bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml
Last updated: Apr 11, 2024
Reading time·4 min

# Table of Contents
- bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml
- Using the
lxmlparser for speed - Using the
html5libparser to solve the error
# bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml
The BeautifulSoup error "bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?" occurs when you try to use a parser library without installing it first.
You can solve the error by using the built-in html.parser parser.
Here is an example of how the error occurs.
from bs4 import BeautifulSoup markup = """<html><head><title>Example html doc</title></head> <body> <p class="title"><b>bobbyhadz.com</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # ⛔️ bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library? soup = BeautifulSoup(markup, "lxml")
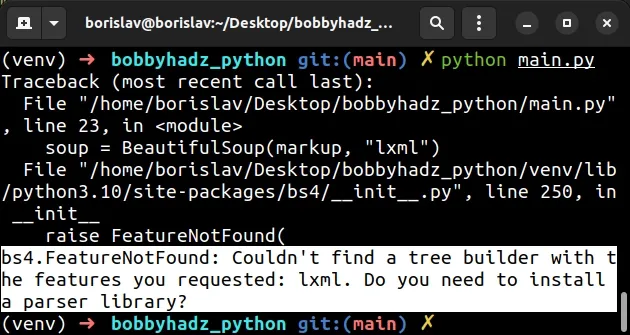
The first argument we passed to the BeautifulSoup class is the markup string
and the second is the parser.
We used the lxml parser, however, we haven't installed the module.
One way to solve the error is to use the built-in html.parser parser.
from bs4 import BeautifulSoup markup = """<html><head><title>Example html doc</title></head> <body> <p class="title"><b>bobbyhadz.com</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(markup, "html.parser") print(soup.title) # 👉️ <title>Example html doc</title> print('-' * 50) print(soup.title.name) # 👉️ title print('-' * 50) print(soup.p) # 👉️ <p class="title"><b>bobbyhadz.com</b></p> print('-' * 50) print(soup.find_all('a'))
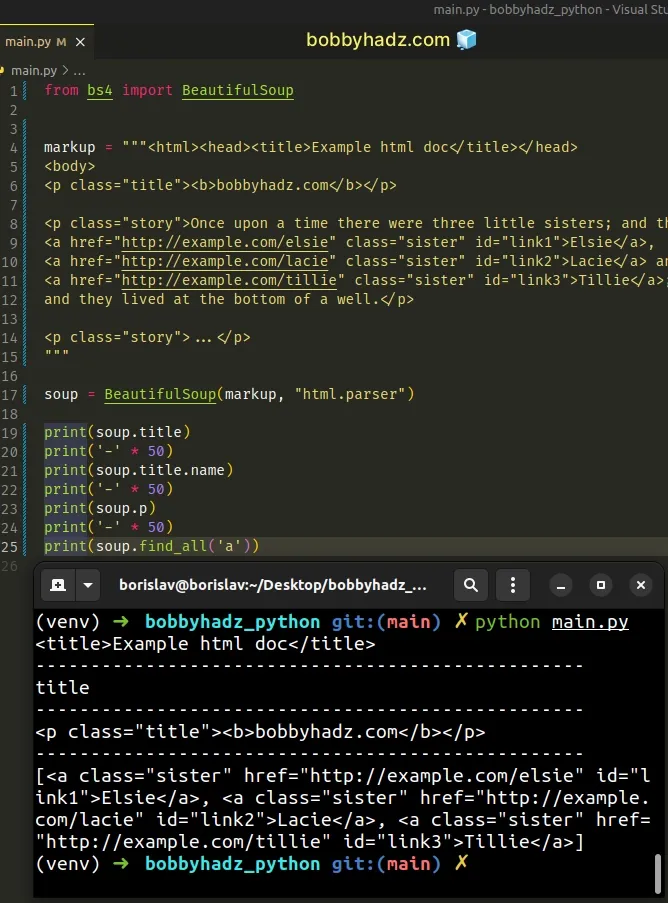
We set the parser to html.parser - BeautifulSoup(markup, "html.parser").
The advantages of using the html.parser parser are:
- It is built-in (no installation required).
- It has a decent parsing speed.
- It is lenient.
The disadvantages of the html.parser parser are:
- It is not as fast as the
lxmlparser. - It is not as lenient as the
html5libparser.
Make sure you have the beautifulsoup4 module installed to be able to run the code sample.
You can click on the link and follow the instructions.
Depending on your environment, you might have to install:
# Using the lxml parser for speed
If you need to optimize for speed, you can use the lxml parser.
Open your terminal and run the following command.
pip install lxml pip3 install lxml
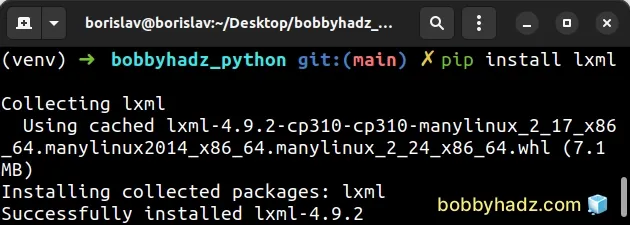
Alternatively, you can follow the installation instructions in the following article.
You can use the lxml parser as follows.
from bs4 import BeautifulSoup markup = """<html><head><title>Example html doc</title></head> <body> <p class="title"><b>bobbyhadz.com</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(markup, "lxml") print(soup.title) print('-' * 50) print(soup.title.name) print('-' * 50) print(soup.p) print('-' * 50) print(soup.find_all('a'))
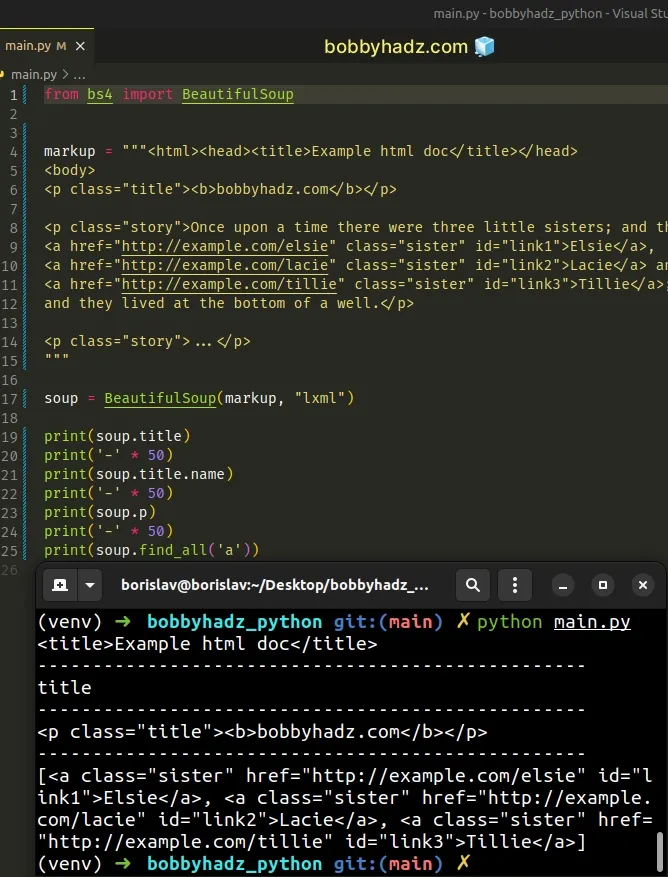
Notice that we passed the string "lxml" as the second argument to the
BeautifulSoup class.
The lxml parser has the following advantages:
- It is fast.
- It is lenient.
However, the lxml parser is an external C dependency and has to be installed
separately.
# Using the html5lib parser to solve the error
Alternatively, you can use the html5lib parser to solve the error.
Open your terminal in your project's root directory and install the html5lib
module.
pip install html5lib # Or with pip3 pip3 install html5lib
Now use the parser as follows.
from bs4 import BeautifulSoup markup = """<html><head><title>Example html doc</title></head> <body> <p class="title"><b>bobbyhadz.com</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(markup, "html5lib") print(soup.title) print('-' * 50) print(soup.title.name) print('-' * 50) print(soup.p) print('-' * 50) print(soup.find_all('a'))
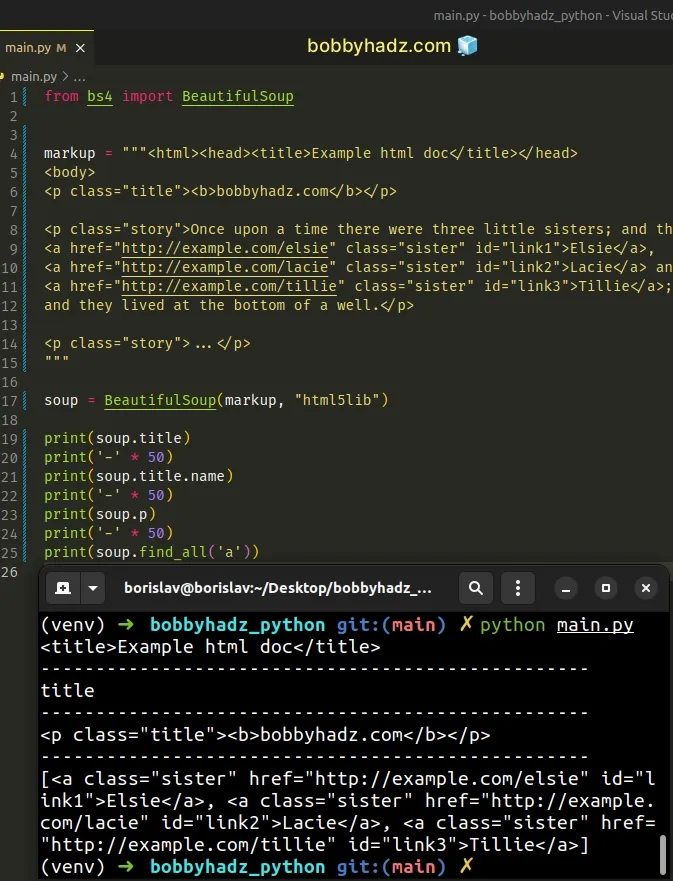
We passed the "html5lib" string as the second argument to the BeautifulSoup
class.
The html5lib parser has the following advantages:
- It is very lenient.
- It parses pages the same way a web browser does.
- It creates valid HTML5.
The html5lib has the following disadvantages:
- It is very slow.
- It is an external Python dependency and has to be installed separately.
If you forget to install the html5lib parser, you will get the following
error:
- bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: html5lib. Do you need to install a parser library?
In general, you will want to optimize for speed and thus use the lxml parser.
If you don't want to install an external dependency, use the built-in
html.parser.
Note that the lxml parser is used for parsing HTML.
If you need to parse XML, you have to set the parser to xml or lxml-xml.
from bs4 import BeautifulSoup markup = """<html><head><title>Example html doc</title></head> <body> <p class="title"><b>bobbyhadz.com</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(markup, 'xml') print(soup.title) print('-' * 50) print(soup.title.name) print('-' * 50) print(soup.p) print('-' * 50) print(soup.find_all('a'))
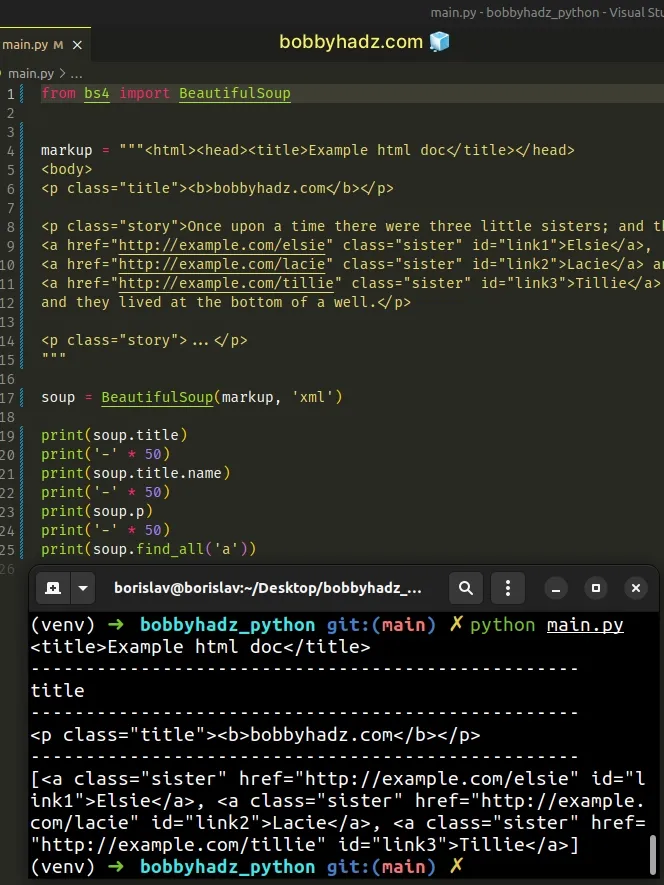
The xml parser has the following advantages:
- It is very fast.
- It is the only parser that supports XML.
However, the xml parser is an external C dependency.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

