Python InvalidURL: URL can't contain control characters
Last updated: Apr 10, 2024
Reading time·3 min

# Python InvalidURL: URL can't contain control characters
The Python urllib error "http.client.InvalidURL: URL can't contain control characters." occurs when the URL to which you're making a request contains spaces.
To solve the error, replace the spaces with %20 or simply remove them.
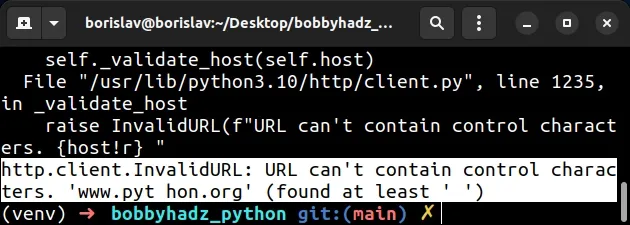
Here is the complete stack trace.
File "/usr/lib/python3.10/http/client.py", line 1235, in _validate_host raise InvalidURL(f"URL can't contain control characters. {host!r} " http.client.InvalidURL: URL can't contain control characters. 'www.pyt hon.org' (found at least ' ')
Here is an example of how the error occurs.
import urllib.request url = 'http://www.python.org/ab cd' # ⛔️ http.client.InvalidURL: URL can't contain control characters. '/ab cd' (found at least ' ') with urllib.request.urlopen(url) as f: print(f.read(300))
Notice that the URL contains a space in the path.
# Replace the spaces in the URL with %20
URLs cannot contain spaces. When you encode a URL, spaces are usually replaced
with a plus + or with %20.
You str.replace method to
replace all spaces in the URL with %20 to resolve the error.
import urllib.request url = 'http://www.python.org/ab cd' url = url.replace(' ', '%20') with urllib.request.urlopen(url) as f: print(f.read(300))
If you print the value of the url variable, you will see that the space has
been replaced with %20.
url = 'http://www.python.org/ab cd' url = url.replace(' ', '%20') print(url) # 👉️ http://www.python.org/ab%20cd
You should only replace spaces with %20 if your URL contains spaces in its
path or query string.
In some cases, you might have to remove the spaces from the URL string by replacing them with empty strings.
import urllib.request url = 'http://www.pyt hon.org/' url = url.replace(' ', '') with urllib.request.urlopen(url) as f: print(f.read(300))
You might only have spaces (%20) in the path or query string of the URL, but
you will never have spaces in the domain, otherwise, the URL is invalid.
In this case, you should replace all spaces with an empty string.
If you print the value of the url variable, you will see that it doesn't
contain any spaces.
import urllib.request url = 'http://www.pyt hon.org/' url = url.replace(' ', '') print(url) # 👉️ http://www.python.org/
The str.replace() method takes the following parameters:
| Name | Description |
|---|---|
| old | The substring we want to replace in the string |
| new | The replacement for each occurrence of old |
| count | Only the first count occurrences are replaced (optional) |
# Using the urlparse and quote methods to encode the URL
You can also use the urlparse() and quote() methods from the urllib.parse
module to encode the URL.
import urllib.request from urllib.parse import urlparse, quote url = 'http://www.python.org/ab cd ef' parsed_url = urlparse(url) url = parsed_url.scheme + '://' + parsed_url.netloc + \ quote(parsed_url.path) if parsed_url.query: url += '?' + quote(parsed_url.query) print(url) # 👉️ http://www.python.org/ab%20cd%20ef
The URL string in the example contains spaces in its path, so we used the urlparse() method from the urllib.parse module.
The urlparse method takes a URL and parses it into six components.
from urllib.parse import urlparse, quote url = 'http://www.python.org/ab cd ef' parsed_url = urlparse(url) # ParseResult( # scheme='http', netloc='www.python.org', # path='/ab cd ef', params='', query='', fragment='') print(parsed_url)
| Attribute Name | Description |
|---|---|
scheme | returns the protocol, e.g. http or https |
netloc | returns the base URL. |
path | returns the hierarchical path. |
params | returns the parameter for the last path element. |
query | returns the query string. |
fragment | returns the fragment identifier #. |
The
quote
function takes a string and replaces special characters in the string using the
%xx escape.
The function is mainly used for quoting the path section of a URL.
from urllib.parse import urlparse, quote url = 'http://www.python.org/ab cd ef' parsed_url = urlparse(url) # 👇️ /ab%20cd%20ef print(quote(parsed_url.path))
The code sample uses the addition (+) operator to concatenate the URL components
and replaces the spaces in the path with %20.
import urllib.request from urllib.parse import urlparse, quote url = 'http://www.python.org/ab cd ef' parsed_url = urlparse(url) url = parsed_url.scheme + '://' + parsed_url.netloc + \ quote(parsed_url.path) if parsed_url.query: url += '?' + quote(parsed_url.query) print(url) # 👉️ http://www.python.org/ab%20cd%20ef
We also check if the URL has a query string, in which case we append it to the URL string and escape the spaces if necessary.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:

