Get Element by XPath using JavaScript - Examples
Last updated: Mar 5, 2024
Reading time·2 min

# Get Element by XPath using JavaScript - Examples
Use the document.evaluate() method to get an element by XPath. The method
returns an XPathResult based on the provided XPath expression and the supplied
parameters.
Here is the HTML for the examples.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>bobbyhadz.com</title> </head> <body> <div> <p>Hello world</p> </div> <div> <p>Apple, Banana, Kiwi</p> </div> <script src="index.js"></script> </body> </html>
And here is the related JavaScript.
// ✅ Get a specific `p` element const firstP = document.evaluate( '/html/body/div[2]/p', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null, ).singleNodeValue; console.log(firstP); // 👉️ p console.log(firstP.textContent); // 👉️ "Apple, Banana, Kiwi" // ----------------------- // ✅ Get all P elements const allParagraphs = document.evaluate( '/html/body//p', document, null, XPathResult.ANY_TYPE, null, ); console.log(allParagraphs); let currentParagraph = allParagraphs.iterateNext(); while (currentParagraph) { console.log(currentParagraph.textContent); currentParagraph = allParagraphs.iterateNext(); }
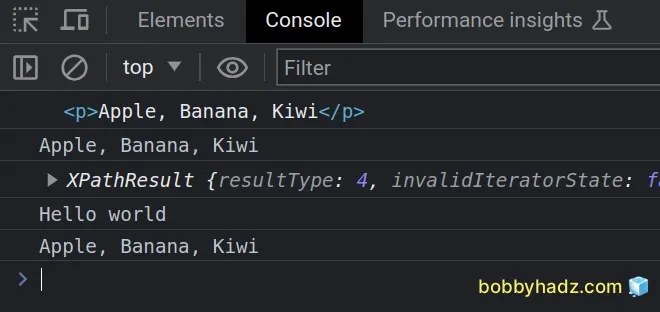
We used the
document.evaluate()
method to get an XPathResult based on an XPath expression.
The first example shows how to get a single node, whereas the second gets a collection of nodes and iterates over it.
The document.evaluate method takes the following parameters:
xpathExpression- the XPath to be evaluatedcontextNode- the context node for the query (usually document)namespaceResolver- should benullwhen working with HTML documentsresultType- the type of XPathResult to return.result- should benull
Notice that in the first example, we accessed the singleNodeValue property on
the XPathResult object.
// ✅ Get a specific `p` element const firstP = document.evaluate( '/html/body/div[2]/p', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null, ).singleNodeValue; console.log(firstP); // 👉️ p console.log(firstP.textContent); // 👉️ "Apple, Banana, Kiwi"
singleNodeValue property returns the first found node that matched the XPath expression.This will evaluate to null if the node set is empty.
Another thing to note in the example is that we specified a result type of
XPathResult.FIRST_ORDERED_NODE_TYPE.
If you look at the XPath Result types table, this result type returns any single node that matches the provided XPath expression.
p elements in the document and iterated over the results.// ✅ Get all P elements const allParagraphs = document.evaluate( '/html/body//p', document, null, XPathResult.ANY_TYPE, null, ); let currentParagraph = allParagraphs.iterateNext(); while (currentParagraph) { // 👇️ "Hello world", "Apple, Banana, Kiwi" console.log(currentParagraph.textContent); currentParagraph = allParagraphs.iterateNext(); }
This time we set XPAthResult.ANY_TYPE as the result type, which returns
whatever type results from the provided XPath expression.
The returned XPathResult object is a Node-set of matches nodes that behave as
an iterator.
We are able to access the individual nodes by using the iterateNext() method
of the XPathResult object.
Once we have iterated over all of the nodes, the iterateNext() method will
return null.
Note that modifying a node will invalidate the iterator. After modifying a node, attempting to iterate over the results generates an error.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

