Excel file format cannot be determined, you must specify an engine manually
Last updated: Apr 10, 2024
Reading time·3 min

# Excel file format cannot be determined, you must specify an engine manually
The "ValueError: Excel file format cannot be determined, you must specify an engine manually" error occurs for multiple reasons:
- Your operating system creates temporary lock files named
~$file_name.xlsx. - You tried to use the
pd.read_excel()method to read acsvfile or thepd.read_csv()method to read anxlsxfile. - Your files have mislabeled extensions.
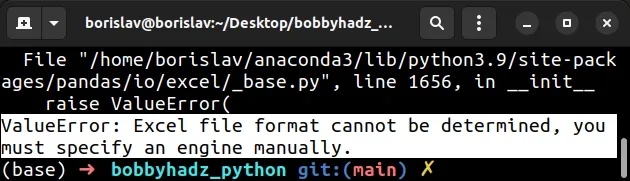
File "/home/borislav/anaconda3/lib/python3.9/site-packages/pandas/io/excel/_base.py", line 1656, in __init__ raise ValueError( ValueError: Excel file format cannot be determined, you must specify an engine manually.
# Your operating system creating temporary lock files
The most common cause of the error is that your operating system creates
temporary lock files named ~$your_file_name.xlsx.
If you have the Excel files open in an application, close the application and adjust your code to ignore these files.
import glob import pandas as pd for file in glob.glob('./*.xlsx'): if '~$' in file: continue else: df = pd.read_excel( file, engine='openpyxl' ) print(df)
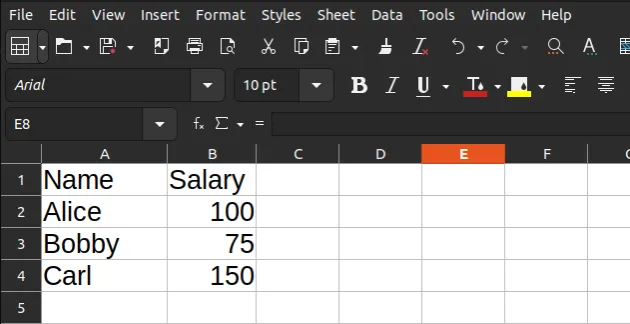
The code sample assumes that you have an xlsx file located in the same
directory as your Python script, e.g. example.xlsx.
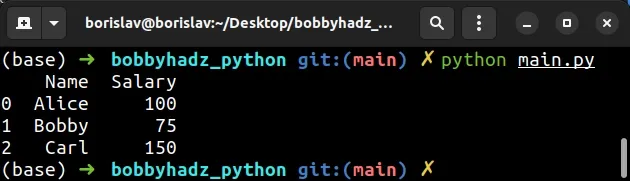
Here is the output of running the python main.py command.
We used the in operator to ignore files that contain ~$ and read the other
files with the xlsx extension.
# Make sure you have the openpyxl module installed
In order to read .xlsx files, you have to set the engine to
openpyxl, so make sure you have the module
installed.
pip install openpyxl pandas pip3 install openpyxl pandas python -m pip install openpyxl pandas python3 -m pip install openpyxl pandas py -m pip install openpyxl pandas # 👇️ For Jupyter Notebook !pip install openpyxl pandas
The openpyxl library is used to read and write Excel 2010 xlsx, xlsm,
xltx, xltm files.
# Using pandas.read_excel vs pandas.read_csv
Another common cause of the error is trying to read a .csv file using the
pandas.read_excel
method.
You should use the
pandas.read_csv method
when reading .csv files and the pandas.read_excel method when reading
.xlsx and .xls files.
If you try to read a .csv file with the pandas.read_excel() method, the
error is raised.
Similarly, if you try to read a .xlsx or .xls file with the
pandas.read_csv method, the error is raised.
# Checking for a file's extension before reading it
Here is an example of how to check for a file's extension before reading it.
import pandas as pd file_name = 'example.xlsx' if file_name.endswith('.xlsx'): df = pd.read_excel( file_name, engine='openpyxl' ) print(df) elif file_name.endswith('.xls'): df = pd.read_excel( file_name, engine='xlrd' ) print(df) elif file_name.endswith('.csv'): df = pd.read_csv(file_name) print(df)
The file in the example has a .xlsx extension, so the openpyxl engine is
used.
.xlsx extension, we use the pandas.read_excel method and set the engine to openpyxl.If the file has a .xls extension, we use the pandas.read_excel method and
set the engine to xlrd.
If the file has a .csv extension, we use the pandas.read_csv method.
# Make sure you have the xlrd module installed
Make sure to install the xlrd module if you don't have it installed.
pip install xlrd pip3 install xlrd python -m pip install xlrd python3 -m pip install xlrd py -m pip install xlrd # 👇️ For Jupyter Notebook !pip install xlrd
The xlrd module is used for reading and
formatting data from Excel files in the historical .xls format.
# Mislabeling the file's extension
Another common cause of the error is mislabeling the file's extension.
Make sure you haven't set a .xls extension to a .csv file and vice versa.
# Conclusion
To solve the "ValueError: Excel file format cannot be determined, you must specify an engine manually" error, make sure:
- To ignore all temporary files that start with
~$, e.g.~$file_name.xlsx. - To use the correct
pandasmethod when reading.xlsxand.csvfiles. - You haven't mislabeled the extension of the file.

