lower() ] print(numbers) # 👉️ [98, 111, 98, 98, 121, 104, 97, 100, 122]
The new list contains the Unicode code points of the characters in the string.
Alternatively, you can use a for loop.
# Convert all letters in a string to numbers using for loop
This is a three-step process:
- Use a
forloop to iterate over the string. - Use the
ord()function to get the Unicode code point of each character. - Append the results to a new list.
my_str = 'bobbyhadz' numbers = [] for char in my_str.lower(): numbers.append( ord(char) - 96 ) print(numbers) # 👉️ [2, 15, 2, 2, 25, 8, 1, 4, 26]
We used a for loop to iterate over the lowercase version of the string.
On each iteration, we use the ord() function to get the number that
corresponds to the current letter and append the result to a list.
The list.append() method adds an item to the end of the list.
my_list = ['bobby', 'hadz'] my_list.append('com') print(my_list) # 👉️ ['bobby', 'hadz', 'com']
The method returns None as it mutates the original list.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
- Convert a comma-separated String to a Dictionary in Python
- Convert a comma-separated String to a List in Python
- Convert multiline String to a Single Line in Python
- Convert string representation of List to List in Python
- Convert a string to a Class object in Python
- Python: Convert string with comma separator and dot to float

